
Spring Data JPA 简单查询--方法定义规则(详解)

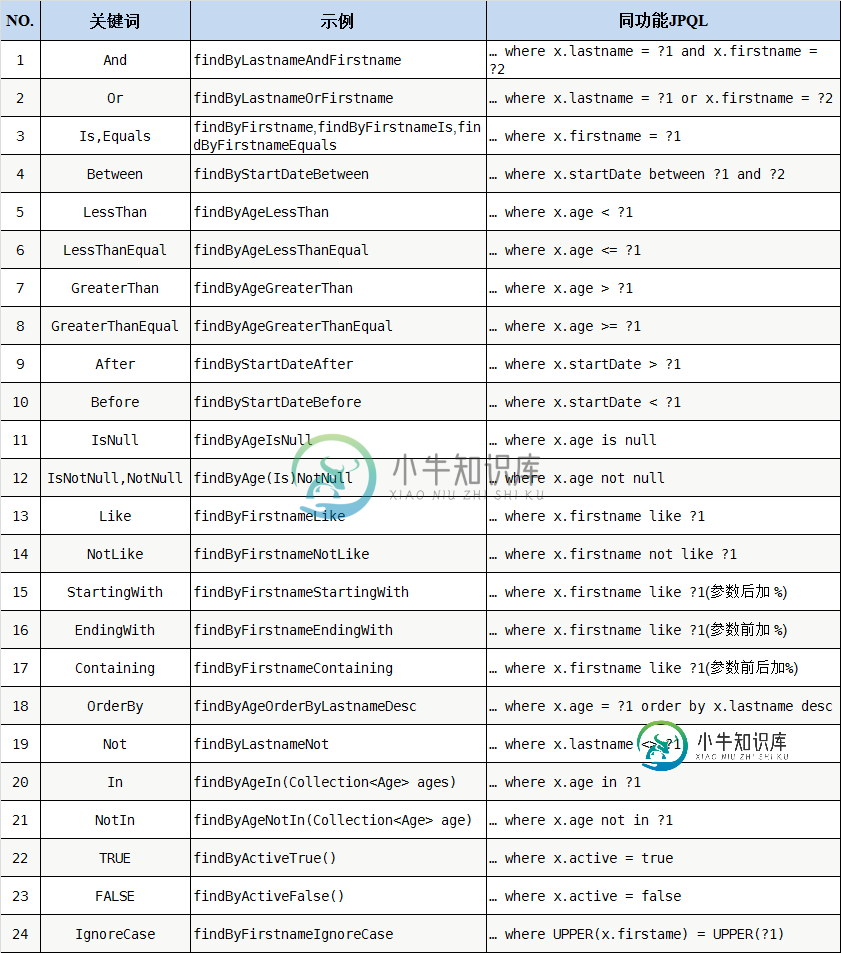
一、常用规则速查
1 And 并且
2 Or 或
3 Is,Equals 等于
4 Between 两者之间
5 LessThan 小于
6 LessThanEqual 小于等于
7 GreaterThan 大于
8 GreaterThanEqual 大于等于
9 After 之后(时间) >
10 Before 之前(时间) <
11 IsNull 等于Null
12 IsNotNull,NotNull 不等于Null
13 Like 模糊查询。查询件中需要自己加 %
14 NotLike 不在模糊范围内。查询件中需要自己加 %
15 StartingWith 以某开头
16 EndingWith 以某结束
17 Containing 包含某
18 OrderBy 排序
19 Not 不等于
20 In 某范围内
21 NotIn 某范围外
22 True 真
23 False 假
24 IgnoreCase 忽略大小写
二、Spring Data 解析方法名--规则说明
1、规则描述
按照Spring data 定义的规则,查询方法以find|read|get开头(比如 find、findBy、read、readBy、get、getBy),涉及条件查询时,条件的属性用条件关键字连接,要注意的是:条件属性首字母需大写。框架在进行方法名解析时,会先把方法名多余的前缀截取掉,然后对剩下部分进行解析。
如果方法的最后一个参数是 Sort 或者 Pageable 类型,也会提取相关的信息,以便按规则进行排序或者分页查询。
2、举例说明
比如 findByUserAddressZip()。框架在解析该方法时,首先剔除 findBy,然后对剩下的属性进行解析,详细规则如下(此处假设该方法针对的域对象为 AccountInfo 类型):
先判断 userAddressZip (根据 POJO 规范,首字母变为小写,下同)是否为 AccountInfo 的一个属性,如果是,则表示根据该属性进行查询;如果没有该属性,继续第二步;
从右往左截取第一个大写字母开头的字符串(此处为 Zip),然后检查剩下的字符串是否为 AccountInfo 的一个属性,如果是,则表示根据该属性进行查询;如果没有该属性,则重复第二步,继续从右往左截取;最后假设 user 为 AccountInfo 的一个属性;
接着处理剩下部分( AddressZip ),先判断 user 所对应的类型是否有 addressZip 属性,如果有,则表示该方法最终是根据 "AccountInfo.user.addressZip" 的取值进行查询;否则继续按照步骤 2 的规则从右往左截取,最终表示根据 "AccountInfo.user.address.zip" 的值进行查询。
可能会存在一种特殊情况,比如 AccountInfo 包含一个 user 的属性,也有一个 userAddress 属性,此时会存在混淆。读者可以明确在属性之间加上 "_" 以显式表达意图,比如 "findByUser_AddressZip()" 或者 "findByUserAddress_Zip()"。(强烈建议:无论是否存在混淆,都要在不同类层级之间加上"_" ,增加代码可读性)
三、一些情况
1、当查询条件为null时。
举例说明如下:
实体定义:对于一个客户实体Cus,包含有name和sex,均是String类型。
查询方法定义:List<Cus> findByNameAndSex(String name,String sex);
