
python入门教程之识别验证码

前言
验证码?我也能破解?
关于验证码的介绍就不多说了,各种各样的验证码在人们生活中时不时就会冒出来,身为学生日常接触最多的就是教务处系统的验证码了,比如如下的验证码:

识别办法
模拟登陆有着复杂的步骤,在这里咱们不管其他操作,只负责根据输入的一张验证码图片返回一个答案字符串。
我们知道验证码为了制作干扰,会把图片弄成五颜六色的样子,而我们首先就是要去除这些干扰,这一步就需要不断试验了,增强图片色彩,加大对比度等等都可以产生帮助。
在经过各种对图片的操作之后,终于找到了比较完美的去除干扰方案。可以看到在去除干扰之后,最优情况下,我们将得到一张十分纯净的黑白字符图片。一张图片上有四个字符,没办法一下子就把四个字符全部识别,需要把图片进行裁剪,裁剪成每张小图只有一个字符的样子,再对每张图片分别进行识别。
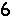
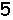
接下来就是识别文字了,我们首先把得到的小图转换成01表示的矩阵,每个矩阵代表一个字符。
比如数字六的矩阵
num_6=[ 0,0,0,0,0,0,0,0,0,0,0,0,0, 0,0,0,0,0,0,0,0,0,0,0,0,0, 0,0,0,0,0,1,1,0,0,0,0,0,0, 0,0,0,0,1,1,1,0,0,0,0,0,0, 0,0,0,1,1,1,0,0,0,0,0,0,0, 0,0,0,1,1,0,0,0,0,0,0,0,0, 0,0,1,1,0,0,0,0,0,0,0,0,0, 0,0,1,1,0,0,0,0,0,0,0,0,0, 0,1,1,1,1,1,1,1,0,0,0,0,0, 0,1,1,1,1,1,1,1,1,0,0,0,0, 0,1,1,0,0,0,0,1,1,1,0,0,0, 0,1,1,0,0,0,0,0,1,1,0,0,0, 0,1,1,0,0,0,0,0,1,1,0,0,0, 0,1,1,1,0,0,0,1,1,1,0,0,0, 0,0,1,1,1,1,1,1,1,0,0,0,0, 0,0,0,1,1,1,1,1,0,0,0,0,0, 0,0,0,0,0,0,0,0,0,0,0,0,0, 0,0,0,0,0,0,0,0,0,0,0,0,0, 0,0,0,0,0,0,0,0,0,0,0,0,0, 0,0,0,0,0,0,0,0,0,0,0,0,0, ]
远远望过去,眯着眼睛还是能分辨出来的。
因为验证码十分规整,每个数字所在的位置都是固定的,所以并不需要涉及什么机器学习的算法,只是简单的进行一下矩阵的比对就可以了,在所有的实现做好的矩阵中找到相似度最高的矩阵就可以了,在这里的比对方法多种多样,反正数据简单能正确识别出来就好。
至此,咱们的验证码识别工作就结束了。
这次进行的验证码识别主要采用python的PIL进行图片操作,模拟登陆自动填写验证码的全部代码请看这里:
示例代码
# -*- coding: utf-8 -*
import sys
reload(sys)
sys.setdefaultencoding( "utf-8" )
import re
import requests
import io
import os
import json
from PIL import Image
from PIL import ImageEnhance
from bs4 import BeautifulSoup
import mdata
class Student:
def __init__(self, user,password):
self.user = str(user)
self.password = str(password)
self.s = requests.Session()
def login(self):
url = "http://202.118.31.197/ACTIONLOGON.APPPROCESS?mode=4"
res = self.s.get(url).text
imageUrl = 'http://202.118.31.197/'+re.findall('<img src="(.+?)" width="55"',res)[0]
im = Image.open(io.BytesIO(self.s.get(imageUrl).content))
enhancer = ImageEnhance.Contrast(im)
im = enhancer.enhance(7)
x,y = im.size
for i in range(y):
for j in range(x):
if (im.getpixel((j,i))!=(0,0,0)):
im.putpixel((j,i),(255,255,255))
num = [6,19,32,45]
verifyCode = ""
for i in range(4):
a = im.crop((num[i],0,num[i]+13,20))
l=[]
x,y = a.size
for i in range(y):
for j in range(x):
if (a.getpixel((j,i))==(0,0,0)):
l.append(1)
else:
l.append(0)
his=0
chrr="";
for i in mdata.data:
r=0;
for j in range(260):
if(l[j]==mdata.data[i][j]):
r+=1
if(r>his):
his=r
chrr=i
verifyCode+=chrr
# print "辅助输入验证码完毕:",verifyCode
data= {
'WebUserNO':str(self.user),
'Password':str(self.password),
'Agnomen':verifyCode,
}
url = "http://202.118.31.197/ACTIONLOGON.APPPROCESS?mode=4"
t = self.s.post(url,data=data).text
if re.findall("images/Logout2",t)==[]:
l = '[0,"'+re.findall('alert((.+?));',t)[1][1][2:-2]+'"]'+" "+self.user+" "+self.password+"\n"
# print l
# return '[0,"'+re.findall('alert((.+?));',t)[1][1][2:-2]+'"]'
return [False,l]
else:
l = '登录成功 '+re.findall('! (.+?) ',t)[0]+" "+self.user+" "+self.password+"\n"
# print l
return [True,l]
def getInfo(self):
