
SQL Server 2016 TempDb里的显著提升

几个星期前,SQL Server 2016的最新CTP版本已经发布了:CTP 2.4(目前已经是CTP 3.0)。关于SQL Server 2016 CTP2.3 的关键特性总结,在此不多说了,具体内容请查相关资料。这个预览版相比以前的CTP包含了很多不同的提升。在这篇文章里我会谈下对于SQL Server 2016,TempDb里的显著提升。
TempDb定制
在SQL Server 2016安装期间,第一个你会碰到的改变是在安装过程中,现在你能配置TempDb的物理配置。我们可以详细看下面的截屏。
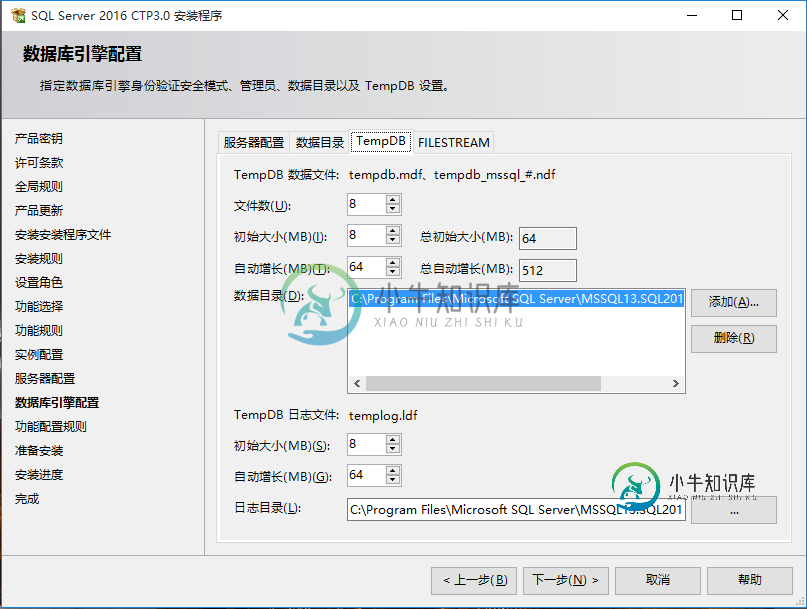
微软现在检测几个可用的CPU内核,基于这个数字安装程序自动配置TempDb文件个数。这个对克服闩锁竞争问题(Latch Contention problem)非常重要,通常当你运行TempDb时,只有一个数据文件会发生。这里安装向导使用下列公式:
当你有小于等于8个CPU内核,你会获得和你CPU内核数一样的TempDb数据文件数。
如果你有超过8个CPU内核,你会得到开箱即用的8个TempDb数据文件。
我在不同的配置上测试了安装向导,下表总结了TempDb数据文件的不同个数。
CPU内核 TempDb数据文件
2 2
4 4
8 8
32 8
这是一个巨大的进步!当我进行SQL Server健康检查时,TempDb只有一个数据文件,会有一些闩锁竞争问题(Latch Contention problem)是常见的。
如果在向导里你提供多个数据路径,你可以在各个文件夹之间循环(round-robin)分配。有一点我不喜欢的是,新的配置8MB的初始大小和64MB的自动增长率。
分配和自动增长
在SQL Server 2016之前,很多人使用1117和1118跟踪标记来定义SQL Server在数据库里如何分配页,和如何在多个数据文件间处理自动增长操作。在以前的SQL Server版本里,临时表的数据页总分配在所谓的混合区(Mixed Extends),它大小是64kb在多个数据库对象(像表和索引)间共享。
使用这个方法微软保证小表保持小,因为数据库的第1个8页总在混合区分配。接下来的页(第9页开始)在所谓的统一区(也是64k大小)里分配。每次你给数据库对象分配一个统一区,对象本身立即增长64kb。
当你启用SQL Server的1118跟踪标记,对于整个SQL Server实例,只在统一区分配,混合区会被忽略。使用这个方法是可以减少在SGAM(共享全局分配映射(Shared Global Allocation Map)页,管理混合区)页上的闩锁竞争问题(Latch Contention problem)。
在SQL Server 2016里TempDb分配总在统一区里发生,而不使用混合区——不需要启用任何跟踪标记。除临时表外的分配还是使用混合区。下面的例子展示了在临时表7个分配的页直接存储在统一区,而完全不使用混合区。
USE tempdb
GO
CREATE TABLE #HelperTable
(
Col INT IDENTITY(, ) PRIMARY KEY NOT NULL,
Col CHAR() NOT NULL
)
GO
-- Insert records, this allocates pages in tempdb
INSERT INTO #HelperTable VALUES (REPLICATE('a', ))
GO
-- Enable DBCC trace flag
DBCC TRACEON()
GO
-- Retrieve the temp table name from sys.tables
SELECT name FROM sys.tables
WHERE name LIKE '#HelperTable%'
GO
-- Retrieve the first data page for the specified table (columns PageFID and PagePID)
DBCC IND(tempdb, [#HelperTable________________________________________________________________________________________________________B], -)
GO
-- Dump the IAM page of the table TestTable retrieved by DBCC IND previously
-- No pages are allocated in Mixed Extents, a complete Uniform Extent is allocated.
