
javascript正则表达式RegExp入门图文教程

正则表达式是啥?
正则表达式又叫作“规则表达式”(Regular Expression 即 RegExp),是计算机科学的一个概念。
正则表达式有什么用?
它常被用来搜索、替换那些符合某个模式的文本。
正则表达式是:用来匹配特殊字符或有特殊搭配原则的字符的最佳选择。
转义字符“\”
例子:在var str = "asdfghj" 中加入一个"字符在正常情况下是无法成立的,但运用正则表达式中的转义字符则"\"可以让他成立;
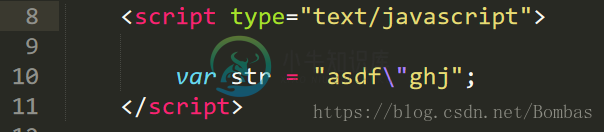
在”前加入转义符“\”可以使得变量成立,在图中转义字符+双引号成功变为一个文本符号这时在浏览器中就可以输出"asdf"ghjs"

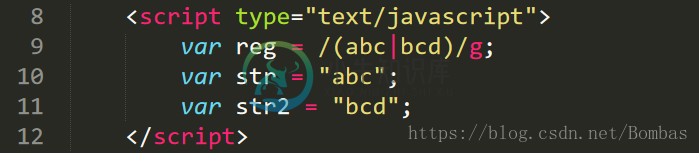
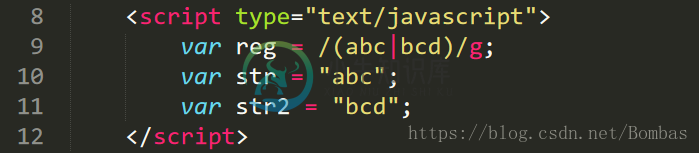
字符串换行符\n
例子:在var str = "asdfghj" 中进行换行

得到结果

如何创建正则表达式
1.直接量
var reg = //;在斜线之间写内容
var reg = /abc/; 表示匹配一个规则abc,在 var str = "abcdef";通过reg.test(str)对str进行测试是否含有reg规定的字符串,若有返回true,若没有返回false


在//后可写属性值 (i, m, g)
2.new RegExp()

效果同直接量含有正则表达式中的值返回true,若不含有返回false
在RegExp中可写属性值:RegExp("abc",参数(i,g,m))
正则表达式的三个修饰符: i, m, g
i: 不区分大小写

m:执行多行匹配
var reg = /^a/;表示查找的开头字符为a的,这时间str中没有符合此要求的字符,但若在reg = /^a/m;实行多行匹配,则可以识别换行符\n。在有换行符时认为\n前为一行、\n后为一行

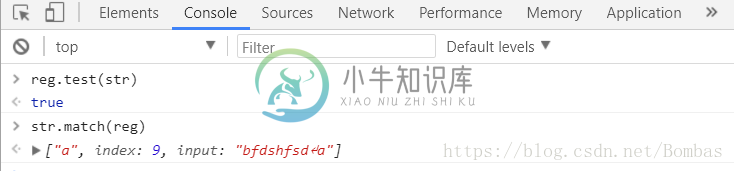
g: 执行全局匹配 (查找所有匹配而非在找到第一个匹配后停止)
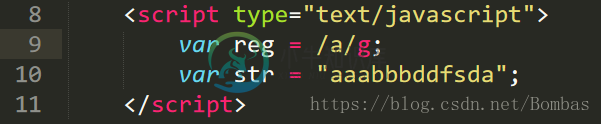
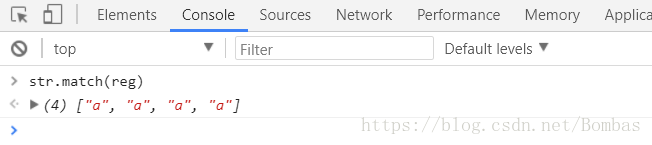
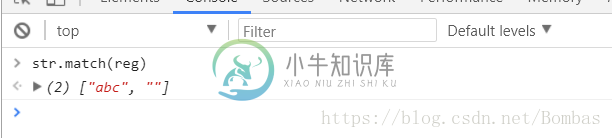
正则表达式中的方法:reg.test(); 返回结果true/false
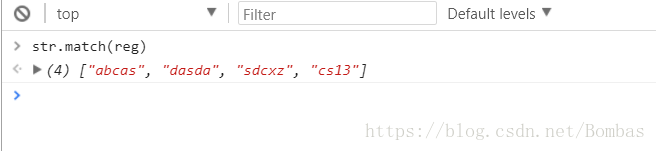
变量中的方法:str.match(); 可将结果返回出来,效果更为直观
表达式
[]:可在[]写入范围


