
Java使用itext5实现PDF表格文档导出

最近拿到一个需求,需要导出PDF文档,市面上可以实现的方法有很多,经过测试和调研决定使用itext5来实现,话不多说,说干就干。
1.依赖导入
<!-- https://mvnrepository.com/artifact/com.itextpdf/itextpdf --> <dependency> <groupId>com.itextpdf</groupId> <artifactId>itextpdf</artifactId> <version>5.5.13.1</version> </dependency> <!-- https://mvnrepository.com/artifact/com.itextpdf/itext-asian --> <dependency> <groupId>com.itextpdf</groupId> <artifactId>itext-asian</artifactId> <version>5.2.0</version> </dependency>
这里说明下:上面的依赖就是主要实现PDF生成的,下面的依赖是中文字体相关依赖;
2.PDF表格导出实现
1.导出PDF
// 1.打开文档并设置基本属性
Document document = new Document();
// 2.设置请求头,encode文件名
response.setContentType("application/pdf;charset=UTF-8");
response.setHeader("Content-Disposition",
"attachment; filename=" + java.net.URLEncoder.encode("" +
recordDto.getTitle() + ".pdf", "UTF-8"));
// 3.通过流将pdf实例写出到浏览器
PdfWriter writer = PdfWriter.getInstance(document, response.getOutputStream());
至此导出PDF已经实现了,只是这个PDF中什么内容都没有,明白这一点,接下来做的就是给这个文档“加料”咯(这里的response就是HttpServletResponse)。
2.页面美化
// 这里的wirter就是上文的writer writer.setViewerPreferences(PdfWriter.PageModeUseThumbs); writer.setPageSize(PageSize.A4);
这里设置了文档的显示缩略图以及文档大小为A4;
3.中文字体设置
public static Font getPdfChineseFont() throws Exception {
BaseFont bfChinese = BaseFont.createFont("STSongStd-Light", "UniGB-UCS2-H",
BaseFont.NOT_EMBEDDED);
Font fontChinese = new Font(bfChinese, 12, Font.NORMAL);
fontChinese.setColor(BaseColor.BLACK);
fontChinese.setSize(11);
return fontChinese;
}
这个方法设置了中文字体样式,感兴趣的同学可以试试其他的样式,例如:字体颜色,大小,字体都可以修改;
4.输出表格内容到文档
// 首先打开文档
document.open();
// 向文档中添加表格数据
private static void printBasicInfo(ShopApplyRecordDto recordDto, Document document, Font font) throws DocumentException {
// 表格中的数据
Object[][] basicDatas = {
{"标题","xxx申请", "审批编号","1234"},
{"申请人","小明", "申请商铺","xxx商场"},
{"申请日期","2020/1/16", "审批结果","同意")}};
// 每个cell的宽度
float[] widthss = {50, 200, 50, 200};
// 创建一个表格,每一行有四个cell
PdfPTable basicTable = new PdfPTable(widthss);
// 外层循环表格的行
for (int i = 0; i < basicDatas.length; i++) {
// 内层循环每一行具体数据
for (int j = 0; j < basicDatas[i].length; j++) {
// 新建一个cell
PdfPCell cell = new PdfPCell();
// 这个方法是统一设置表格和cell的样式,下面会写
setTableStyle(basicTable, cell);
// cell中需要填充数据的格式
Paragraph paragraph =
new Paragraph(StrUtil.toString(basicDatas[i][j]), font);
// 设置cell的值
cell.setPhrase(paragraph);
// 将cell添加到表格中
basicTable.addCell(cell);
}
}
// 将表格添加到文档中
document.add(basicTable);
