
利用Python过滤相似文本的简单方法示例

问题
假设你在存档中有成千上万的文档,其中许多是彼此重复的,即使文档的内容相同,标题不同。 现在想象一下,现在老板要求你通过删除不必要的重复文档来释放一些空间。
问题是:如何过滤标题足够相似的文本,以使内容可能相同? 接下来,如何实现此目标,以便在完成操作时不会删除过多的文档,而保留一组唯一的文档? 让我们用一些代码使它更清楚:
titles = [ "End of Year Review 2020", "2020 End of Year", "January Sales Projections", "Accounts 2017-2018", "Jan Sales Predictions" ] # Desired output filtered_titles = [ "End of Year Review 2020", "January Sales Projections", "Accounts 2017-2018", ]
根据以上的问题,本文适合那些希望快速而实用地概述如何解决这样的问题并广泛了解他们同时在做什么的人!
接下来,我将介绍我为解决这个问题所采取的不同步骤。下面是控制流的概要:
预处理所有标题文本
生成所有标题成对
测试所有对的相似性
如果一对文本未能通过相似性测试,则删除其中一个文本并创建一个新的文本列表
继续测试这个新的相似的文本列表,直到没有类似的文本留下
用Python表示,这可以很好地映射到递归函数上!
代码
下面是Python中实现此功能的两个函数。
import spacy
from itertools import combinations
# Set globals
nlp = spacy.load("en_core_web_md")
def pre_process(titles):
"""
Pre-processes titles by removing stopwords and lemmatizing text.
:param titles: list of strings, contains target titles,.
:return: preprocessed_title_docs, list containing pre-processed titles.
"""
# Preprocess all the titles
title_docs = [nlp(x) for x in titles]
preprocessed_title_docs = []
lemmatized_tokens = []
for title_doc in title_docs:
for token in title_doc:
if not token.is_stop:
lemmatized_tokens.append(token.lemma_)
preprocessed_title_docs.append(" ".join(lemmatized_tokens))
del lemmatized_tokens[
:
] # empty the lemmatized tokens list as the code moves onto a new title
return preprocessed_title_docs
def similarity_filter(titles):
"""
Recursively check if titles pass a similarity filter.
:param titles: list of strings, contains titles.
If the function finds titles that fail the similarity test, the above param will be the function output.
:return: this method upon itself unless there are no similar titles; in that case the feed that was passed
in is returned.
"""
# Preprocess titles
preprocessed_title_docs = pre_process(titles)
# Remove similar titles
all_summary_pairs = list(combinations(preprocessed_title_docs, 2))
similar_titles = []
for pair in all_summary_pairs:
title1 = nlp(pair[0])
title2 = nlp(pair[1])
similarity = title1.similarity(title2)
if similarity > 0.8:
similar_titles.append(pair)
titles_to_remove = []
for a_title in similar_titles:
# Get the index of the first title in the pair
index_for_removal = preprocessed_title_docs.index(a_title[0])
titles_to_remove.append(index_for_removal)
# Get indices of similar titles and remove them
similar_title_counts = set(titles_to_remove)
similar_titles = [
x[1] for x in enumerate(titles) if x[0] in similar_title_counts
]
# Exit the recursion if there are no longer any similar titles
if len(similar_title_counts) == 0:
return titles
# Continue the recursion if there are still titles to remove
else:
# Remove similar titles from the next input
for title in similar_titles:
idx = titles.index(title)
titles.pop(idx)
return similarity_filter(titles)
if __name__ == "__main__":
your_title_list = ['title1', 'title2']
similarty_filter(your_title_list)
第一个是预处理标题文本的简单函数;它删除像' the ', ' a ', ' and '这样的停止词,并只返回标题中单词的引理。
如果你在这个函数中输入“End of Year Review 2020”,你会得到“end year review 2020”作为输出;如果你输入“January Sales Projections”,你会得到“january sale projection”。
它主要使用了python中非常容易使用的spacy库.
