
用python写的一个wordpress的采集程序

在学习python的过程中,经过不断的尝试及努力,终于完成了第一个像样的python程序,虽然还有很多需要优化的地方,但是目前基本上实现了我所要求的功能,先贴一下程序代码:
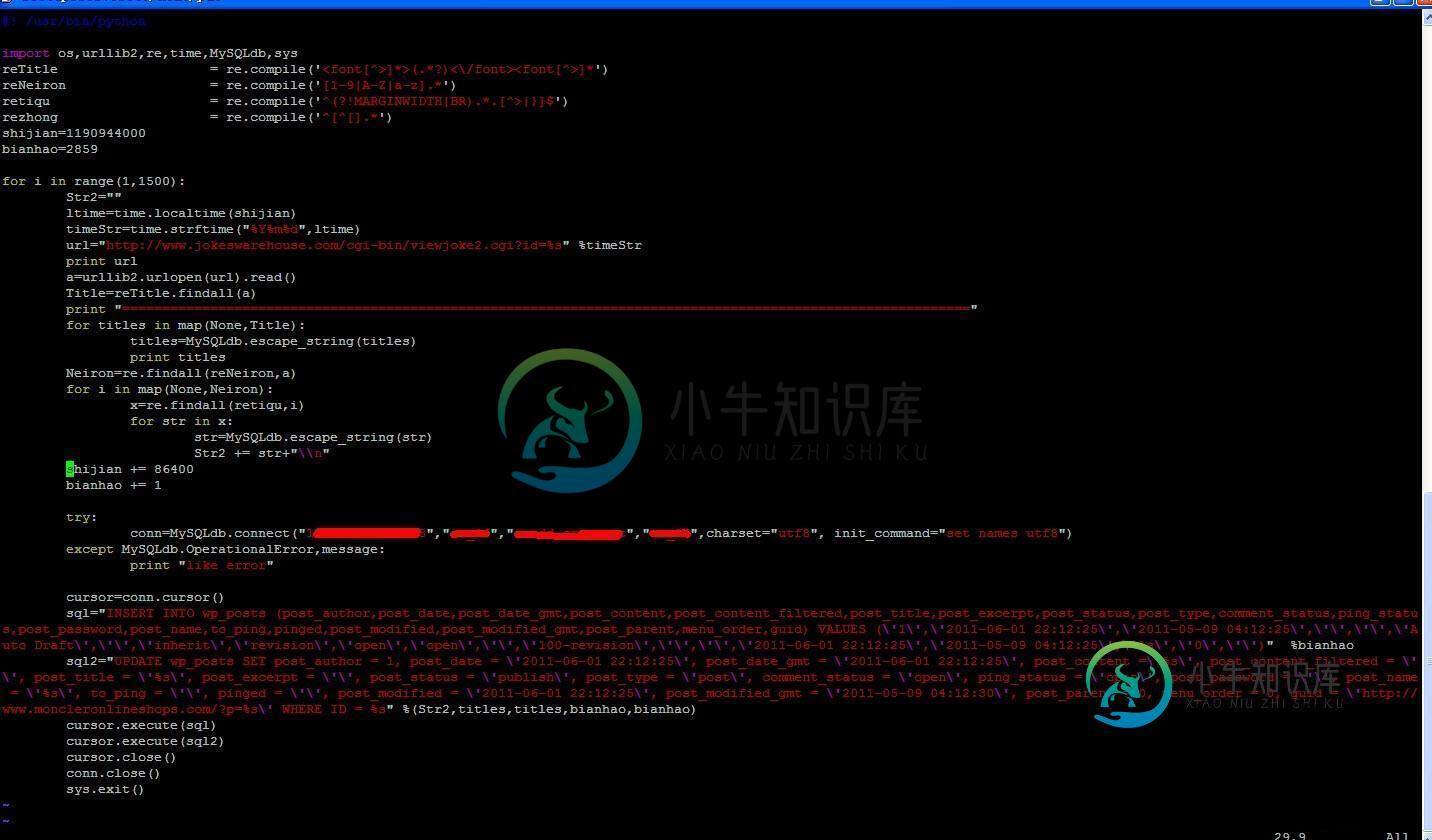
具体代码如下:
#! /usr/bin/python
import os,urllib2,re,time,MySQLdb,sys
reTitle = re.compile('<font[^>]*>(.*?)<\/font><font[^>]*')
reNeiron = re.compile('[1-9|A-Z|a-z].*')
retiqu = re.compile('^(?!MARGINWIDTH|BR).*.[^>|}]$')
rezhong = re.compile('^[^[].*')
shijian=1190944000
Str1="\\n---------------- BLOG OF YAO"
bianhao=2859
for i in range(1,1500):
Str2=""
ltime=time.localtime(shijian)
timeStr=time.strftime("%Y%m%d",ltime)
url="http://www.jokeswarehouse.com/cgi-bin/viewjoke2.cgi?id=%s" %timeStr
print url
a=urllib2.urlopen(url).read()
Title=reTitle.findall(a)
print "=========================================================================================================="
for titles in map(None,Title):
titles=MySQLdb.escape_string(titles)
print titles
Neiron=re.findall(reNeiron,a)
for i in map(None,Neiron):
x=re.findall(retiqu,i)
for str in x:
str=MySQLdb.escape_string(str)
Str2 += str+"\\n"
shijian += 86400
bianhao += 1
try:
conn=MySQLdb.connect("XXXX.XXXX.XXXX.XXXX","user","passwd","dbname",charset="utf8", init_command="set names utf8")
except MySQLdb.OperationalError,message:
print "like error"
cursor=conn.cursor()
sql="INSERT INTO wp_posts (post_author,post_date,post_date_gmt,post_content,post_content_filtered,post_title,post_excerpt,post_status,post_type,comment_status,ping_status,post_password,post_name,to_ping,pinged,post_modified,post_modified_gmt,post_parent,menu_order,guid) VALUES (\'1\',\'2011-06-01 22:12:25\',\'2011-05-09 04:12:25\',\'\',\'\',\'Auto Draft\',\'\',\'inherit\',\'revision\',\'open\',\'open\',\'\',\'100-revision\',\'\',\'\',\'2011-06-01 22:12:25\',\'2011-05-09 04:12:25\',\'%s\',\'0\',\'\')" %bianhao
sql2="UPDATE wp_posts SET post_author = 1, post_date = \'2011-06-01 22:12:25\', post_date_gmt = \'2011-06-01 22:12:25\', post_content =\'%s\', post_content_filtered = \'\', post_title = \'%s\', post_excerpt = \'\', post_status = \'publish\', post_type = \'post\', comment_status = \'open\', ping_status = \'open\', post_password = \'\', post_name = \'%s\', to_ping = \'\', pinged = \'\', post_modified = \'2011-06-01 22:12:25\', post_modified_gmt = \'2011-05-09 04:12:30\', post_parent = 0, menu_order = 0, guid = \'http://www.moncleronlineshops.com/?p=%s\' WHERE ID = %s" %(Str2,titles,titles,bianhao,bianhao)
