
MySQL 8.0.23中复制架构从节点自动故障转移的问题

接触MGR有一段时间了,MySQL 8.0.23的到来,基于MySQL Group Replicaion(MGR)的高可用架构又提供了新的架构思路。
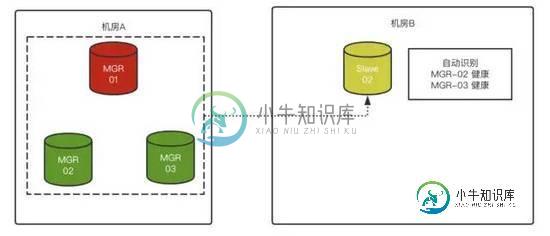
灾备机房的slave,如何更好的支持主机房的MGR?
MGR 到底可以坏几个节点?
这次我就以上2个问题,和大家简单聊下MGR的一些思想和功能。
一、MySQL Group Relication 成员数量的容错能力
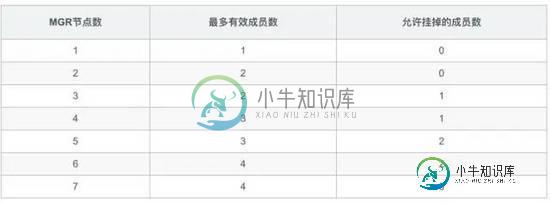
上面的表格相信大家不会陌生了,我经常在面试里会问:“4个节点的MGR,最多坏几个呢?” ,多数人回答:“最多坏1个,坏2个就脑裂不能工作了。”
那我们来看看MGR的处理方式,是不是这个答案呢?
1)我们具有一个4节点MGR
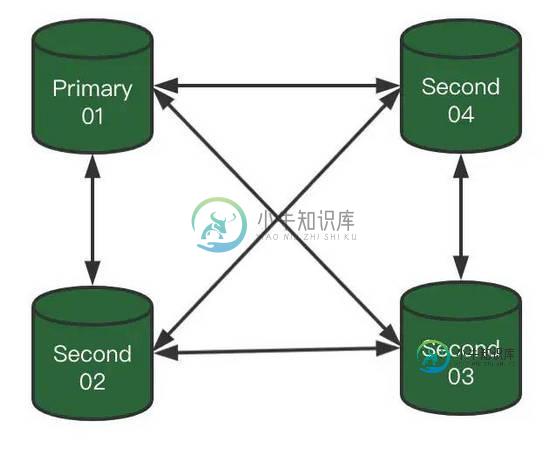
埋一个问题:这个图一看就是Single模式,但箭头不是单向,是不是画错了?
2)此时,Second-04突然宕机了,那么MGR集群会成什么样子呢?
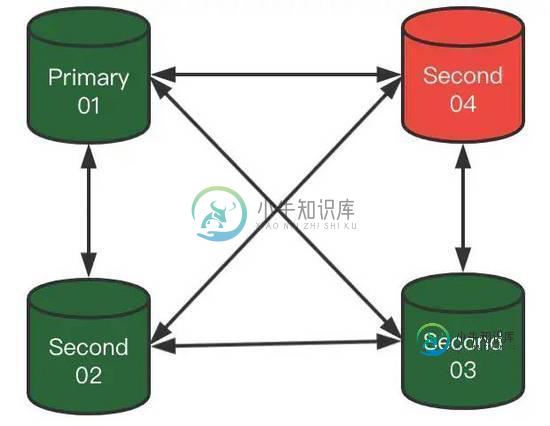
集群此时状态会变成:
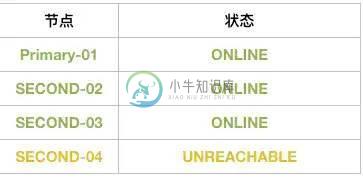
- 每个节点会固定时间交换各自信息。
- 当没有收到Second-04节点信息后,其他成员会等待5秒。
- 这个期间Second-04肯定没有发出来消息,于是健康成员认为Second-04是可疑状态,标记UNREACHABLE状态。
- 然后健康成员按照参数:group_replication_member_expel_timeout,继续等待(此时Second-04依然是UNREACHABLE状态)。
- 当超过了group_replication_member_expel_timeout时间,健康成员就把Second-04节点驱逐出集群了。
那么重点来了,敲黑板
在Second-04,没有被驱逐出去时:
此时集群是(4节点-3健康-1坏),这个期间如果继续坏1个节点,那么集群变成(4节点-2健康-2坏),集群没有满足多数原则,每个节点都无法写入了(除非人工干预,强制指定集群成员List)。

在Second-04,被驱逐出去后:
此时集群是(3节点-3健康-0坏),4节点集群退化成3节点健康集群了,这个时候,集群依然可以继续坏一个节点,变成(3节点-2健康-1坏)

所以4节点集群是否可以坏1个还是2个,具体要看集群处理过程哪个阶段哦。
PS:
我们说说刚才埋的问题:这个图一看就是Single模式,但箭头不是单向,是不是画错了?