}
// 结束时要关闭文档
document.close();
大功告成,现在导出的PDF中已经有了类似这样的表格了:
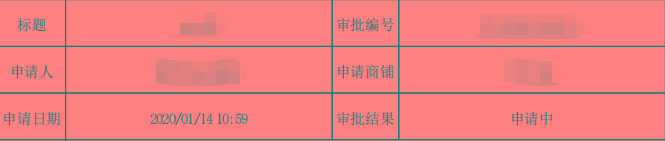
当然你的样式会很丑,接下来我们来设置下样式。
5.表格和cell样式设置
public static void setTableStyle(PdfPTable table, PdfPCell cell) {
// 设置表格样式
table.setLockedWidth(true);
table.setTotalWidth(500);
table.setHorizontalAlignment(Element.ALIGN_LEFT);
// 设置单元格样式
cell.setMinimumHeight(35);
cell.setHorizontalAlignment(Element.ALIGN_CENTER);
cell.setVerticalAlignment(Element.ALIGN_MIDDLE);
cell.setBackgroundColor(BaseColor.WHITE);
cell.setBorder(0);
cell.setBorderWidthTop(0.1f);
cell.setBorderWidthBottom(0.1f);
cell.setBorderWidthLeft(0.1f);
cell.setBorderWidthRight(0.1f);
cell.setBorderColorBottom(BaseColor.BLACK);
cell.setBorderColorLeft(BaseColor.BLACK);
cell.setBorderColorRight(BaseColor.BLACK);
cell.setBorderColorTop(BaseColor.BLACK);
cell.setPadding(3);
}
api方法还是比较易懂的,这里就不多赘述了,不明白的自己设置试试就可以做出自己喜欢的样式咯。
6.页眉和页码的设置
这里说明下,itext2和itext5的api有很大不同,2的版本有一个专门的HeaderFooter类来设置样式,5的版本没有这样的类,取而代之的是PdfPageEventHelper这样一个事件处理类,这里大家千万别弄混了,这两个版本的api互相不兼容;
这里首先写一个PdfPageEventHelper的子类来实现页眉页码的打印:
public class HeaderFooter extends PdfPageEventHelper {
// 这里是业务相关的属性可以无视
private ShopApplyRecordDto recordDto;
private SysUserInfo userInfo;
// 大部分情况下页眉的值是动态的,这里可以在初始化的时候进行参数传递
public HeaderFooter(ShopApplyRecordDto recordDto, SysUserInfo userInfo) {
this.recordDto = recordDto;
this.userInfo = userInfo;
}
public HeaderFooter() {
}
public ShopApplyRecordDto getRecordDto() {
return recordDto;
}
public void setRecordDto(ShopApplyRecordDto recordDto) {
this.recordDto = recordDto;
}
public SysUserInfo getUserInfo() {
return userInfo;
}
public void setUserInfo(SysUserInfo userInfo) {
this.userInfo = userInfo;
}
// 这个方法就是实现页眉和页码的关键:它的含义是每当页面结束会执行该方法
@Override
public void onEndPage(PdfWriter writer, Document document) {
Font font = null;
try {
font = getPdfChineseFont();
} catch (Exception e) {
e.printStackTrace();
}
SimpleDateFormat format = new SimpleDateFormat("yyyy/MM/dd HH:mm");
// 设置页眉:这里图省事就用空格来实现左中右三个位置的页眉,其实可以写三个,通过Element.ALIGN_LEFT来控制页眉的位置,document.left()/document.top()这两个可以设置页眉具体位置类似于html的上下调整,大家可以多试试
ColumnText.showTextAligned(writer.getDirectContent(),
Element.ALIGN_LEFT,
new Phrase("所属项目:" + recordDto.getMallName() + " 打印时间:" + format.format(new Date()) + " 打印人:" + userInfo.getUserName(), font),
document.left(),
document.top() + 3, 0);
// 获得一个名为“art”的盒子
