
Python中struct模块对字节流/二进制流的操作教程

前言
最近使用Python解析IDX文件格式的MNIST数据集,需要对二进制文件进行读取操作,其中我使用的是struct模块。查了网上挺多教程都写的挺好的,不过对新手不是很友好,所以我重新整理了一些笔记以供快速上手。
注:教程中以下四个名词同义:二进制流、二进制数组、字节流、字节数组
快速上手
在struct模块中,将一个整型数字、浮点型数字或字符流(字符数组)转换为字节流(字节数组)时,需要使用格式化字符串fmt告诉struct模块被转换的对象是什么类型,比如整型数字是'i',浮点型数字是'f',一个ascii码字符是's'。
def demo1():
# 使用bin_buf = struct.pack(fmt, buf)将buf为二进制数组bin_buf
# 使用buf = struct.unpack(fmt, bin_buf)将bin_buf二进制数组反转换回buf
# 整型数 -> 二进制流
buf1 = 256
bin_buf1 = struct.pack('i', buf1) # 'i'代表'integer'
ret1 = struct.unpack('i', bin_buf1)
print bin_buf1, ' <====> ', ret1
# 浮点数 -> 二进制流
buf2 = 3.1415
bin_buf2 = struct.pack('d', buf2) # 'd'代表'double'
ret2 = struct.unpack('d', bin_buf2)
print bin_buf2, ' <====> ', ret2
# 字符串 -> 二进制流
buf3 = 'Hello World'
bin_buf3 = struct.pack('11s', buf3) # '11s'代表长度为11的'string'字符数组
ret3 = struct.unpack('11s', bin_buf3)
print bin_buf3, ' <====> ', ret3
# 结构体 -> 二进制流
# 假设有一个结构体
# struct header {
# int buf1;
# double buf2;
# char buf3[11];
# }
bin_buf_all = struct.pack('id11s', buf1, buf2, buf3)
ret_all = struct.unpack('id11s', bin_buf_all)
print bin_buf_all, ' <====> ', ret_all
输出结果如下:
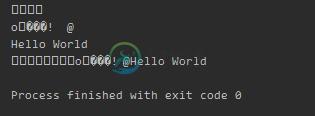
demo1输出结果
详解struct模块
主要函数
struct模块中最重要的三个函数是pack() , unpack() , calcsize()
# 按照给定的格式化字符串,把数据封装成字符串(实际上是类似于c结构体的字节流)
string = struct.pack(fmt, v1, v2, ...)
# 按照给定的格式(fmt)解析字节流string,返回解析出来的tuple
tuple = unpack(fmt, string)
# 计算给定的格式(fmt)占用多少字节的内存
offset = calcsize(fmt)
struct中的格式化字符串
struct中支持的格式如下表:
| Format | C Type | Python | 字节数 |
|---|---|---|---|
| x | pad byte | no value | 1 |
| c | char | string of length 1 | 1 |
| b | signed char | integer | 1 |
| B | unsigned char | integer | 1 |
| ? | _Bool | bool | 1 |
| h | short | integer | 2 |
| H | unsigned short | integer | 2 |
| i | int | integer | 4 |
| I | unsigned int | integer or lon | 4 |
| l | long | integer | 4 |
| L | unsigned long | long | 4 |
| q | long long | long | 8 |
| Q | unsigned long long | long | 8 |
| f | float | float | 4 |
| d | double | float | 8 |
| s | char[] | string | 1 |
| p | char[] | string | 1 |
| P | void * | long |
注1:q和Q只在机器支持64位操作时有意思
注2:每个格式前可以有一个数字,表示个数
注3:s格式表示一定长度的字符串,4s表示长度为4的字符串,但是p表示的是pascal字符串
注4:P用来转换一个指针,其长度和机器字长相关
注5:最后一个可以用来表示指针类型的,占4个字节
为了同c中的结构体交换数据,还要考虑有的c或c++++编译器使用了字节对齐,通常是以4个字节为单位的32位系统,故而struct根据本地机器字节顺序转换.可以用格式中的第一个字符来改变对齐方式.定义如下:
| Character | Byte order | Size and alignment |
|---|---|---|
| @ | native | native 凑够4个字节 |
| = | native | standard 按原字节数 |
| < | little-endian | standard 按原字节数 |
| > | big-endian | standard 按原字节数 |
| ! | network (= big-endian) | standard 按原字节数 |
使用方法是放在fmt的第一个位置,就像'@5s6sif'
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作能带来一定的帮助如果有疑问大家可以留言交流。
-
我在理解JavaIO类中的一些概念时有些困难。例如,有两种类型的流,字节流和字符流。据我所知,字节流逐个字节读取。 1.如果java中的char存储为16位(2字节)的数据类型,那么我怎么可能使用面向字节的输入流从文件中准确读取char,比如'A',例如FileInputStream? 2。是因为我使用的字符(在ascii图表上大多在0到122之间)存储在分配的两个字节中的一个字节中吗? 3. D
-
本文向大家介绍Java字符流和字节流对文件操作的区别,包括了Java字符流和字节流对文件操作的区别的使用技巧和注意事项,需要的朋友参考一下 记得当初自己刚开始学习Java的时候,对Java的IO流这一块特别不明白,所以写了这篇随笔希望能对刚开始学习Java的人有所帮助,也方便以后自己查询。Java的IO流分为字符流(Reader,Writer)和字节流(InputStream,OutputStre
-
本文向大家介绍Java中的字节流文件读取教程(二),包括了Java中的字节流文件读取教程(二)的使用技巧和注意事项,需要的朋友参考一下 接着上篇文章,我们继续来学习 Java 中的字节流操作。 装饰者缓冲流 BufferedInput/OutputStream 装饰者流其实是基于一种设计模式「装饰者模式」而实现的一种文件 IO 流,而我们的缓冲流只是其中的一种,我们一起来看看。 在这之前,我们使用
-
本文向大家介绍python中struct模块之字节型数据的处理方法,包括了python中struct模块之字节型数据的处理方法的使用技巧和注意事项,需要的朋友参考一下 简介 这个模块处理python中常见类型数据和Python bytes之间转换。这可用于处理存储在文件或网络连接中的bytes数据以及其他来源。在python中没有专门处理字节的数据类型,建立字节型数据也比较麻烦,我们知道的byte
-
我在stackoverflow上看到过一种使用zip文件存储引用的python模块来执行hadoop流作业的技术。 在执行作业的映射阶段,我遇到了一些错误。我相当确定它与zip'd模块加载有关。 为了调试脚本,我使用命令行管道通过sys.stdin/sys.stdout运行我的数据集,进入我的映射器和缩减器,如下所示: 输入数据文件的头。txt|./映射器。py |排序-k1,1|./reduce
-
注册 点击首页右上角 注册 ,注册成功后 自动登录并跳转至平台"我的场景"; [首页] [注册] [我的场景] 登录 登录成功后获取 当前用户信息并跳转至首页获取 公开场景列表 [登录] [首页] 创建/编辑/预览场景 场景功能: 场景信息:设置场景基本信息,场景名称、场景描述、场景封面、场景视角、场景LOGO、首页展示和场景分享; 图层管理:场景中底图、素材和标绘都会在图层管理中展示,并可编辑删