首先Single模式,Second节点默认是不能写入的,但只是由于Second节点的super-read-only开启了。
将Second节点super-read-only = 0,Second节点可以正常写入,并可以同步其他节点(Primary和其他Second),传输还是基于Paxos协议的。
跑个火车:Second节点反向同步其他节点,是不会经过冲突检测阶段(理论效率要高于多写模式),没有验证,大家有兴趣可以研究下。
二、 Asynchronous Connection Failover
MySQL 8.0.22,推出了异步复制连接故障转移,很多朋友都发文做了介绍,这里我只简单描述下:
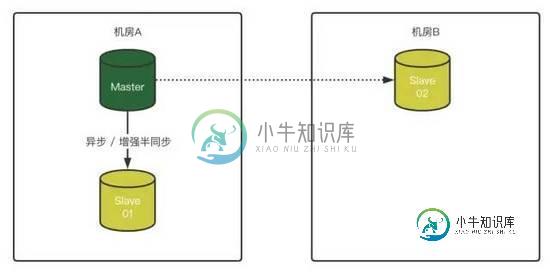
1)同机房1主1从,异地机房单独放一个slave节点
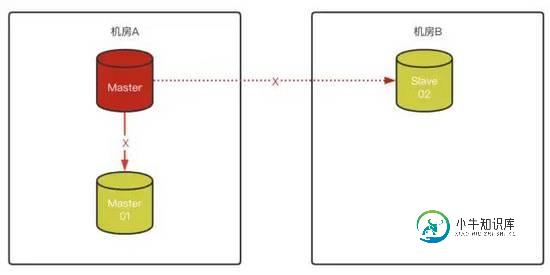
2)Master 故障,将Slave-01变成Master,Slave-02无法连接原Master
3)如果对Slave-02配置了“异步连接故障转移配置”,那么Slave-02在识别原Master故障后,会自动尝试按照预先定义好的配置,与原Slave-01(新Master)建立复制关系:
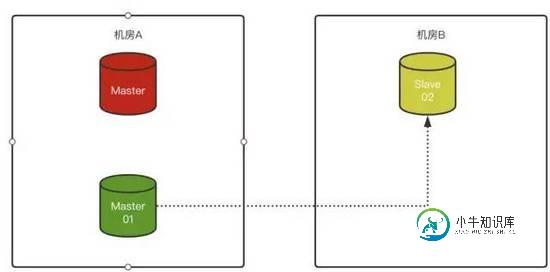
这个功能非常好,引用三方工具(例如MHA的修复主从关系)已经可以被MySQL原生功能代替了。
但我测试完,又有了几点疑虑:
1. “异步”复制故障转移,难道不支持半同步架构?不能确保数据不丢失,还是无法完全代替MHA啊?
答:其实是支持增强半同步的。
2. 要预先配置故障转移的Master List,那么A机房架构变更,还要去维护机房B的节点吗?
答:是的。
3. 如果A机房是MGR,那么MGR的节点(master)异常,但服务没有关,可以访问,机房B节点岂不是一直连接着?
