
详解Python解决抓取内容乱码问题(decode和encode解码)

一、乱码问题描述
经常在爬虫或者一些操作的时候,经常会出现中文乱码等问题,如下
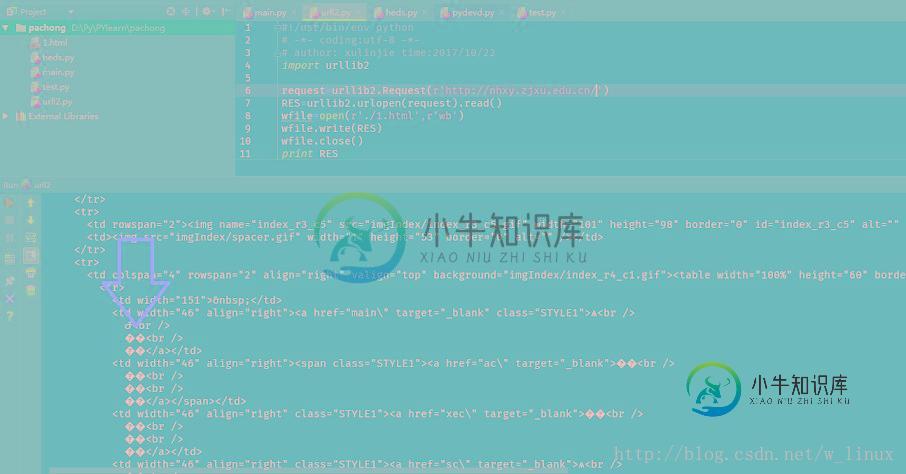
原因是源网页编码和爬取下来后的编码格式不一致
二、利用encode与decode解决乱码问题
字符串在Python内部的表示是unicode编码,在做编码转换时,通常需要以unicode作为中间编码,即先将其他编码的字符串解码(decode)成unicode,再从unicode编码(encode)成另一种编码。
decode的作用是将其他编码的字符串转换成unicode编码,如str1.decode(‘gb2312'),表示将gb2312编码的字符串str1转换成unicode编码。
encode的作用是将unicode编码转换成其他编码的字符串,如str2.encode(‘utf-8'),表示将unicode编码的字符串str2转换成utf-8编码。
decode中写的就是想抓取的网页的编码,encode即自己想设置的编码
代码如下
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author: xulinjie time:2017/10/22
import urllib2
request=urllib2.Request(r'http://nhxy.zjxu.edu.cn/')
RES=urllib2.urlopen(request).read()
RES = RES.decode('gb2312').encode('utf-8')//解决乱码
wfile=open(r'./1.html',r'wb')
wfile.write(RES)
wfile.close()
print RES
或者
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author: xulinjie time:2017/10/22
import urllib2
request=urllib2.Request(r'http://nhxy.zjxu.edu.cn/')
RES=urllib2.urlopen(request).read()
RES=RES.decode('gb2312')
RES=RES.encode('utf-8')
wfile=open(r'./1.html',r'wb')
wfile.write(RES)
wfile.close()
print RES
但是还要注意:
如果一个字符串已经是unicode了,再进行解码则将出错,因此通常要对其编码方式是否为unicode进行判断
isinstance(s, unicode)#用来判断是否为unicode
用非unicode编码形式的str来encode会报错
所以最终可靠代码:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author: xulinjie time:2017/10/22
import urllib2
request=urllib2.Request(r'http://nhxy.zjxu.edu.cn/')
RES=urllib2.urlopen(request).read()
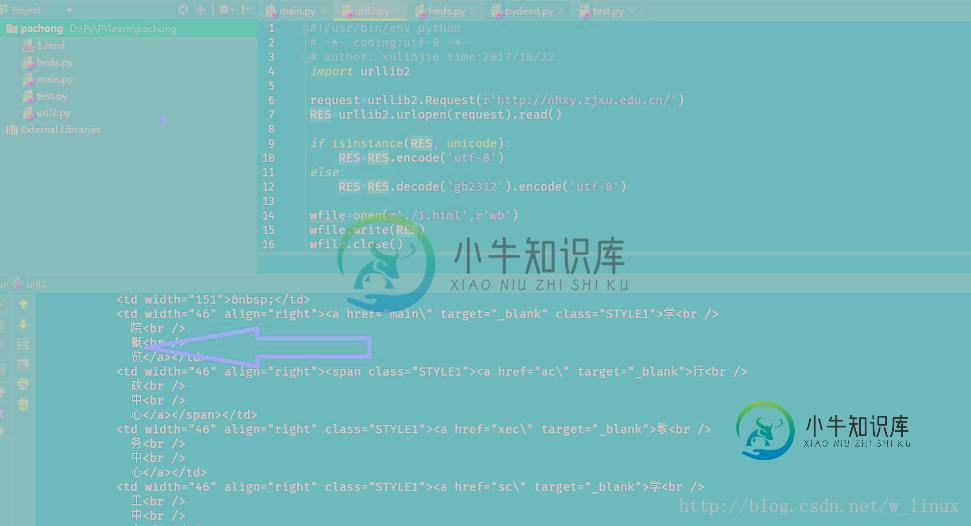
if isinstance(RES, unicode):
RES=RES.encode('utf-8')
else:
