
Python进行数据提取的方法总结

准备工作
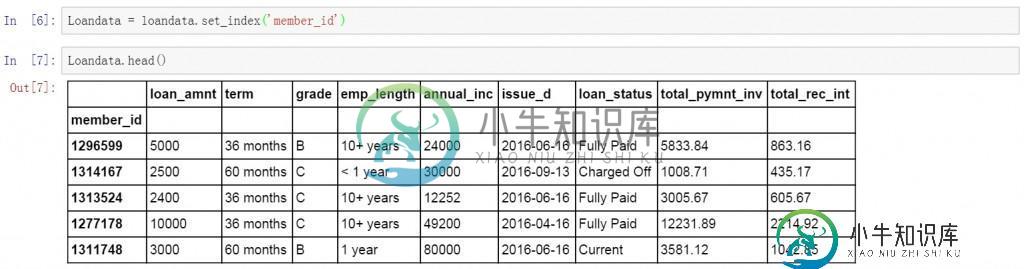
首先是准备工作,导入需要使用的库,读取并创建数据表取名为loandata。
import numpy as np
import pandas as pd
loandata=pd.DataFrame(pd.read_excel('loan_data.xlsx'))

设置索引字段
在开始提取数据前,先将member_id列设置为索引字段。然后开始提取数据。
Loandata = loandata.set_index('member_id')
按行提取信息
第一步是按行提取数据,例如提取某个用户的信息。下面使用ix函数对member_id为1303503的用户信息进行了提取。
loandata.ix[1303503]

按列提取信息
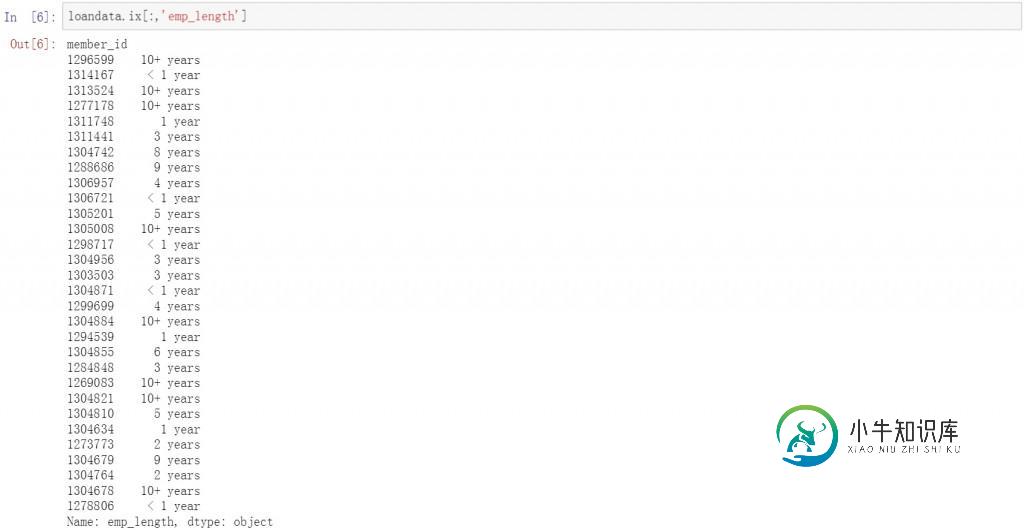
第二步是按列提取数据,例如提取用户工作年限列的所有信息,下面是具体的代码和提取结果,显示了所有用户的工作年龄信息。
loandata.ix[:,'emp_length']
按行与列提取信息
第三步是按行和列提取信息,把前面两部的查询条件放在一起,查询特定用户的特定信息,下面是查询member_id为1303503的用户的emp_length信息。
loandata.ix[1303503,'emp_length']

在前面的基础上继续增加条件,增加一行同时查询两个特定用户的贷款金额信息。具体代码和查询结果如下。结果中分别列出了两个用户的代码金额。
loandata.ix[[1303503,1298717],'loan_amnt']