答:是的
然后,MySQL 8.0.23发布了,带来了此功能的增强:
Slave可以支持MGR集群,并且可以动态识别MGR成员,来建立Master-Slave关系了
最后让我们跑一圈:
1)首先我们有3节点的MGR集群,版本8.0.22(异步连接故障转移,是作用在Slave的IO Thread上的,所以Slave是8.0.23版本就成)
+----------------------------+-------------+--------------+-------------+---------------------+ | now(6) | member_host | member_state | member_role | VIEW_ID | +----------------------------+-------------+--------------+-------------+---------------------+ | 2021-01-22 13:41:27.902251 | mysql-01 | ONLINE | SECONDARY | 16112906030396799:9 | | 2021-01-22 13:41:27.902251 | mysql-02 | ONLINE | PRIMARY | 16112906030396799:9 | | 2021-01-22 13:41:27.902251 | mysql-03 | ONLINE | SECONDARY | 16112906030396799:9 | +----------------------------+-------------+--------------+-------------+---------------------+
2)然后我们在独立Slave节点,指定Slave上“对Master连接故障转移列表”
SELECT asynchronous_connection_failover_add_managed('ch1', 'GroupReplication', 'aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaa1', 'mysql-02', 3306, '', 80, 60);
简单解释下参数:
ch1:chanel名称
GroupReplication:强制写死的参数,目前支持MGR集群
aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaa1:MGR组名(参数 group_replication_group_name)
mysql-02:MGR成员之一
80:Primary节点的优先级(0-100),多主相同优先级则随机选择节点充当master。
60:Second节点的优先级(0-100),基本就是给Single模式准备的
3)为Slave指定复制通道信息
CHANGE REPLICATION SOURCE TO SOURCE_USER='rpl_user', SOURCE_PASSWORD='123456', SOURCE_HOST='mysql-02',SOURCE_PORT=3306,SOURCE_RETRY_COUNT=2,SOURCE_CONNECTION_AUTO_FAILOVER=1,SOURCE_AUTO_POSITION=1 For CHANNEL 'ch1';
4)启动Slave,并查看“连接的可转移列表”
不开启io thread,是不会自动识别MGR成员的。并且复制用户
rpl_user需要在MGR节点对performance_schema具有select权限
start slave; SELECT * FROM performance_schema.replication_asynchronous_connection_failover; +--------------+----------+------+-------------------+--------+--------------------------------------+ | CHANNEL_NAME | HOST | PORT | NETWORK_NAMESPACE | WEIGHT | MANAGED_NAME | +--------------+----------+------+-------------------+--------+--------------------------------------+ | ch1 | mysql-01 | 3306 | | 60 | aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaa1 | | ch1 | mysql-02 | 3306 | | 80 | aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaa1 | | ch1 | mysql-03 | 3306 | | 60 | aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaa1 | +--------------+----------+------+-------------------+--------+--------------------------------------+
5)然后我们将mysql-02 stop group_replication(不是关闭服务),
Slave列表自动淘汰mysql-02,重新与其他节点建立连接-- mysql-02(Primary):
stop group_replication;
-- Slave:
SELECT * FROM performance_schema.replication_asynchronous_connection_failover;
+--------------+----------+------+-------------------+--------+--------------------------------------+
| CHANNEL_NAME | HOST | PORT | NETWORK_NAMESPACE | WEIGHT | MANAGED_NAME |
+--------------+----------+------+-------------------+--------+--------------------------------------+
| ch1 | mysql-01 | 3306 | | 80 | aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaa1 |
| ch1 | mysql-03 | 3306 | | 60 | aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaa1 |
+--------------+----------+------+-------------------+--------+--------------------------------------+
show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: mysql-01
Master_User: rpl_user
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mybinlog.000003
Read_Master_Log_Pos: 4904
Relay_Log_File: mysql-01-relay-bin-ch1.000065
Relay_Log_Pos: 439
Relay_Master_Log_File: mybinlog.000003
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
...
