
详解mysql中的字符集和校验规则

1几种常见字符集
在MySQL中,最常见的字符集有ASCII字符集、latin字符集、GB2312字符集、GBK字符集、UTF8字符集等,下面我们简单介绍下这些字符集:
ASCII字符集
这个字符集使用1个字节进行编码,一个字节具有8位,总共可以保存128个字符,具体的对应关系如下:
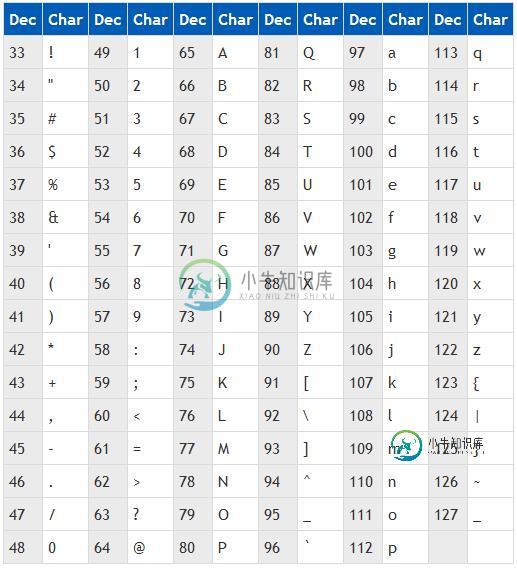
latin字符集
latin字符集一共可以保存256个字符,相比ASCII码,它又包含了128个西欧常用字符。
GB2312字符集
它包含了中文汉字、拉丁字符、希腊字符等,其中汉字占了大多数,有6763个,其他文字符号638个,而且它兼容ASCII字符。当对ASCII编码的时候,它采用1个字节进行编码,也就是128位,当对其他字符进行编码的时候,它采用2个字节进行编码。可以理解它是一种边长编码方式。
GBK字符集
该字符集是对GB2312字符集的一个扩充,它兼容GB2312字符集,一般采用两个字节进行编码。
UTF8字符集
它通常由1~4个字节来进行编码,根据使用字节的不同,也可以分为UTF8和utf8mb4两种,mb4的意思就是最多4个字节的意思,一般来讲UTF8采用三个字节进行编码,除此之外,还有utf16以及utf32,utf16使用2个或4个字节编码一个字符,utf32使用4个字节编码一个字符。
需要注意的是,一些emoji表情需要使用utf8mb4来表示。
2 mysql中支持的字符集
MySQL支持很多字符集,以我本地的字符集为例,使用show charset;命令查看当前服务器支持的字符集,结果如下:
mysql--dba_admin@127.0.0.1:(none) 22:46:48>>show charset; +----------+-----------------------------+---------------------+--------+ | Charset | Description | Default collation | Maxlen | +----------+-----------------------------+---------------------+--------+ | big5 | Big5 Traditional Chinese | big5_chinese_ci | 2 | | dec8 | DEC West European | dec8_swedish_ci | 1 | | cp850 | DOS West European | cp850_general_ci | 1 | | hp8 | HP West European | hp8_english_ci | 1 | | koi8r | KOI8-R Relcom Russian | koi8r_general_ci | 1 | | latin1 | cp1252 West European | latin1_swedish_ci | 1 | | latin2 | ISO 8859-2 Central European | latin2_general_ci | 1 | | swe7 | 7bit Swedish | swe7_swedish_ci | 1 | | ascii | US ASCII | ascii_general_ci | 1 | | ujis | EUC-JP Japanese | ujis_japanese_ci | 3 | | sjis | Shift-JIS Japanese | sjis_japanese_ci | 2 | | hebrew | ISO 8859-8 Hebrew | hebrew_general_ci | 1 | | tis620 | TIS620 Thai | tis620_thai_ci | 1 | | euckr | EUC-KR Korean | euckr_korean_ci | 2 | | koi8u | KOI8-U Ukrainian | koi8u_general_ci | 1 | | gb2312 | GB2312 Simplified Chinese | gb2312_chinese_ci | 2 | | greek | ISO 8859-7 Greek | greek_general_ci | 1 | | cp1250 | Windows Central European | cp1250_general_ci | 1 | | gbk | GBK Simplified Chinese | gbk_chinese_ci | 2 | | latin5 | ISO 8859-9 Turkish | latin5_turkish_ci | 1 | | armscii8 | ARMSCII-8 Armenian | armscii8_general_ci | 1 | | utf8 | UTF-8 Unicode | utf8_general_ci | 3 | | ucs2 | UCS-2 Unicode | ucs2_general_ci | 2 | | cp866 | DOS Russian | cp866_general_ci | 1 | | keybcs2 | DOS Kamenicky Czech-Slovak | keybcs2_general_ci | 1 | | macce | Mac Central European | macce_general_ci | 1 | | macroman | Mac West European | macroman_general_ci | 1 | | cp852 | DOS Central European | cp852_general_ci | 1 | | latin7 | ISO 8859-13 Baltic | latin7_general_ci | 1 | | utf8mb4 | UTF-8 Unicode | utf8mb4_general_ci | 4 | | cp1251 | Windows Cyrillic | cp1251_general_ci | 1 | | utf16 | UTF-16 Unicode | utf16_general_ci | 4 | | cp1256 | Windows Arabic | cp1256_general_ci | 1 | | cp1257 | Windows Baltic | cp1257_general_ci | 1 | | utf32 | UTF-32 Unicode | utf32_general_ci | 4 | | binary | Binary pseudo charset | binary | 1 | | geostd8 | GEOSTD8 Georgian | geostd8_general_ci | 1 | | cp932 | SJIS for Windows Japanese | cp932_japanese_ci | 2 | | eucjpms | UJIS for Windows Japanese | eucjpms_japanese_ci | 3 | +----------+-----------------------------+---------------------+--------+ 39 rows in set (0.00 sec)