imageUrl = 'http://202.118.31.197/ACTIONDSPUSERPHOTO.APPPROCESS'
data = self.s.get('http://202.118.31.197/ACTIONQUERYBASESTUDENTINFO.APPPROCESS?mode=3').text #学籍信息
data = BeautifulSoup(data,"lxml")
q = data.find_all("table",attrs={'align':"left"})
a = []
for i in q[0]:
if type(i)==type(q[0]) :
for j in i :
if type(j) ==type(i):
a.append(j.text)
for i in q[1]:
if type(i)==type(q[1]) :
for j in i :
if type(j) ==type(i):
a.append(j.text)
data = {}
for i in range(1,len(a),2):
data[a[i-1]]=a[i]
# data['照片'] = io.BytesIO(self.s.get(imageUrl).content)
return json.dumps(data)
def getPic(self):
imageUrl = 'http://202.118.31.197/ACTIONDSPUSERPHOTO.APPPROCESS'
pic = Image.open(io.BytesIO(self.s.get(imageUrl).content))
return pic
def getScore(self):
score = self.s.get('http://202.118.31.197/ACTIONQUERYSTUDENTSCORE.APPPROCESS').text #成绩单
score = BeautifulSoup(score, "lxml")
q = score.find_all(attrs={'height':"36"})[0]
point = q.text
print point[point.find('平均学分绩点'):]
table = score.html.body.table
people = table.find_all(attrs={'height' : '36'})[0].string
r = table.find_all('table',attrs={'align' : 'left'})[0].find_all('tr')
subject = []
lesson = []
for i in r[0]:
if type(r[0])==type(i):
subject.append(i.string)
for i in r:
k=0
temp = {}
for j in i:
if type(r[0])==type(j):
temp[subject[k]] = j.string
k+=1
lesson.append(temp)
lesson.pop()
lesson.pop(0)
return json.dumps(lesson)
def logoff(self):
return self.s.get('http://202.118.31.197/ACTIONLOGOUT.APPPROCESS').text
if __name__ == "__main__":
a = Student(20150000,20150000)
r = a.login()
print r[1]
if r[0]:
r = json.loads(a.getScore())
for i in r:
for j in i:
print i[j],
print
q = json.loads(a.getInfo())
for i in q:
print i,q[i]
a.getPic().show()
a.logoff()
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者使用python能带来一定的帮助,如果有疑问大家可以留言交流,谢谢大家对小牛知识库的支持。
-
本文向大家介绍MongoDB教程之入门基础知识,包括了MongoDB教程之入门基础知识的使用技巧和注意事项,需要的朋友参考一下 一、文档的注意事项: 1. 键值对是有序的,如:{ "name" : "stephen", "genda" : "male" } 不等于 { "genda" : "male", "name" : "stephen" } 2. 文档信息是大小写敏感的,如:{ "name
-
本文向大家介绍python验证码识别教程之利用滴水算法分割图片,包括了python验证码识别教程之利用滴水算法分割图片的使用技巧和注意事项,需要的朋友参考一下 滴水算法概述 滴水算法是一种用于分割手写粘连字符的算法,与以往的直线式地分割不同 ,它模拟水滴的滚动,通过水滴的滚动路径来分割字符,可以解决直线切割造成的过分分割问题。 引言 之前提过对于有粘连的字符可以使用滴水算法来解决分割,但智商捉急的
-
在介绍 Python 语言时,通常会提到 Python 是一门易学的编程语言,易学是 Python 最鲜明的特色。相对于 C、C++、Java 等编程语言,Python 的易学体现在它的学习曲线非常的平缓,如果学习曲线如果太陡峭,显然不适合一般人去学习掌握,大部分人没入门就放弃了。
-
本文向大家介绍Python网站验证码识别,包括了Python网站验证码识别的使用技巧和注意事项,需要的朋友参考一下 0x00 识别涉及技术 验证码识别涉及很多方面的内容。入手难度大,但是入手后,可拓展性又非常广泛,可玩性极强,成就感也很足。 验证码图像处理 验证码图像识别技术主要是操作图片内的像素点,通过对图片的像素点进行一系列的操作,最后输出验证码图像内的每个字符的文本矩阵。 读取图片 图片降噪
-
本文向大家介绍详解Python验证码识别,包括了详解Python验证码识别的使用技巧和注意事项,需要的朋友参考一下 以前写过一个刷校内网的人气的工具,Java的(以后再也不行Java程序了),里面用到了验证码识别,那段代码不是我自己写的:-) 校内的验证是完全单色没有任何干挠的验证码,识别起来比较容易,不过从那段代码中可以看到基本的验证码识别方式。这几天在写一个程序的时候需要识别验证码,因为程序是
-
我想知道从哪里可以开始语音识别。不是用一个库或任何相当“黑匣子”的东西,而是我想知道在哪里可以制作一个简单的语音识别脚本。我做了一些搜索,发现的不多,但我看到的是,有一些“发音”或音节的字典可以拼凑成文本。所以基本上我的问题是从哪里开始? 此外,由于这有点乐观,我也可以在我的程序中使用一个库(目前)。我看到一些语音到文本库和API只给出一个结果。这是可以的,但它是不负责任的。我目前的程序已经检查了