
从CentOS安装完成到生成词云python的实例

前言
人生苦短,我用python。学习python怎么能不搞一下词云呢是不是(ง •̀_•́)ง
于是便有了这篇边实践边记录的笔记。
环境:VMware 12pro + CentOS7 + Python 2.7.5
安装系统
之前一直用的是win10子系统,现在试试CentOS,CentOS官网下载最新系统dvd版 安装到VMware 12pro。网上很多教程。例如这个链接。等待安装完成后开始。
第一个命令
用Ubuntu的时候没有的命令会提示你安装,感觉很简单的事。但是到CentOS上却变得很头痛。
打开终端在执行以下命令安装python-pip时提示。
sudo yum install python-pip 没有可用软件包 python-pip。
google了一下说是这个包在EPEL源里,要添加EPEL源才可以。
执行下面两个命令就安装好了。
yum install epel-release.noarch yum install python-pip
python库安装
接下来安装一个词云wordcloud
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple wordcloud 截取部分提示错误信息 unable to execute gcc: No such file or directory error: command 'gcc' failed with exit status 1 连gcc都没有(ง •̀_•́)ง。先安装gcc yum install gcc
gcc装完后继续安装wordcloud!又报了下面的错误
_posixsubprocess.c:3:20: 致命错误:Python.h:没有那个文件或目录 于是需要先安装python-devel sudo yum install python-devel #注意这里不是python-dev
CentOS 下叫做 python-devel,Ubuntu 下还是叫做 python-dev。
wordcloud安装完毕!
代码
生成词云一份代码,并且随便找一份英文(我在ChinaDaily找的文章 Recruiters starting to employ social media 放到 txt/word.txt中
# -*- coding: UTF-8 -*- import matplotlib # Force matplotlib to not use any Xwindows backend. #matplotlib.use('Agg') from wordcloud import WordCloud textfile = open(u'txt/word.txt','r').read() wordcloud = WordCloud(background_color="white",width=800, height=600, margin=5).generate(textfile) # width,height,margin可以设置图片属性 # generate 可以对全部文本进行自动分词,但是它对中文支持不好 #background_color参数为设置背景颜色,默认颜色为黑色 wordcloud.to_file('word.png')
执行命令运行 python clouddemo.py 报错提示
SyntaxError: Non-ASCII character '\xe5' in file clouddemo.py on line 6, but no encoding declared; see http://www.python.org/peps/pep-0263.html for details
原因如下
Python默认是以ASCII作为编码方式的,如果在Python源码中包含了中文(或者其他非英语系的语言),此时即使你把自己编写的Python源文件以UTF-8格式保存,但实际上,这依然是不行的。
解决办法很简单,只要在文件开头加入下面代码;指定文件的编码格式为utf-8。上面的代码我已经加好了(。・`ω´・)。
# -*- coding: UTF-8 -*-
编码问题解决了。接下来重新运行。
还是报错!!!
ImportError: No module named Tkinter
首先yum list installed | grep ^tk
查看是否存在相应模块,如果不存在则通过yum install tkinter 和yum install -y tk-devel下载相应模块。
重新执行命令提示下一个错误
tkinter.TclError: no display name and no $DISPLAY environment variable
虽然一波N折,但是最后还是成功了!!!看看源代码目录下的词云图!
效果图如下:
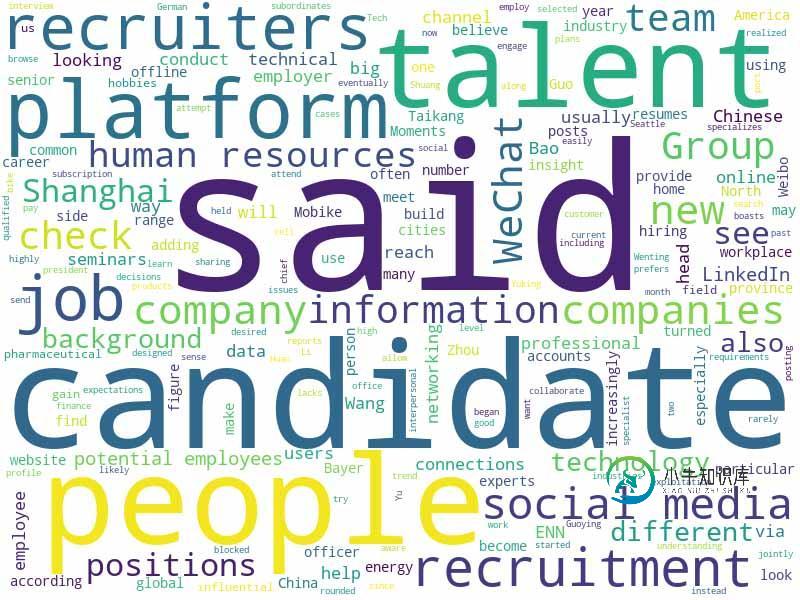
以上这篇从CentOS安装完成到生成词云python的实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持小牛知识库。
-
安装完毕后,会出现相应的安装完毕界面: 然后点击“完成”,即可启动默认勾选了的Notepad++了。 至此,Notepad++安装完毕。
-
本文向大家介绍Python基于jieba, wordcloud库生成中文词云,包括了Python基于jieba, wordcloud库生成中文词云的使用技巧和注意事项,需要的朋友参考一下 代码如下 准备文件:需要在当前程序运行目录准备一个中文文本文件NSFC.txt。 程序运行后,完成对NSFC.txt文件中的中文统计,并输出图形文件展示词云。 图片效果如下: 以上就是本文的全部内容,希望对大家的
-
问题内容: 所以我基本上是在一个项目中,计算机从单词列表中提取一个单词,然后为用户弄乱它。只有一个问题:我不想一直在列表中写很多单词,所以我想知道是否有一种方法可以导入很多随机单词,所以即使我也不知道它是什么,并且那我也可以玩游戏吗?这是整个程序的编码,我只输入了6个字: 问题答案: 如果您重复执行此操作,我将在本地下载它并从本地文件中提取。* nix用户可以使用。 例: 从远程字典中提取 如果您
-
本文向大家介绍利用Python爬取微博数据生成词云图片实例代码,包括了利用Python爬取微博数据生成词云图片实例代码的使用技巧和注意事项,需要的朋友参考一下 前言 在很早之前写过一篇怎么利用微博数据制作词云图片出来,之前的写得不完整,而且只能使用自己的数据,现在重新整理了一下,任何的微博数据都可以制作出来,一年一度的虐汪节,是继续蹲在角落默默吃狗粮还是主动出击告别单身汪加入散狗粮的行列就看你啦,