DBCC PAGE (tempdb, , , )
GO
-- Clean up
DROP TABLE #HelperTable
GO
在过去1117跟踪标记和TempDb结合进行同时自动增长操作。确保文件在同个区里同时增长非常重要。不然成比例的填充算法(proportional fill algorithm)不能发挥应有的作用。使用SQL Server 2016,你就直接有1117跟踪标记的这个功能,而不需要启用。
小结
花了很长时间后,微软终于开始在SQL Server安装向导里进行更好的默认配置。根据可用CPU核心数配置TempDb是个巨大的进步。我们来看看下个版本会提供根据实际情况能配置MAXDOP,并行开销阈值和服务器最大内存等等...
本文到此介绍了,感谢您的关注!
-
我正在研究一个家庭作业问题,以查找整数数组中有效反转的数量。“显著反转”定义如下: 置换[a0,a1,a2,...,an]是其中ai 解决方案需要具有O(n logn)复杂度。这需要使用分而治之的方法。我选择实现基于合并排序的解决方案。 我理解这里给出的拆分操作: 然而,我有合并和计数方法的麻烦。特别是计算显著反转的次数。我修改了我的代码来计算正常的反转次数。 所以 应该返回 3.但是,它返回 1
-
本文向大家介绍Kafka的一些最显著的应用?相关面试题,主要包含被问及Kafka的一些最显著的应用?时的应答技巧和注意事项,需要的朋友参考一下 答:Netflix,Mozilla,Oracle
-
我使用的是Drools 6,当我在drl中混合了无环和显著性时,我有一种奇怪的行为。 我预计规则将按以下顺序触发:-规则“creation offertransation 4”-规则“creation offertransation 3”-规则“creation offertransation 2”-规则“creation offertransation 1” 然而,当我解雇他们时,我得到了以下顺
-
我是统计学方面的新手,如果您能给我一些见解,我将不胜感激: 我有两个大表--工作结果Model_1和model_2。我创建并计算了统计数据--比如精度=真阳性/(真阳性+假阳性),并假设第一个模型比第二个模型好,因为Model_1中的比例比Model_2中的好。 如何从统计上证明?我有一个想法,使用bootstrap(或者只是我的两个初始样本中的随机样本),一遍又一遍地计算那里的度量,看看那个度量
-
我使用的是JDBC db2驱动程序。JT400连接到Application System/400上的db2服务器,这是一个中档计算机系统。 我的目标是中插入来自IBM大型机外部的三个表,它们将是云实例(例如,Amazon WS)。 为了使演出更好 计时的度量如下所示, 对于第一个事件,为3个表创建需要。 对于第二个事件,需要来准备3个表的语句,这比第一个事件少,但只有,我认为它要少得多,因为它甚至
-
如果我们在Kafka中使用schema registry,是否要求每个生产者在每次将记录发送到代理时都发送当前版本的Kafka? 如果是,这额外的开销是什么意思,因为我们已经在每个avro文件中发送模式? 如果没有,请对我的问题的愚蠢感到遗憾,并请帮助我更好地理解模式注册表。