使用时:dao.findByNameAndSex(null, "男");
后台生成sql片断:where (cus0_.name is null) and cus0_.sex=?
结论:当查询时传值是null时,数据库中只有该字段是null的记录才符合条件,并不是说忽略这个条件。也就是说,这种查询方式,只适合于明确查询条件必须传的业务,对于动态查询(条件多少是动态的,例如一般的查询列表,由最终用户使用时决定输入那些查询条件),这种简单查询是不能满足要求的。
2、排序
List<Cus> findBySexOrderByName(String sex); //名称正序(正序时,推荐此方式,简单) List<Cus> findBySexOrderByNameAsc(String sex); //名称正序(效果同上) List<Cus> findBySexOrderByNameDesc(String sex); //名称倒序
以上这篇Spring Data JPA 简单查询--方法定义规则(详解)就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持小牛知识库。
-
查询方法的结果可以通过关键字first或者top来限制,它们可以交替使用。在top/firest后添加数字来表示返回最大的结果数。如果没有数字,则默认假定1作为结果大小。 示例10。用Top和First查询限制结果大小 User findFirstByOrderByLastnameAsc(); User findTopByOrderByAgeDesc(); Page<
-
基础Spring Data repository内置的查询生成器机制对于创建实体仓库的约束查询是有用的,它会从方法名中去掉find…By,read…By,query…By,count…By和get…By这些前缀并解析剩下的内容.这些前缀还能包含更多的表达式例如Distinct,设置一个distinct标志并在查询中创建它,然后第一个By的动作就像一个分隔符来表明查询实际标准的开始。最基本的方式你可
-
通过方法名,Spring Data有两种方式获得开发者的查询意图。一是直接解析方法名,二是使用@Query创建的查询。那么到底使用哪种方式呢?Spring Data有一套策略来决定创建的查询。
-
3.4. 定义查询方法 repository 代理有两种方法去查询。一种是根据方法名或者自定义查询,可用的选项取决于实际的商店。然而,根据相应的策略来决定实际SQL的创建,让我们看看选择项吧。 3.4.1. 查询查找策略 以下策略可供查询库基础设施来解决。您可以配置策略名称空间通过 query-lookup-strategy属性的XML配置或通过queryLookupStrategy启用的属性${
-
本文向大家介绍ANTLR 简单规则,包括了ANTLR 简单规则的使用技巧和注意事项,需要的朋友参考一下 示例 Lexer规则定义令牌类型。它们的名称必须以大写字母开头,以区别于解析器规则。 基本语法: 语法 含义 A 匹配名称为lexer的规则或片段 A A B 比赛A之后B (A|B) 匹配A或B 'text' 匹配文字“文本” A? 匹配A零或一次 A* 匹配A零次或多次 A+ 匹配A一次或多
-
以下策略可用于仓库基础结构来解决查询。你可以在XML配置中的命名空间通过query-lookup-strategy属性来配置策略或者在JAVA配置中通过Enable${store}Repositories声明queryLookupStrategy属性。有些策略可能对于特别的datastores并不支持。 CREATE 从查询方法名来尝试构建一个特别的数据查询。一般的方法都是从方法名称中移除已知设定