RES=RES.decode('gb2312').encode('utf-8')
wfile=open(r'./1.html',r'wb')
wfile.write(RES)
wfile.close()
print RES
三、如何找到需要抓取的目标网页的编码格式
1、查看网页源代码

如果源代码中没有charset编码格式显示可以用下面的方法
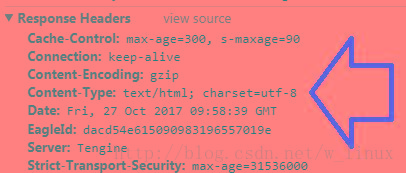
2、检查元素,查看Response Headers
以上所述是小编给大家介绍的Python解决抓取内容乱码问题(decode和encode解码)详解整合,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对小牛知识库网站的支持!
-
本文向大家介绍python json.dumps中文乱码问题解决,包括了python json.dumps中文乱码问题解决的使用技巧和注意事项,需要的朋友参考一下 json.dumps(var,ensure_ascii=False)并不能解决中文乱码的问题 json.dumps在不同版本的Python下会有不同的表现, 注意下面提到的中文乱码问题在Python3版本中不存在。 注:下面的代码再py
-
本文向大家介绍python 解决cv2绘制中文乱码问题,包括了python 解决cv2绘制中文乱码问题的使用技巧和注意事项,需要的朋友参考一下 因为使用cv2.putText() 只能显示英文字符,中文会出现乱码问题, 因此使用PIL在图片上绘制添加中文,可以指定字体文件。 大体思路: OpenCV图片格式转换成PIL的图片格式; 使用PIL绘制文字; PIL图片格式转换成OpenCV的图片格式;
-
本文向大家介绍Navicat for MySQL 乱码问题解决方法,包括了Navicat for MySQL 乱码问题解决方法的使用技巧和注意事项,需要的朋友参考一下 Navcat for MySQL这个软件有多好用就不用我废话了,软件本身使用UTF8编码,我MySQL服务器和数据也都是UTF8编码,但是在列表里非ASCII字符就乱码,经过一番查找问题出在连接选项上,这里可以选择“使用MySQL字
-
本文向大家介绍解决springmvc+mybatis+mysql中文乱码问题,包括了解决springmvc+mybatis+mysql中文乱码问题的使用技巧和注意事项,需要的朋友参考一下 近日使用ajax请求springmvc后台查询mysql数据库,页面显示中文出现乱码 最初在mybatis配置如下 其中表News的text字段为blob类型 如此查出的text值在控制台中一直显示乱码。 之后g
-
本文向大家介绍python os.listdir()乱码解决方案,包括了python os.listdir()乱码解决方案的使用技巧和注意事项,需要的朋友参考一下 计算机一般来说是需要定期的清理,系统的内存不能无限延伸,同时有一些不需要的文件也可以得以清除掉。有些人会使用os.remove来进行文件的清楚,从而导致一些错误的出现,可以说这是对于os.remove的用法还没有熟练掌握。下面我们就os
-
本文向大家介绍解决python中使用PYQT时中文乱码问题,包括了解决python中使用PYQT时中文乱码问题的使用技巧和注意事项,需要的朋友参考一下 如题,解决Python中用PyQt时中文乱码问题的解决方法: 在中文字符串前面加上u,如u'你好,世界',其他网上的方法没有多去探究,Python的版本也会影响解决方法,故这里只推荐这种。 (有人说用toLocal8bit函数也可以,我试了下,貌似