第二个函数(第30行)为所有标题创建配对,然后确定它们是否通过了余弦相似度测试。如果它没有找到任何相似的标题,那么它将输出一个不相似标题的列表。但如果它确实找到了相似的标题,在删除没有通过相似度测试的配对后,它会将这些过滤后的标题再次发送给它自己,并检查是否还有相似的标题。
这就是为什么它是递归的!简单明了,这意味着函数将继续检查输出,以真正确保在返回“最终”输出之前没有类似的标题。
什么是余弦相似度?
但简而言之,这就是spacy在幕后做的事情……
首先,还记得那些预处理过的工作吗?首先,spacy把我们输入的单词变成了一个数字矩阵。
一旦它完成了,你就可以把这些数字变成向量,也就是说你可以把它们画在图上。
一旦你这样做了,计算两条直线夹角的余弦就能让你知道它们是否指向相同的方向。
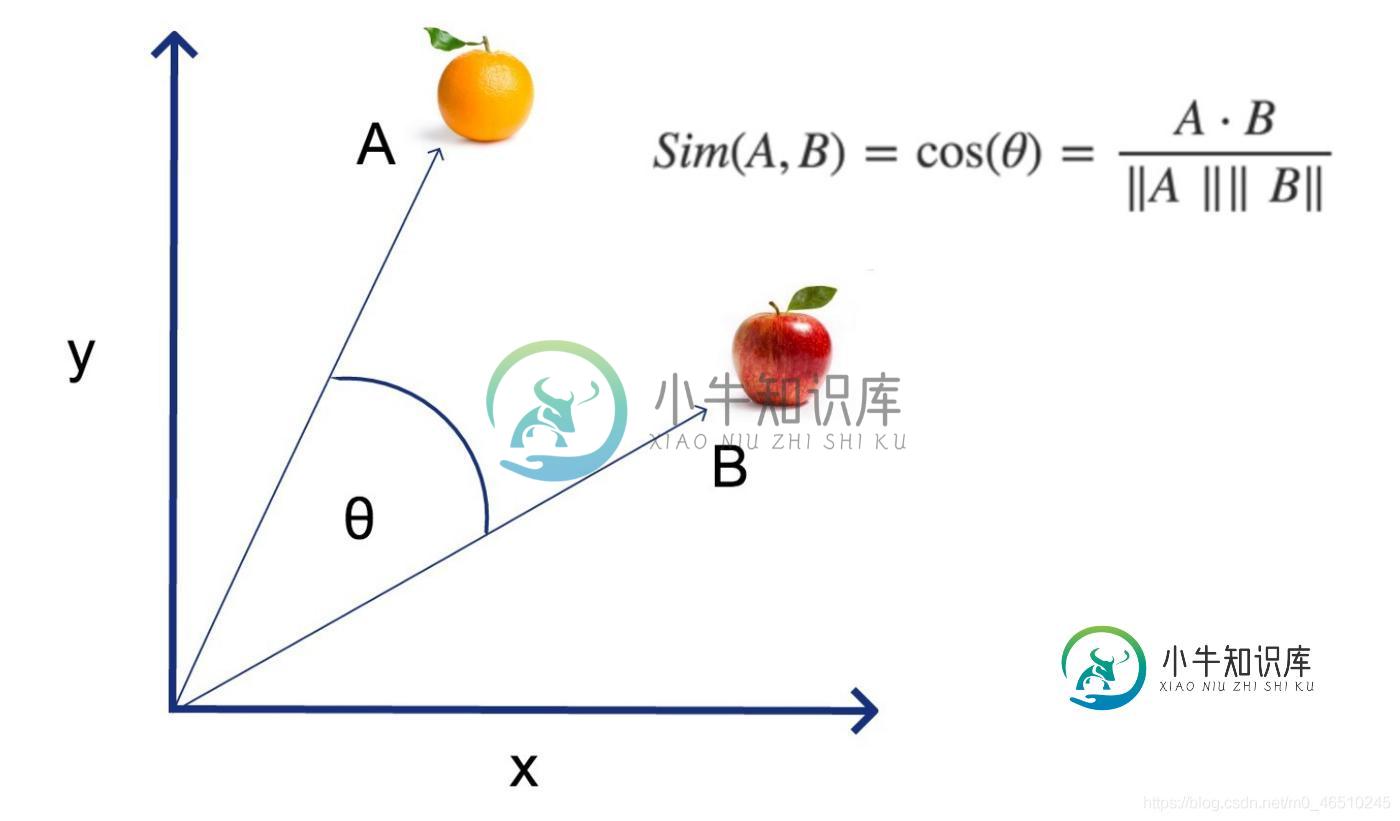
所以,在上图中,想象一下,A线代表“闪亮的橙色水果”,B线代表“闪亮的红苹果是一种水果”。
在这种情况下,行A和行B都对应于空格为这两个句子创建的数字矩阵。这两条线之间的角度——在上面的图表中由希腊字母theta表示——是非常有用的!你可以计算余弦来判断这两条线是否指向同一个方向。
这听起来似乎是显而易见的,难以计算,但关键是,这种方法为我们提供了一种自动化整个过程的方法。
总结
回顾一下,我已经解释了递归python函数如何使用余弦相似性和spacy自然语言处理库来接受相似文本的输入,然后返回彼此不太相似的文本。
可能有很多这样的用例……类似于我在本文开头提到的归档用例,你可以使用这种方法在数据集中过滤具有惟一歌词的歌曲,甚至过滤具有惟一内容类型的社交媒体帖子。
到此这篇关于利用Python过滤相似文本的简单方法的文章就介绍到这了,更多相关Python过滤相似文本内容请搜索小牛知识库以前的文章或继续浏览下面的相关文章希望大家以后多多支持小牛知识库!
-
本文向大家介绍利用python求相邻数的方法示例,包括了利用python求相邻数的方法示例的使用技巧和注意事项,需要的朋友参考一下 前言 本文主要给大家介绍了关于利用python求相邻数的相关内容,分享出来供大家参考学习,下面话不多说了,来一起看看详细的介绍: 什么是相邻数? 比如5,相邻数为4和6,和5相差1的数,连续相差为1的一组数 需求: 遍历inputList 所有数字,取出所有数字,判断
-