在前面的代码后增加sum函数,对结果进行求和,同样是查询两个特定用户的贷款进行,下面的结果中直接给出了贷款金额的汇总值。
loandata.ix[[1303503,1298717],'loan_amnt'].sum()

除了增加行的查询条件以外,还可以增加列的查询条件,下面的代码中查询了一个特定用户的贷款金额和年收入情况,结果中分别显示了这两个字段的结果。
loandata.ix[1303503,['loan_amnt','annual_inc']]

多个列的查询也可以进行求和计算,在前面的代码后增加sum函数,对这个用户的贷款金额和年收入两个字段求和,并显示出结果。
loandata.ix[1303503,['loan_amnt','annual_inc']].sum()

提取特定日期的信息
数据提取中还有一种很常见的需求就是按日期维度对数据进行汇总和提取,如按月,季度的汇总数据提取和按特定时间段的数据提取等等。
设置索引字段
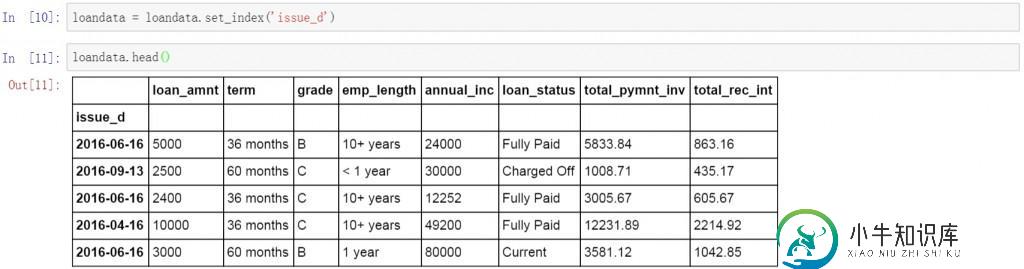
首先将索引字段改为数据表中的日期字段,这里将issue_d设置为数据表的索引字段。按日期进行查询和数据提取。
