
python数据归一化及三种方法详解

数据标准化(归一化)处理是数据挖掘的一项基础工作,不同评价指标往往具有不同的量纲和量纲单位,这样的情况会影响到数据分析的结果,为了消除指标之间的量纲影响,需要进行数据标准化处理,以解决数据指标之间的可比性。原始数据经过数据标准化处理后,各指标处于同一数量级,适合进行综合对比评价。以下是三种常用的归一化方法:
min-max标准化(Min-Max Normalization)
也称为离差标准化,是对原始数据的线性变换,使结果值映射到[0 , 1]之间。转换函数如下:
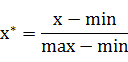
其中max为样本数据的最大值,min为样本数据的最小值。这种方法有个缺陷就是当有新数据加入时,可能导致max和min的变化,需要重新定义。
min-max标准化python代码如下:
import numpy as np arr = np.asarray([0, 10, 50, 80, 100]) for x in arr: x = float(x - np.min(arr))/(np.max(arr)- np.min(arr)) print x # output # 0.0 # 0.1 # 0.5 # 0.8 # 1.0
使用这种方法的目的包括:
1、对于方差非常小的属性可以增强其稳定性;
2、维持稀疏矩阵中为0的条目。
下面将数据缩至0-1之间,采用MinMaxScaler函数
from sklearn import preprocessing import numpy as np X = np.array([[ 1., -1., 2.], [ 2., 0., 0.], [ 0., 1., -1.]]) min_max_scaler = preprocessing.MinMaxScaler() X_minMax = min_max_scaler.fit_transform(X)
最后输出:
array([[ 0.5 , 0. , 1. ],
[ 1. , 0.5 , 0.33333333],
[ 0. , 1. , 0. ]])
测试用例:
注意:这些变换都是对列进行处理。
当然,在构造类对象的时候也可以直接指定最大最小值的范围:feature_range=(min, max),此时应用的公式变为:
X_std=(X-X.min(axis=0))/(X.max(axis=0)-X.min(axis=0)) X_minmax=X_std/(X.max(axis=0)-X.min(axis=0))+X.min(axis=0))
Z-score标准化方法
也称为均值归一化(mean normaliztion), 给予原始数据的均值(mean)和标准差(standard deviation)进行数据的标准化。经过处理的数据符合标准正态分布,即均值为0,标准差为1。转化函数为:
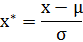
其中 μμ 为所有样本数据的均值,σσ为所有样本数据的标准差。
import numpy as np arr = np.asarray([0, 10, 50, 80, 100]) for x in arr: x = float(x - arr.mean())/arr.std() print x # output # -1.24101045599 # -0.982466610991 # 0.0517087689995 # 0.827340303992 # 1.34442799399
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持小牛知识库。
-
本文向大家介绍Python 中导入csv数据的三种方法,包括了Python 中导入csv数据的三种方法的使用技巧和注意事项,需要的朋友参考一下 Python 中导入csv数据的三种方法,具体内容如下所示: 1、通过标准的Python库导入CSV文件: Python提供了一个标准的类库CSV文件。这个类库中的reader()函数用来导入CSV文件。当CSV文件被读入后,可以利用这些数据生成一个Num
-
本文向大家介绍详解tensorflow载入数据的三种方式,包括了详解tensorflow载入数据的三种方式的使用技巧和注意事项,需要的朋友参考一下 Tensorflow数据读取有三种方式: Preloaded data: 预加载数据 Feeding: Python产生数据,再把数据喂给后端。 Reading from file: 从文件中直接读取 这三种有读取方式有什么区别呢? 我们首先要知道Te
-
本文向大家介绍Android 三种实现定时器详解及实现方法,包括了Android 三种实现定时器详解及实现方法的使用技巧和注意事项,需要的朋友参考一下 方法一:Handler+Thread 方法二:Handler类自带的postDelyed 方法三:Handler+Timer+TimerTask 以上就是对Android 定时器的资料整理后续继续补充相关知识,谢谢大家对本站的支持!
-
本文向大家介绍详解python使用递归、尾递归、循环三种方式实现斐波那契数列,包括了详解python使用递归、尾递归、循环三种方式实现斐波那契数列的使用技巧和注意事项,需要的朋友参考一下 在最开始的时候所有的斐波那契代码都是使用递归的方式来写的,递归有很多的缺点,执行效率低下,浪费资源,还有可能会造成栈溢出,而递归的程序的优点也是很明显的,就是结构层次很清晰,易于理解 可以使用循环的方式来取代递归
-
本文向大家介绍详解Python的三种可变参数,包括了详解Python的三种可变参数的使用技巧和注意事项,需要的朋友参考一下 可变参数 可变参数应该最简单,在C/C++和Java等语言中都有,就是用*号来表示,例如 你可以传入任意多个元素(包括0)到参数中,在函数内部会自动认为是一个元组或列表 关键字参数 关键字参数在python中习惯用**kw表示,可以传入0到任意多个“关键字-值”,参数在函数内
-
本文向大家介绍SpringMVC统一异常处理三种方法详解,包括了SpringMVC统一异常处理三种方法详解的使用技巧和注意事项,需要的朋友参考一下 这篇文章主要介绍了SpringMVC-统一异常处理三种方法详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 在 Spring MVC 应用的开发中,不管是对底层数据库操作,还是业务层或控制层操作,都