至此,配置完成。后面MGR节点增、减,Slave都可以自动维护这个列表。不贴其他用例了。
PS:
如果想手工切换Slave已建立的Master节点(Primary)连接到其他节点(Second)上,只需要删除“复制连接的可转移列表”,重新调整Second优先级加回即可。
-- 删除配置
SELECT asynchronous_connection_failover_delete_managed('ch1', 'aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaa1');
-- 重新添加,调整Second优先级高于Primary
SELECT asynchronous_connection_failover_add_managed('ch1', 'GroupReplication', 'aaaaaaaaaaaa-aaaa-aaaa-aaaaaaaaaaa1', 'mysql-03', 3306, '', 60, 80);
参考连接:
https://mysqlhighavailability.com/automatic-asynchronous-replication-connection-failover/
https://my.oschina.net/u/4591256/blog/4813037
https://dev.mysql.com/doc/refman/8.0/en/replication-functions-source-list.html
到此这篇关于MySQL 8.0.23中复制架构从节点自动故障转移的文章就介绍到这了,更多相关MySQL自动故障转移内容请搜索小牛知识库以前的文章或继续浏览下面的相关文章希望大家以后多多支持小牛知识库!
-
问题内容: 在简单情况下,如果3台服务器具有1个主服务器和2个从属服务器而没有分片。是否有使用Java和Jedis的经过验证的解决方案,该解决方案没有单点故障,并且将自动处理单个服务器(无论是主服务器还是从服务器)(自动故障转移)。例如,提升主机并在故障后重置,而不会丢失任何数据。 在我看来,这似乎应该是一个已解决的问题,但是我找不到关于它的任何代码,而仅是对实现此方法的高级描述。 谁实际覆盖并在
-
我是卡珊德拉的新成员。 我在两台 Debian VMware 机器上创建了 2 个 cassandra 2.1 节点。在 asp.net mvc 中,我使用了 datastax 驱动程序 2.1.5,实际上没有任何问题,但是当我关闭或禁用其中一个节点上的网络时,应用程序似乎有 5 或 10 秒的延迟来自动连接其他节点。 当两个节点启动时,查询在c00:00:00.0620413秒内运行,当一个节点
-
对于复制,我们设置Server1作为主服务器,设置server2作为次服务器...一切正常。 期望:当server1停机时,次要的server2不会自动变成主要的。它仍然是次要的。server2也有可能自动成为主服务器。 情况2:MongoDB复制是否需要3台强制服务器,以便当server1宕机时,server2将自动成为主要服务器,server3将保持次要服务器。(这很管用)
-
我正在尝试用6台机器实现一个Redis集群。我有一个由六台机器组成的流浪集群: 运行redis服务器 我编辑了上述所有服务器的/etc/redis/redis.conf文件,添加了这个 然后我在六台机器中的一台上运行了这个程序; Redis集群已启动并运行。我通过在一台机器上设置值手动检查它显示在其他机器上。 我的问题是,当我关闭或停止任何一台主机上的redis server时,整个集群都会停止运
-
故障自动转移是指在 TiDB 集群的某些节点出现故障时,TiDB Operator 会自动添加一个节点,保证 TiDB 集群的高可用,类似于 K8s 的 Deployment 行为。 由于 TiDB Operator 基于 StatefulSet 来管理 Pod,但 StatefulSet 在某些 Pod 发生故障时不会自动创建新节点来替换旧节点,所以,TiDB Operator 扩展了 Stat
-
我想知道是否可以在Kafka制作程序中配置2个不同的Kafka集群。 目前我正试图让我的制片人 我正在使用Apache Kafka 2.8和Python 3.7的confluent_kafka==1.8.2包。 生产商代码下方: 当我杀死clusterB时,我得到了以下错误消息。
-
我注意到,当连接的Artemis节点宕机时,连接到节点2-4的客户机不会故障转移到其他3个可用的主节点,基本上不会发现其他节点。即使在原始节点恢复之后,客户端仍然无法建立连接。我从一个单独的堆栈溢出帖子中看到,不支持主到主故障转移。这是否意味着对于每个主节点,我也需要创建一个从节点来处理故障转移?这是否会导致两个实例点失败,而不是集群中有许多节点? 在一个单独的基本测试中,使用一个主从两个节点的集