loandata = loandata.set_index('issue_d')
按日期提取信息
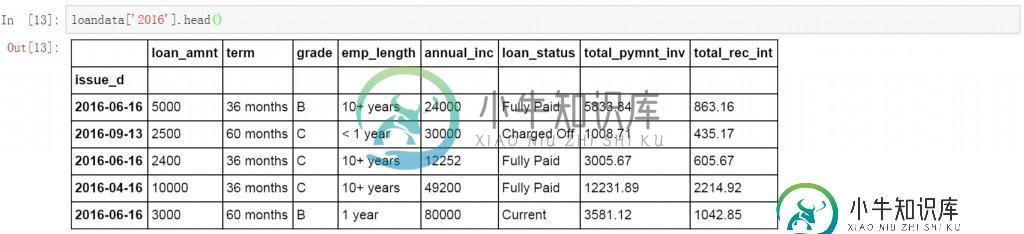
下面的代码查询了所有2016年的数据。
loandata['2016']
在前面代码的基础上增加月份,查询所有2016年3月的数据。
loandata['2016-03']
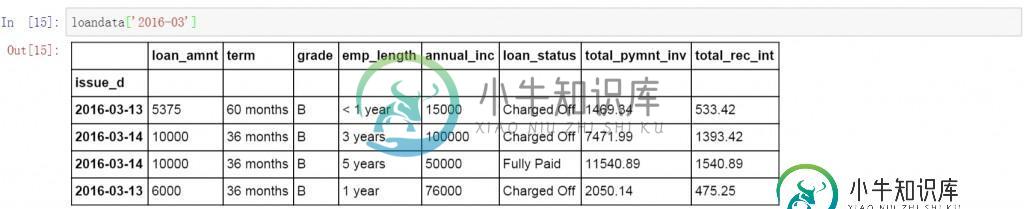
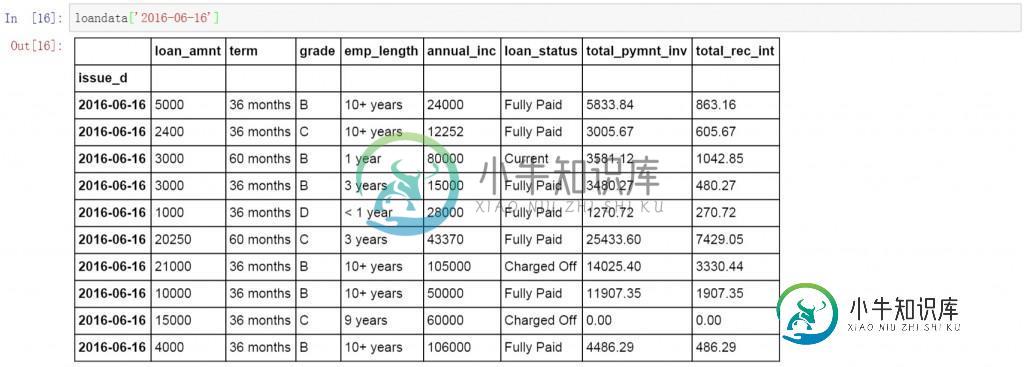
继续在前面代码的基础上增加日期,查询所有2016年6月16日的数据。
loandata['2016-06-16']
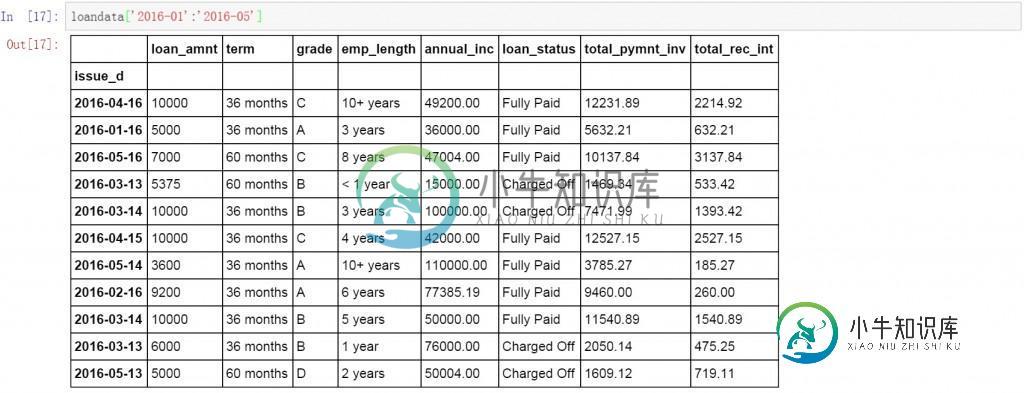
除了按单独日期查询以外,还可以按日期段进行数据查询,下面的代码中查询了所有2016年1月至5月的数据。下面显示了具体的查询结果,可以发现数据的日期都是在1-5月的,但是按日期维度显示的,这就需要我们对数据按月进行汇总。
loandata['2016-01':'2016-05']
按日期汇总信息