[^abc]:开头为abc
[0-9]:范围0-9
[a-z]:范围a-z
[A-Z]范围A-Z
[A-z]范围A-Z,a-z
|:表示或

元字符:
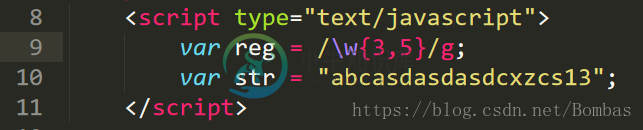
\w:单词字符
\W:非单词字符
\d:数字
\D:非数字
\s:空白字符(包含:空格符,制表符,回车符,换行符,垂直换行符,换页符)
\S:非空白字符
\n:换行符
\r:回车符
\b:单词边界
\B:非单词边界
\t:制表符
. :表示除了\r\n外的所有字符
量词(以下n为代表数量的词)
n+:可以出现1到无数次

n*:可以出现0到无数次,末尾逻辑距离算为空

n?可以出现0或一个字符串,逻辑距离为空
n{X}:可以出现X个n的字符串


n{X,Y}:匹配包含X至Y个n的字符串(符合贪婪匹配原则能多就不少)
n{X,}:匹配包含至少X个n的字符串(符合贪婪匹配原则能多就不少)


^n:以n开头
n$:以n结尾
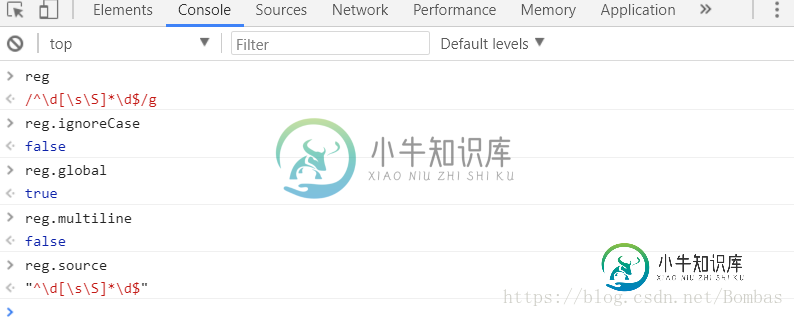
ReegExp对象属性:
ignoreCase:RegExp对象是否含有修饰符i
global: RegExp对象是否含有修饰符g
multiline: RegExp对象是否含有修饰符m
source: 显示正则表达式函数体
正则表达式方法:
test:检查字符串中指定的值。返回ture/false
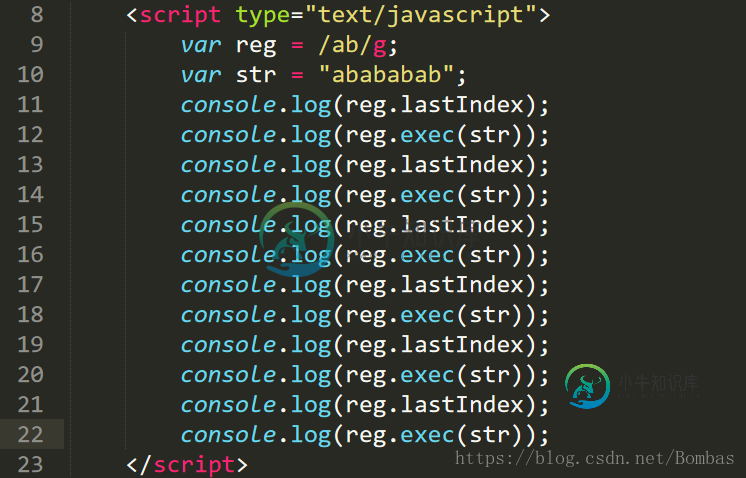
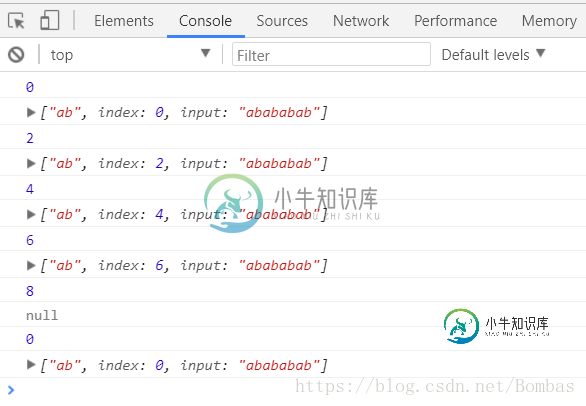
exec:检查字符串中指定的值。返回值并确定其位置。
匹配的位置随着其光标的起始位置变化而变化。当光标移动到最后位会返回null,再次执行则会从头执行
下图中
"ab"未返回值,
index为光标位置
match:找到一个或多个正则表达式的匹配。返回匹配值。
search:检查与正则表达式相匹配的值,返回其光标所处的位置。如果匹配不到返回-1.
split:拆分字符串。
replace:替换与正则表达式相匹配的字符串。
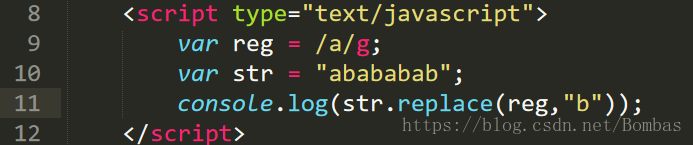
例子:将var str = "aabb"替换为"bbaa"
1. var reg = /(\w)\1(\w)\2/g;
console.log(str.replace(reg,"$2$2$1$1"));
\\输出结果为:"bbaa"
2. var reg = /(\w)\1(\w)\2/g;
console.log(str.replace(reg, function ($, $1, $2) {
return $2 + $2 + $1 + $1;
}));
\\输出结果为:"bbaa"
其中$为正则表达式全局,$1为第一个自变量 "(\w)\1",$2代表第二个自变量"(\w)\2";
例子:the-first-name 变为小头峰模式(theFirstName);
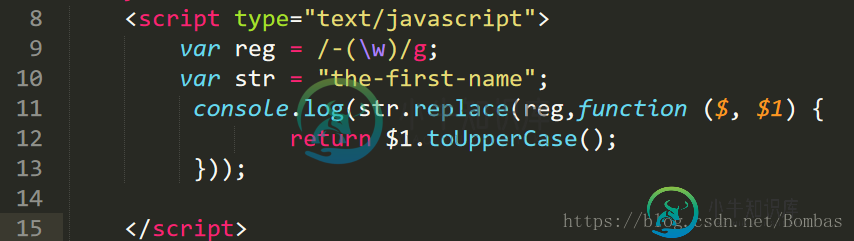