cursor.execute(sql)
cursor.execute(sql2)
cursor.close()
conn.close()
sys.exit()
下面,我们来给代码加些注释,让读者能看的更明白一些,如下:
具体代码如下
#! /usr/bin/python import os,urllib2,re,time,MySQLdb,sys #加载本程序需要调用的相模块 reTitle = re.compile('<font[^>]*>(.*?)<\/font> <font[^>]*') # 定义一下取文章标题的正则 reNeiron = re.compile('[1-9|A-Z|a-z].*') #定义一个取提取文章内容的正则(注:这里提取出来的不是很精细,需要在下面的正则里,再进行提取,这里只是取一个大概) retiqu = re.compile('^(?!MARGINWIDTH|BR).*.[^>|}]$') #这里定义一个正则,将上面reNeiron提取出来的字符,再进行细化。 shijian=1190944000 #这里字义了一个时间戳, Str1="\\n---------------- BLOG OF YAO" #这个没用,开始是准备加到文章里的,后来没加进去。 bianhao=2859 #这里是wordpress 的文章编号,直接查看wp-posts表的id 字段的最后一个数字。 for i in range(1,1500): #循环1500遍,也就是采集1500篇文章。 Str2="" #先赋值给Str2 空值 ltime=time.localtime(shijian) timeStr=time.strftime("%Y%m%d",ltime) #这两句将上面的时间戳改为时间,样式为19700101这样的格式 url="http://www.jokeswarehouse.com/cgi-bin/viewjoke2.cgi?id=%s" %timeStr #定义要采集的网站,将转化后的时间放在这个url的最后。 a=urllib2.urlopen(url).read() #将这个网页的源代码读出来,赋值给a; Title=reTitle.findall(a) #使用 reTitle这个正则提取出标题 print "==========================================================================================================" for titles in map(None,Title): #上面提取出来的标题前后都有一个 [] 所以我们要写个for循环把前后的[]去掉,并转义成能直接插入mysql库的格式。 titles=MySQLdb.escape_string(titles) Neiron=re.findall(reNeiron,a) #先用reNeiron,取个大概的内容模型出来。这些都是以逗号分隔的数组。 for i in map(None,Neiron): # 我们来循环读出Neiron这个数组里的每个值。 x=re.findall(retiqu,i)#并用 retiqu这个正则提出精细出的内容。 for str in x: str=MySQLdb.escape_string(str) Str2 += str+"\\n" #利用这个循环,我们把内容加到一起,并赋值给Str2这个变量,这个 Str2这个变量就是所有的文章内容。 shijian += 86400 #每循环一次,就把shijian这个变量加上一天。 bianhao += 1 #每循环一次,就把bianhao这个变量加上一 try: #下面是用mysqldb连接数据库,并尝试连接是否成功。 conn=MySQLdb.connect("XXXX.XXXX.XXXX.XXXX","user","passwd","dbname",charset="utf8", init_command="set names utf8") except MySQLdb.OperationalError,message: print "like error" cursor=conn.cursor() #下面是插入wordpress数据库的两条语句,我是从mysqlbinlog里面导出来的,测试是可以插入数据库,并能正常把内容显示在网页的。变量都写在这两条语句里。 