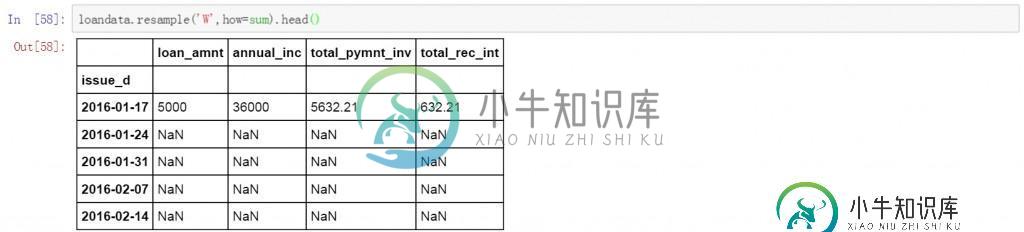
Pandas中的resample函数可以完成日期的聚合工作,包括按小时维度,日期维度,月维度,季度及年的维度等等。下面我们分别说明。首先是按周的维度对前面数据表的数据进行求和。下面的代码中W表示聚合方式是按周,how表示数据的计算方式,默认是计算平均值,这里设置为sum,进行求和计算。
loandata.resample('W',how=sum).head(10)
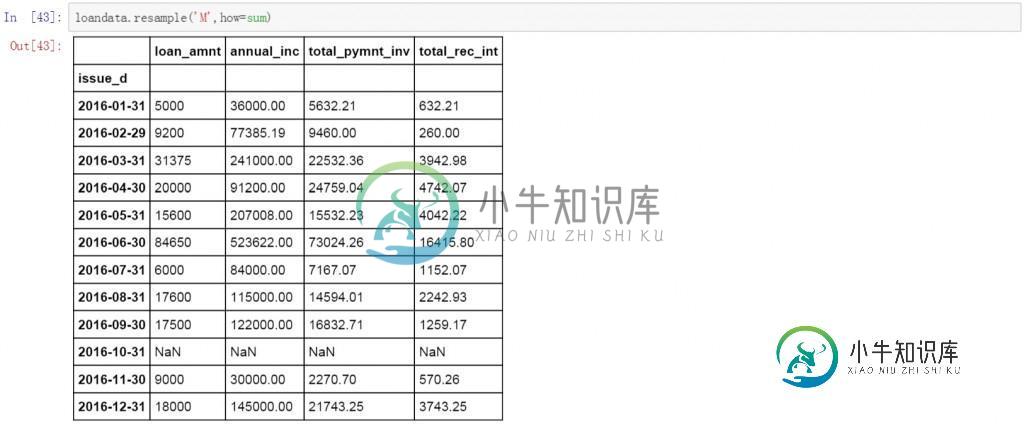
将W改为M,数据变成了按月聚合的方式。计算方式依然是求和。这里需要说明的是resample函数会显示出所有连续的时间段,例如前面按周的聚合操作会显示连续的周日期,这里的按月操作则会在结果中显示连续的月,如果某个时间段没有数据,会以NaN值显示。
loandata.resample('M',how=sum)
将前面代码中的M改为Q,则为按季度对数据进行聚合,计算方式依然为求和。从下面的数据表中看,日期显示的都是每个季度的最后一天,如果希望以每个季度的第一天显示,可以改为QS。
loandata.resample('Q',how=sum)