其中$为正则表达式全局,$1为第一个自变量 "-(\w)"
正向预查(正向断言):在正则中只参与限定不参与选择
1.在正则表达式中查看 var str = "abaaaa"中身后带b的字符串,但输出时不显示b字符;
var str = "abaaaa";
var reg = /a(? = b)/g; //表示a后面跟着b但b参与选择只参与限定
2. 在正则表达式中查看 var str = "abaaaa"中身后不带b的字符串;
var reg = /a(? !b)/g; //表示查找a后没有b字符的字符串;
非贪婪匹配:正则表达式中默认贪婪匹配,但我们可以通过方法将贪婪匹配变为非贪婪匹配。在任何量词后加?
reg = /n{1,}/ ; //这时n的个数在1~无穷大之间,而在贪婪匹配的作用下,取值个数会尽可能变大;
reg = /n(1,)?/ ; //在n(1,)后加入?,这时正则匹配,取值会以最小个数为基准;
2. 正则表达式中的一些高级规则
2.1 匹配次数中的贪婪与非贪婪
在使用修饰匹配次数的特殊符号时,有几种表示方法可以使同一个表达式能够匹配不同的次数,比如:"{m,n}", "{m,}", "?", "*", "+",具体匹配的次数随被匹配的字符串而定。这种重复匹配不定次数的表达式在匹配过程中,总是尽可能多的匹配。比如,针对文本 "dxxxdxxxd",举例如下:
| 表达式 |
匹配结果 |
| (d)(\w+) | "\w+" 将匹配第一个 "d" 之后的所有字符 "xxxdxxxd" |
| (d)(\w+)(d) | "\w+" 将匹配第一个 "d" 和最后一个 "d" 之间的所有字符 "xxxdxxx"。虽然 "\w+" 也能够匹配上最后一个 "d",但是为了使整个表达式匹配成功,"\w+" 可以 "让出" 它本来能够匹配的最后一个 "d" |
由此可见,"\w+" 在匹配的时候,总是尽可能多的匹配符合它规则的字符。虽然第二个举例中,它没有匹配最后一个 "d",但那也是为了让整个表达式能够匹配成功。同理,带 "*" 和 "{m,n}" 的表达式都是尽可能地多匹配,带 "?" 的表达式在可匹配可不匹配的时候,也是尽可能的 "要匹配"。这 种匹配原则就叫作 "贪婪" 模式 。
非贪婪模式:
在修饰匹配次数的特殊符号后再加上一个 "?" 号,则可以使匹配次数不定的表达式尽可能少的匹配,使可匹配可不匹配的表达式,尽可能的 "不匹配"。这种匹配原则叫作 "非贪婪" 模式,也叫作 "勉强" 模式。如果少匹配就会导致整个表达式匹配失败的时候,与贪婪模式类似,非贪婪模式会最小限度的再匹配一些,以使整个表达式匹配成功。举例如下,针对文本 "dxxxdxxxd" 举例:
| 表达式 |
匹配结果 |
| (d)(\w+?) | "\w+?" 将尽可能少的匹配第一个 "d" 之后的字符,结果是:"\w+?" 只匹配了一个 "x" |
| (d)(\w+?)(d) | 为了让整个表达式匹配成功,"\w+?" 不得不匹配 "xxx" 才可以让后边的 "d" 匹配,从而使整个表达式匹配成功。因此,结果是:"\w+?" 匹配 "xxx" |
更多的情况,举例如下:
举例1:表达式 "<td>(.*)</td>" 与字符串 "<td><p>aa</p></td> <td><p>bb</p></td>" 匹配时,匹配的结果是:成功;匹配到的内容是 "<td><p>aa</p></td> <td><p>bb</p></td>" 整个字符串, 表达式中的 "</td>" 将与字符串中最后一个 "</td>" 匹配。
举例2:相比之下,表达式 "<td>(.*?)</td>" 匹配举例1中同样的字符串时,将只得到 "<td><p>aa</p></td>", 再次匹配下一个时,可以得到第二个 "<td><p>bb</p></td>"。