可以看到,一共支持39中字符集,当然,不同的版本这个数字还有一些出入。在这39中字符集里面,需要我们记住的主要有以下几个:
+----------+-----------------------------+---------------------+--------+ | Charset | Description | Default collation | Maxlen | +----------+-----------------------------+---------------------+--------+ | latin1 | cp1252 West European | latin1_swedish_ci | 1 | | ascii | US ASCII | ascii_general_ci | 1 | | gb2312 | GB2312 Simplified Chinese | gb2312_chinese_ci | 2 | | gbk | GBK Simplified Chinese | gbk_chinese_ci | 2 | | utf8 | UTF-8 Unicode | utf8_general_ci | 3 | | utf8mb4 | UTF-8 Unicode | utf8mb4_general_ci | 4 | +----------+-----------------------------+---------------------+--------+
这里,我们暂时只需要知道他们最大长度包含几个字节就ok了。
3 校验规则
字符集的校验规则,指的是字符集比较大小的时候依据的准则,比如我们比较a和B的大小,如果不考虑大小写,那么a<B,如果考虑大小写,则a>B,也就是说,同一字符集,不同的比较规则,对某列数据的排序结果也就会产生不同。
MySQL中的字符校验规则可以通过show collation;语法来查看,如下:
mysql--dba_admin@127.0.0.1:(none) 23:00:36>>show collation; +-----------------------+----------+-----+---------+----------+---------+ | Collation | Charset | Id | Default | Compiled | Sortlen | +-----------------------+----------+-----+---------+----------+---------+ | big5_chinese_ci | big5 | 1 | Yes | Yes | 1 | | big5_bin | big5 | 84 | | Yes | 1 | | dec8_swedish_ci | dec8 | 3 | Yes | Yes | 1 | | dec8_bin | dec8 | 69 | | Yes | 1 | ........... | koi8r_general_ci | koi8r | 7 | Yes | Yes | 1 | | koi8r_bin | koi8r | 74 | | Yes | 1 | | latin1_german1_ci | latin1 | 5 | | Yes | 1 | | koi8u_general_ci | koi8u | 22 | Yes | Yes | 1 | | utf8_general_ci | utf8 | 33 | Yes | Yes | 1 | | utf8_bin | utf8 | 83 | | Yes | 1 | | utf8_unicode_ci | utf8 | 192 | | Yes | 8 | | utf8_icelandic_ci | utf8 | 193 | | Yes | 8 | | utf8_latvian_ci | utf8 | 194 | | Yes | 8 | | utf8_romanian_ci | utf8 | 195 | | Yes | 8 | | utf8_slovenian_ci | utf8 | 196 | | Yes | 8 | | utf8_polish_ci | utf8 | 197 | | Yes | 8 | | utf8_estonian_ci | utf8 | 198 | | Yes | 8 | +-----------------------+----------+-----+---------+----------+---------+ 195 rows in set (0.00 sec)
我们可以看到,结果中一共有195中比较规则,其中,每种字符集都包含自己默认的校验规则,我们简单解释一条:utf8_polish_ci以波兰语为规则进行对比,这个校验规则由三个部分组成,比较规则名称以与其关联的字符集的名称开头,utf8是指的是utf8字符集的比较规则,polish指的是波兰语,_ci指的是不区分大小写。
针对最后面的后缀,我们可以总结如下:
_ai 不区分重音
_as 区分重音
_ci case insensitive(不敏感) 不区分大小写
_cs case sensitive(敏感) 区分大小写
_bin 二进制
上面的结果中,我们还可以看到,一些校验规则的default列的值是yes,就代表这个校验规则是该字符集的默认校验规则。
4 服务器上的字符集和比较规则
mysql提供了两个系统变量来表示服务器级别的字符集和比较规则,一个是character_set_sever,另外一个是collation_server,我们可以查看它们的默认值:
mysql--dba_admin@127.0.0.1:(none) 23:12:28>>show variables like 'character_set_server' ; +----------------------+-------+ | Variable_name | Value | +----------------------+-------+ | character_set_server | utf8 | +----------------------+-------+ 1 row in set (0.00 sec) mysql--dba_admin@127.0.0.1:(none) 23:12:47>>show variables like 'collation_server'; +------------------+-----------------+ | Variable_name | Value | +------------------+-----------------+ | collation_server | utf8_general_ci | +------------------+-----------------+ 1 row in set (0.00 sec) mysql--dba_admin@127.0.0.1:(none) 23:12:57>>