将前面代码中的Q改为A,就是按年对数据进行聚合,计算方式依然为求和。
loandata.resample('A',how=sum)

前面的方法都是对整个数据表进行聚合和求和操作,如果只需要对某一个字段的值进行聚合和求和,可以在数据表后增加列的名称。下面是将贷款金额字段按月聚合后求和,并用0填充空值。
loandata['loan_amnt'].resample('M',how=sum).fillna(0)

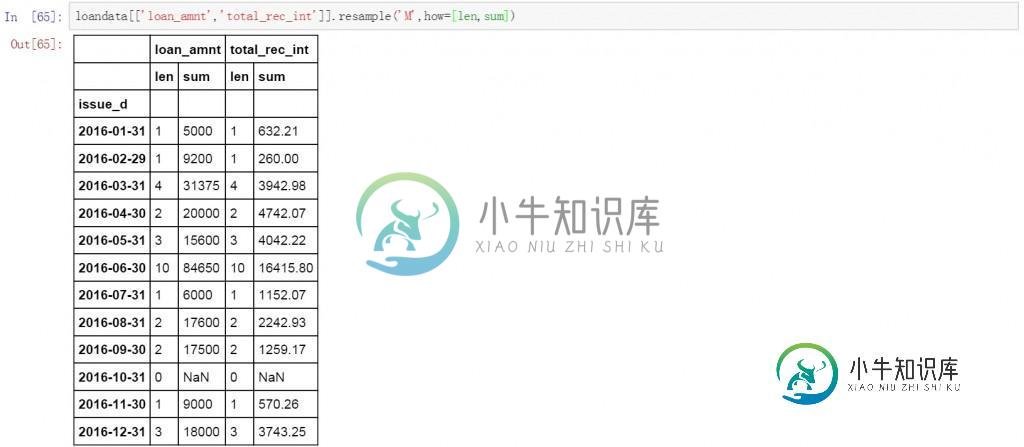
在前面代码的基础上再增加一个数值字段,并且在后面的计算方式中增加len用来计数。在下面的结果中分别对贷款金额和利息收入按月聚合,并进行求和和计数计算
loandata[['loan_amnt','total_rec_int']].resample('M',how=[len,sum])
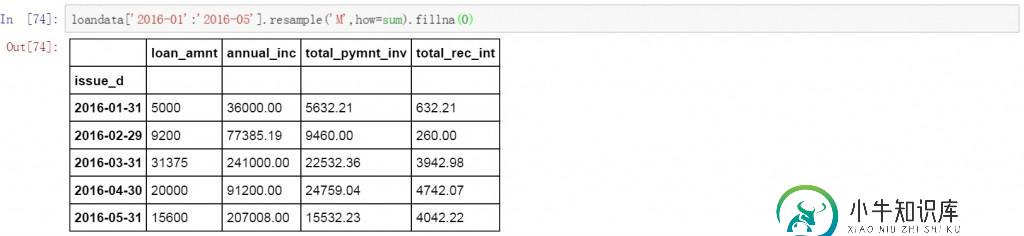
有时我们需要只对某一时间段的数据进行聚合和计算,下面的代码中对2016年1月至5月的数据按月进行了聚合,并计算求和。用0填充空值。
loandata['2016-01':'2016-05'].resample('M',how=sum).fillna(0)
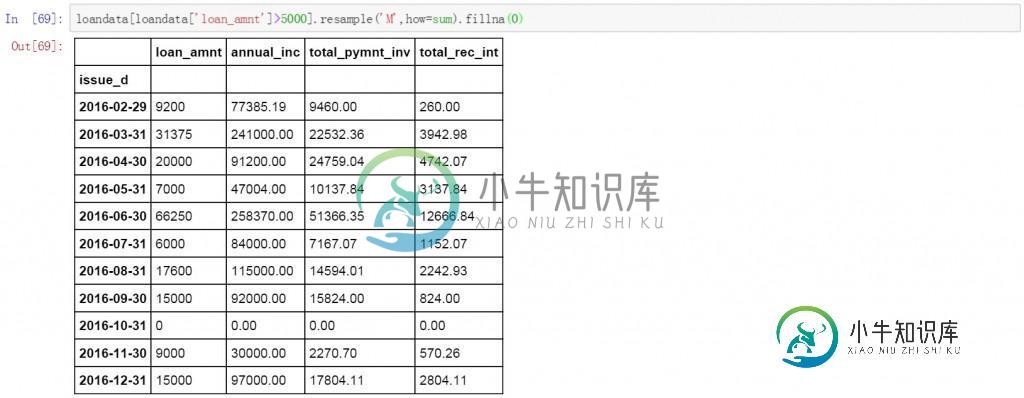
或者只对某些符合条件的数据进行聚合和计算。下面的代码中对于贷款金额大于5000的按月进行聚合,并计算求和。空值以0进行填充。
loandata[loandata['loan_amnt']>5000].resample('M',how=sum).fillna(0)
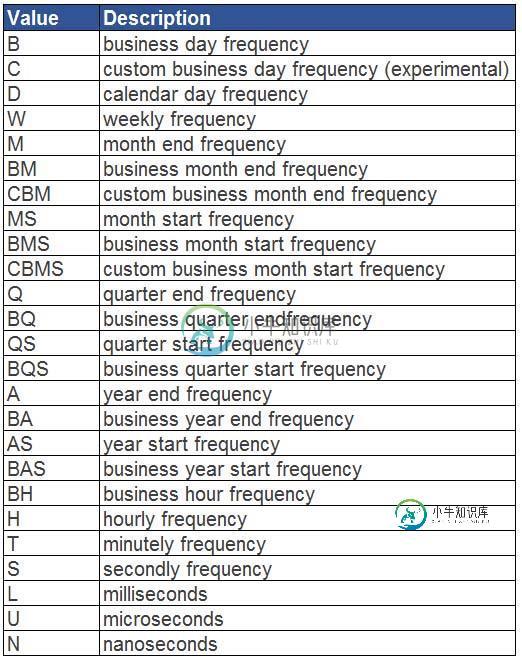
除了按周,月,季度和年以外,resample函数还可以按以下方式对日期进行聚合。
下面给出了具体的对应表和说明。
总结
以上就是利用python按特定的维度或条件对数据进行提取的全部内容,希望本文的内容对大家学习使用Python能有所帮助。
-
本文向大家介绍python提取包含关键字的整行数据方法,包括了python提取包含关键字的整行数据方法的使用技巧和注意事项,需要的朋友参考一下 问题描述: 如下图所示,有一个近2000行的数据表,需要把其中含有关键字‘颈廓清术,中央组(VI组)'的数据所在行都都给抽取出来,且提取后的表格不能改变原先的顺序。 问题分析: 一开始想用excel的筛选功能,但是发现只提供单列筛选,由于关键词在P,S,V