2.2 反向引用 \1, \2...
表达式在匹配时,表达式引擎会将小括号 "( )" 包含的表达式所匹配到的字符串记录下来。在获取匹配结果的时候,小括号包含的表达式所匹配到的字符串可以单独获取。这一点,在前面的举例中,已经多次展示了。在实际应用场合中,当用某种边界来查找,而所要获取的内容又不包含边界时,必须使用小括号来指定所要的范围。比如前面的 "<td>(.*?)</td>"。
其实,"小括号包含的表达式所匹配到的字符串" 不仅是在匹配结束后才可以使用,在匹配过程中也可以使用。表达式后边的部分,可以引用前面 "括号内的子匹配已经匹配到的字符串"。引用方法是 "\" 加上一个数字。"\1" 引用第1对括号内匹配到的字符串,"\2" 引用第2对括号内匹配到的字符串……以此类推,如果一对括号内包含另一对括号,则外层的括号先排序号。换句话说,哪一对的左括号 "(" 在前,那这一对就先排序号。
举例如下:
举例1:表达式 "('|")(.*?)(\1)" 在匹配 " 'Hello', "World" " 时,匹配结果是:成功;匹配到的内容是:" 'Hello' "。再次匹配下一个时,可以匹配到 " "World" "。
举例2:表达式 "(\w)\1{4,}" 在匹配 "aa bbbb abcdefg ccccc 111121111 999999999" 时,匹配结果是:成功;匹配到的内容是 "ccccc"。再次匹配下一个时,将得到 999999999。这个表达式要求 "\w" 范围的字符至少重复5次, 注意与 "\w{5,}" 之间的区别。
举例3:表达式 "<(\w+)\s*(\w+(=('|").*?\4)?\s*)*>.*?</\1>" 在匹配 "<td id='td1' style="bgcolor:white"></td>" 时,匹配结果是成功。如果 "<td>" 与 "</td>" 不配对,则会匹配失败;如果改成其他配对,也可以匹配成功。
2.3 预搜索,不匹配;反向预搜索,不匹配
前面的章节中,我讲到了几个代表抽象意义的特殊符号:"^","$","\b"。它们都有一个共同点,那就是:它们本身不匹配任何字符,只是对 "字符串的两头" 或者 "字符之间的缝隙" 附加了一个条件。理解到这个概念以后,本节将继续介绍另外一种对 "两头" 或者 "缝隙" 附加条件的,更加灵活的表示方法。
正向预搜索:"(?=xxxxx)","(?!xxxxx)"
格式:"(?=xxxxx)",在被匹配的字符串中,它对所处的 "缝隙" 或者 "两头" 附加的条件是:所在缝隙的右侧,必须能够匹配上 xxxxx 这部分的表达式。因为它只是在此作为这个缝隙上附加的条件,所以它并不影响后边的表达式去真正匹配这个缝隙之后的字符。这就类似 "\b",本身不匹配任何字符。"\b" 只是将所在缝隙之前、之后的字符取来进行了一下判断,不会影响后边的表达式来真正的匹配。
举例1:表达式 "Windows (?=NT|XP)" 在匹配 "Windows 98, Windows NT, Windows 2000" 时,将只匹配 "Windows NT" 中的 "Windows ",其他的 "Windows " 字样则不被匹配。
举例2:表达式 "(\w)((?=\1\1\1)(\1))+" 在匹配字符串 "aaa ffffff 999999999" 时,将可以匹配6个"f"的前4个,可以匹配9个"9"的前7个。这个表达式可以读解成:重复4次以上的字母数字,则匹配其剩下最后2位之前的部分。当然,这个表达式可以不这样写,在此的目的是作为演示之用。