在mysql中,字符集和校验规则分为4个级别,分别是服务器级别、数据库级别、表级别以及字段级别,这里我们分别举例子来看:
数据库级别 mysql 23:23:48>>create database yyz character set utf8 collate utf8_general_ci ; Query OK, 1 row affected (0.01 sec) 表级别 mysql 23:24:23>>create table yyz.yyz ( name varchar(10) ) charset gb2312 collate gb2312_chinese_ci; Query OK, 0 rows affected (0.04 sec) 字段级别 mysql 23:27:06>> mysql--dba_admin@127.0.0.1:(none) 23:27:06>>alter table yyz.yyz add num varchar(10) charset gbk collate gbk_chinese_ci; Query OK, 0 rows affected (0.11 sec) Records: 0 Duplicates: 0 Warnings: 0 查看结果 mysql 23:28:27>>show create table yyz.yyz; +-------+---------------------------------------------------------------------------------------------------------------------------------------------------+ | Table | Create Table | +-------+---------------------------------------------------------------------------------------------------------------------------------------------------+ | yyz | CREATE TABLE `yyz` ( `name` varchar(10) DEFAULT NULL, `num` varchar(10) CHARACTER SET gbk DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=gb2312 | +-------+---------------------------------------------------------------------------------------------------------------------------------------------------+ 1 row in set (0.00 sec)
由于字符集和比较规则是互相有联系的,如果我们只修改了字符集,比较规则也会跟着变化,如果只修改了比较规则,字符集也会跟着变化,具体规则如下:
只修改字符集,则比较规则将变为修改后的字符集默认的比较规则。
只修改比较规则,则字符集将变为修改后的比较规则对应的字符集。
还有下面4条需要记住:
- 对于数据库来说,如果创建和修改数据库的语句中没有致命字符集和比较规则,将使用服务器级别的字符集和比较规则作为数据库的字符集和比较规则
- 对于某个表来说,如果创建和修改表的语句中没有指明字符集和比较规则,将使用该表所在数据库的字符集和比较规则作为该表的字符集和比较规则;
- 对于某个列来说,如果在创建和修改的语句中没有指明字符集和比较规则,将使用该列所在表的字符集和比较规则作为该列的字符集和比较规则。
- 对于存储字符串的列,同一个表中的不同的列也可以有不同的字符集和比较规则
以上就是详解mysql中的字符集和校验规则的详细内容,更多关于mysql中的字符集和校验规则的资料请关注小牛知识库其它相关文章!
-
MySQL服务器能够支持多种字符集。可以使用SHOW CHARACTER SET语句列出可用的字符集: mysql> SHOW CHARACTER SET; +----------+-----------------------------+---------------------+--------+ | Charset | Description | Default collation
-
字符集是一套符号和编码。校对规则是在字符集内用于比较字符的一套规则。让我们使用一个假想字符集的例子来区别清楚。 假设我们有一个字母表使用了四个字母:‘A’、‘B’、‘a’、‘b’。我们为每个字母赋予一个数值:‘A’=0,‘B’= 1,‘a’= 2,‘b’= 3。字母‘A’是一个符号,数字0是‘A’的编码,这四个字母和它们的编码组合在一起是一个字符集。 假设我们希望比较两个字符串的值:‘A’和‘B’
-
10.10.1. Unicode字符集 10.10.2. 西欧字符集 10.10.3. 中欧字符集 10.10.4. 南欧与中东字符集 10.10.5. 波罗的海字符集 10.10.6. 西里尔字符集 10.10.7. 亚洲字符集 MySQL支持30多种字符集的70多种校对规则。字符集和它们的默认校对规则可以通过SHOW CHARACTER SET语句显示: mysql> SHOW CHARACT
-
本文向大家介绍详解Yii2.0 rules验证规则集合,包括了详解Yii2.0 rules验证规则集合的使用技巧和注意事项,需要的朋友参考一下 我最近也在学习Yii2的路上,那么今天也算个学习笔记吧! required : 必须值验证属性 email : 邮箱验证 match : 正则验证 url : 网址 captcha : 验证码 safe : 安全 compare : 比较 default
-
问题内容: 是否可以选择表中的整行并获得某种校验和?我正在寻找一种方法,告诉我的代码仅在更改了至少一条记录后才更新数据。从数据更改跟踪的角度来看,这将有助于我减少历史记录表中记录的许多更改。- 谢谢。 问题答案: 您可以结合使用和函数来为该行生成MD5校验和: 如果其中一列是可为空的,请确保将其包装在中,因为null会使结果也为null。 另请注意,这不是100%安全的。如果从一列中删除1个字符并
-
BetterValidate 校验规则 类校验 对于参数的校验,Lin 提供了类校验这种便捷,好用的方式,它会 对ctx.request.body(上下文请求体)、ctx.request.query(上下文请求query参数)、ctx.request.header(上下文请求头)、ctx.param(路由参数)这些参数进行统一校验 ,所以请保证你的参数名没有重复。 代码演示: class Regi