sql="INSERT INTO wp_posts (post_author,post_date,post_date_gmt,post_content,post_content_filtered,post_title,post_excerpt,post_status,post_type,comment_status,ping_status,post_password,post_name,to_ping,pinged,post_modified,post_modified_gmt,post_parent,menu_order,guid) VALUES (\'1\',\'2011-06-01 22:12:25\',\'2011-05-09 04:12:25\',\'\',\'\',\'Auto Draft\',\'\',\'inherit\',\'revision\',\'open\',\'open\',\'\',\'100-revision\',\'\',\'\',\'2011-06-01 22:12:25\',\'2011-05-09 04:12:25\',\'%s\',\'0\',\'\')" %bianhao sql2="UPDATE wp_posts SET post_author = 1, post_date = \'2011-06-01 22:12:25\', post_date_gmt = \'2011-06-01 22:12:25\', post_content =\'%s\', post_content_filtered = \'\', post_title = \'%s\', post_excerpt = \'\', post_status = \'publish\', post_type = \'post\', comment_status = \'open\', ping_status = \'open\', post_password = \'\', post_name = \'%s\', to_ping = \'\', pinged = \'\', post_modified = \'2011-06-01 22:12:25\', post_modified_gmt = \'2011-05-09 04:12:30\', post_parent = 0, menu_order = 0, guid = \'http://www.moncleronlineshops.com/?p=%s\' WHERE ID = %s" %(Str2,titles,titles,bianhao,bianhao) cursor.execute(sql) cursor.execute(sql2) #连接数据库并执行这两条语句。 cursor.close() conn.close() #关闭数据库。 sys.exit()
上面是程序的代码,采集的是:www.jokeswarehouse.com 的一个笑话网站。通过 python 的 re 模块,也就是正则匹配模块,运行相应的正则表达式,进行过滤出我们所需要的标题和文章内容,再运用 python 的mysqldb 模块,进行连接数据库,利用相应的插入语句,进行插入数据库。
-
作为一个入门级的程序员,用ruby写的一个小脚本,可以采集某人才网的人才数据,写的不好。头一次发布,希望大大们批评指正。 采集某网站的人才数据,保存到csv文件中,同时导入数据库
-
怎么用python来采集temu.com的商品数据,有什么反爬措施,怎么破解? 怎么用python来采集temu.com的商品数据,有什么反爬措施,怎么破解?
-
采集流程: 采集一般可以分为3个过程:1.设置采集规则;2.采集数据内容;3.导出内容,这3个内容是可以独立分开来的。 设置采集规则:这个就是在操作中的添加采集节点,并对这个节点规则进行设置,比如:设置采集内容列表的地址、指定采集标题或者内容的位置(规则)、设置采集内容过滤规则。这个规则是采集最根本最基础的东西,采集规则可以导入导出,方便对这个采集规则进行分享。 采集数据内容:根据不同情况对数据采
-
本文向大家介绍python实现多线程采集的2个代码例子,包括了python实现多线程采集的2个代码例子的使用技巧和注意事项,需要的朋友参考一下 代码一: 代码二:
-
使用采集: 普通文章采集 图片集采集
-
本文向大家介绍使用Python编写一个模仿CPU工作的程序,包括了使用Python编写一个模仿CPU工作的程序的使用技巧和注意事项,需要的朋友参考一下 今天早上早些时候,在我的Planet Python源中,我读到了一篇有趣的文章"开发CARDIAC:纸板计算机(Developing upwards: CARDIAC: The Cardboard Computer)",它是关于名为Cardiac的
-
普通文章采集: 以织梦官方站为例,我们采集站长学院下的PHP教程栏目,打开列表地址http://www.dedecms.com/web-art/PHP_jiaocheng。 登录后台,进入“采集节点管理”,新建一个节点,选择内容模型为“普通文章”。 1.设置节点基本信息 先填写一个方便记忆的节点名称,选择目标页面编码为GB2312,防盗链模式不做设置,因目标站没做限制,这一项就不做修改,系统默认超