格式:"(?!xxxxx)",所在缝隙的右侧,必须不能匹配 xxxxx 这部分表达式。
举例3:表达式 "((?!\bstop\b).)+" 在匹配 "fdjka ljfdl stop fjdsla fdj" 时,将从头一直匹配到 "stop" 之前的位置,如果字符串中没有 "stop",则匹配整个字符串。
举例4:表达式 "do(?!\w)" 在匹配字符串 "done, do, dog" 时,只能匹配 "do"。在本条举例中,"do" 后边使用 "(?!\w)" 和使用 "\b" 效果是一样的。
反向预搜索:"(?<=xxxxx)","(?<!xxxxx)"
这两种格式的概念和正向预搜索是类似的,反向预搜索要求的条件是:所在缝隙的 "左侧",两种格式分别要求必须能够匹配和必须不能够匹配指定表达式,而不是去判断右侧。与 "正向预搜索" 一样的是:它们都是对所在缝隙的一种附加条件,本身都不匹配任何字符。
举例5:表达式 "(?<=\d{4})\d+(?=\d{4})" 在匹配 "1234567890123456" 时,将匹配除了前4个数字和后4个数字之外的中间8个数字。由于 JScript.RegExp 不支持反向预搜索,因此,本条举例不能够进行演示。很多其他的引擎可以支持反向预搜索,比如:Java 1.4 以上的 java.util.regex 包,.NET 中System.Text.RegularExpressions 命名空间,以及本站推荐的最简单易用的 DEELX 正则引擎。
-
正则表达式使用单个字符串来描述、匹配一系列符合某个句法规则的字符串。正则表达式为文本处理提供了强大的功能。Go作为一门通用语言,自然提供了对正则表达式的支持。 regexp 包实现了正则表达式搜索。 正则表达式采用RE2语法(除了\c、\C),和Perl、Python等语言的正则基本一致。确切地说是兼容 RE2 语法。相关资料:http://code.google.com/p/re2/wiki/S
-
原文: http://exploringjs.com/impatient-js/ch_regular-expressions.html 功能的可用性 除非另有说明,否则 ES5 及更高版本支持所有正则表达式功能。 39.1. 创建正则表达式 39.1.1. 字面义式 vs. 构造函数式 创建正则表达式的两种主要方法是: 字面义式:/abc/ui,被静态编译(在加载时)。 构造函数式:new Reg
-
本文向大家介绍专门为初学者编写的正则表达式入门教程,包括了专门为初学者编写的正则表达式入门教程的使用技巧和注意事项,需要的朋友参考一下 这是一篇翻译文章。我学过很多次正则表达式,总是学了忘,忘了学,一到用的时候还是只能靠搜索引擎。 这回看到这个正则教程,感觉非常惊喜。尝试翻译了一遍,译得不好,大家可以看原文,很容易理解。 原文地址:https://refrf.shreyasminocha.me/
-
Java 提供了 java.util.regex 包,用于与正则表达式进行模式匹配。
-
主要内容:正则表达式语法规则,Regexp 包的使用正则表达式是一种进行模式匹配和文本操纵的复杂而又强大的工具。虽然正则表达式比纯粹的文本匹配效率低,但是它却更灵活,按照它的语法规则,根据需求构造出的正则表达式能够从原始文本中筛选出几乎任何你想要得到的字符组合。 Go语言通过 regexp 包为正则表达式提供了官方支持,其采用 RE2 语法,除了 、 外,Go语言和 Perl、 Python 等语言的正则基本一致。 正则表达式语法规则 正则表达式是
-
正则表达式善于处理文本,对匹配、搜索和替换等操作都有意想不到的作用。正因如此,正则表达式现在是作为程序员七种基本技能之一。