-
页面解析和数据提取 一般来讲对我们而言,爬虫需要抓取的是某个网站或者某个应用的内容,提取有用的数据。响应内容一般分为两种,非结构化的数据 和 结构化的数据。 结构化数据:先有结构、再有数据 非结构化数据:先有数据,再有结构, 不同类型的数据,我们需要采用不同的方式来处理。 结构化的数据处理 HTML 文件 正则表达式 XPath CSS选择器 JSON 文件 JsonPath JSON 模块转化成
-
本文向大家介绍python使用xslt提取网页数据的方法,包括了python使用xslt提取网页数据的方法的使用技巧和注意事项,需要的朋友参考一下 1、引言 在Python网络爬虫内容提取器一文我们详细讲解了核心部件:可插拔的内容提取器类gsExtractor。本文记录了确定gsExtractor的技术路线过程中所做的编程实验。这是第一部分,实验了用xslt方式一次性提取静态网页内容并转换成xml
-
本文向大家介绍Python检测数据类型的方法总结,包括了Python检测数据类型的方法总结的使用技巧和注意事项,需要的朋友参考一下 我们在用python进行程序开发的时候,很多时候我们需要检测一下当前的变量的数据类型。比如需要在使用字符串操作函数之前先检测一下当前变量是否是字符串。下面小编给大家分享一下在python中如何检测数据类型 首先我们打开CMD控制台,进入到python环境,然后声明一个
-
本文向大家介绍php 获取文件行数的方法总结,包括了php 获取文件行数的方法总结的使用技巧和注意事项,需要的朋友参考一下 stream_get_line获取文件行数 feof和fgets获取文件行数 count获取文件行数 第三种方式因为要保存文件的内容,效率上会很差,这里小编推荐大家使用第一种和第二种方法。 感谢阅读,希望能帮助到大家,谢谢大家对本站的支持!
-
本文向大家介绍对python .txt文件读取及数据处理方法总结,包括了对python .txt文件读取及数据处理方法总结的使用技巧和注意事项,需要的朋友参考一下 1、处理包含数据的文件 最近利用Python读取txt文件时遇到了一个小问题,就是在计算两个np.narray()类型的数组时,出现了以下错误: 作为一个Python新手,遇到这个问题后花费了挺多时间,在网上找了许多大神们写的例子,最后