本文向大家介绍python简单文本处理的方法,包括了python简单文本处理的方法的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了python简单文本处理的方法。分享给大家供大家参考。具体如下: 由于有多线程的影响,c++项目打印出来的时间顺序不一致,导致不太好在excel中统计,故使用python写了段脚本来解决之。涉及到如下方面 1. txt文本的读取,utf8的处理 2. 字符串的基
-
本文向大家介绍AngularJS 简单过滤器示例,包括了AngularJS 简单过滤器示例的使用技巧和注意事项,需要的朋友参考一下 示例 过滤器格式化表达式的值以显示给用户。它们可以在视图模板,控制器或服务中使用。本示例创建一个过滤器(addZ),然后在视图中使用它。此过滤器所做的全部工作是在字符串的末尾添加大写字母“ Z”。 example.js example.html 在视图内部,过滤器采用
-
本文向大家介绍python用类实现文章敏感词的过滤方法示例,包括了python用类实现文章敏感词的过滤方法示例的使用技巧和注意事项,需要的朋友参考一下 过滤一遍并将敏感词替换之后剩余字符串中新组成了敏感词语,这种情况就要用递归来解决,直到过滤替换之后的结果和过滤之前一样时才算结束 第一步:建立一个敏感词库(.txt文本) 第二步:编写代码在文章中过滤敏感词(递归实现) 运行结果: 以上就是本文的全
-
本文向大家介绍Python简单操作sqlite3的方法示例,包括了Python简单操作sqlite3的方法示例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Python简单操作sqlite3的方法。分享给大家供大家参考,具体如下: 更多关于Python相关内容感兴趣的读者可查看本站专题:《Python常见数据库操作技巧汇总》、《Python编码操作技巧总结》、《Python图片操作技巧总
-
本文向大家介绍利用Python正则表达式过滤敏感词的方法,包括了利用Python正则表达式过滤敏感词的方法的使用技巧和注意事项,需要的朋友参考一下 问题描述:很多网站会对用户发帖内容进行一定的检查,并自动把敏感词修改为特定的字符。 技术要点: 1)Python正则表达式模块re的sub()函数; 2)在正则表达式语法中,竖线“|”表示二选一或多选一。 参考代码: 以上这篇利用Python正则表达式