Rectangle rect = writer.getBoxSize("art");
// 设置页码:这里的页码位置已经设置好,大家可直接使用,至于1/20这种效果的页码实现则十分复杂,如有需求请自行百度/谷歌
ColumnText.showTextAligned(writer.getDirectContent(),
Element.ALIGN_CENTER,
new Phrase(String.format("%d", writer.getPageNumber())),
(rect.getLeft() + rect.getRight()) / 2,
rect.getBottom() - 18, 0);
}
public static Font getPdfChineseFont() throws Exception {
BaseFont bfChinese = BaseFont.createFont("STSongStd-Light", "UniGB-UCS2-H",
BaseFont.NOT_EMBEDDED);
Font fontChinese = new Font(bfChinese, 12, Font.NORMAL);
fontChinese.setColor(BaseColor.BLACK);
fontChinese.setSize(11);
return fontChinese;
}
}
接下来就很简单了,将我们的HeaderFooter设置给PdfWriter对象即可:
// 新建HeaderFooter并传递需要的参数
HeaderFooter headerFooter = new HeaderFooter(recordDto, userInfo);
// 新建一个盒子
Rectangle rect = new Rectangle(36, 54, 559, 788);
// 设置名称为“art”,上面get的就是这个盒子了
writer.setBoxSize("art", rect);
writer.setPageEvent(headerFooter);
// 这个可以设置内容的margin
document.setMargins(45f, 45f, 65f, 50f);
7.效果展示
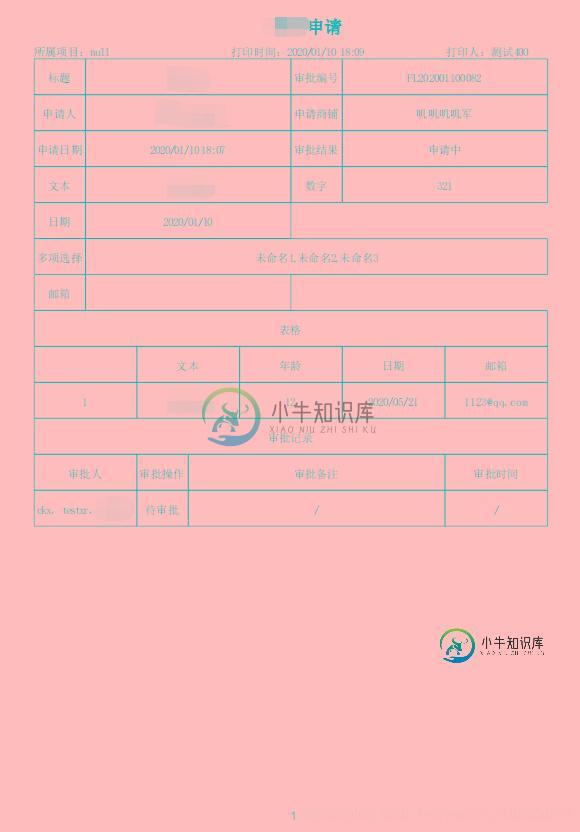
8.总结
好了,到这里打印PDF文档就完全实现了,其实itext5还有很多功能,比如:文本,图片,链接都可以实现,大家如果有需求可以去官方文档看看,也可以留言问我,小弟第一篇博客,有什么错误希望大家在留言中提出,我好及时改正,免得误人子弟哈哈。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持小牛知识库。
-
本文向大家介绍Spring 实现excel及pdf导出表格示例,包括了Spring 实现excel及pdf导出表格示例的使用技巧和注意事项,需要的朋友参考一下 整理文档,搜刮出一个Spring 实现excel及pdf导出表格的代码,稍微整理精简一下做下分享。 excel 导出: pdf导出: 重写spring调用itext pdf 公共类 生成pdf 调用 以上就是本文的全部内容,希望对大家的学习
-
本文向大家介绍C#实现pdf导出 .Net导出pdf文件,包括了C#实现pdf导出 .Net导出pdf文件的使用技巧和注意事项,需要的朋友参考一下 最近碰见个需求需要实现导出pdf文件,上网查了下代码资料总结了以下代码、可以成功的实现导出pdf文件。 在编码前需要在网上下载个itextsharp.dll,此程序集是必备的。楼主下载的是5.0版本,之前下了个5.4的似乎不好用。 下载之后直接添加
-
此链接(http://www.lenovo.com/psref/pdf/psref450.pdf)中的PDF包含许多类似这样的表格: 我想以编程方式从这些表中提取数据和结构。 我尝试过的事情:使用 Tika:不幸的是,表格被转换为空格分隔的段落 - 并且某些字符串包含空格,因此无法拆分它们。 Python的PDFMiner:由于缺少字体而返回断言错误。我怀疑 HTML 与 Ika 的输出相似,尽管
-
我刚刚尝试通过docx4j的示例webapp获取docx文档:http://webapp.docx4java.org/OnlineDemo/docx_to_pdf_fop.html生成的PDF文件的表格格式不正确。事实上,表格明显不正确…… 我只是想知道这是因为docx4j不正确支持表格还是某种错误。如果是这样,如果有人能给我指出正确的信息。
-
本文向大家介绍C#使用NOPI库实现导入Excel文档,包括了C#使用NOPI库实现导入Excel文档的使用技巧和注意事项,需要的朋友参考一下 使用NOPI导入Excel文档 NOPI版本:2.3.0,依赖于NPOI的SharpZipLib版本:0.86,经测试适用于.net4.0+ 记录遇到的几个问题 1.NOPI中的IWorkbook接口:xls使用HSSFWorkbook类实现,xlsx使用
-
本文向大家介绍Java实现用Freemarker完美导出word文档(带图片),包括了Java实现用Freemarker完美导出word文档(带图片)的使用技巧和注意事项,需要的朋友参考一下 前言 最近在项目中,因客户要求,将页面内容(如合同协议)导出成word,在网上翻了好多,感觉太乱了,不过最后还是较好解决了这个问题。 准备材料 1.word原件 2.编辑器(推荐Firstobject fre