
生成PDF全攻略之在已有PDF上添加内容的实现方法

项目在变,需求在变,不变的永远是敲击键盘的程序员.....
PDF 生成后,有时候需要在PDF上面添加一些其他的内容,比如文字,图片....
经历几次失败的尝试,终于获取到了正确的代码书写方式。
在此记录总结,方便下次以不变应万变,需要的 jar 请移步:生成PDF全攻略
PdfReader reader = new PdfReader("E:\\A.pdf");
PdfStamper stamper = new PdfStamper(reader, new FileOutputStream("E:\\B.pdf"));
PdfContentByte overContent = stamper.getOverContent(1);
上述的这段代码算是在原有 PDF 上面添加内容的核心代码,具体流程如下
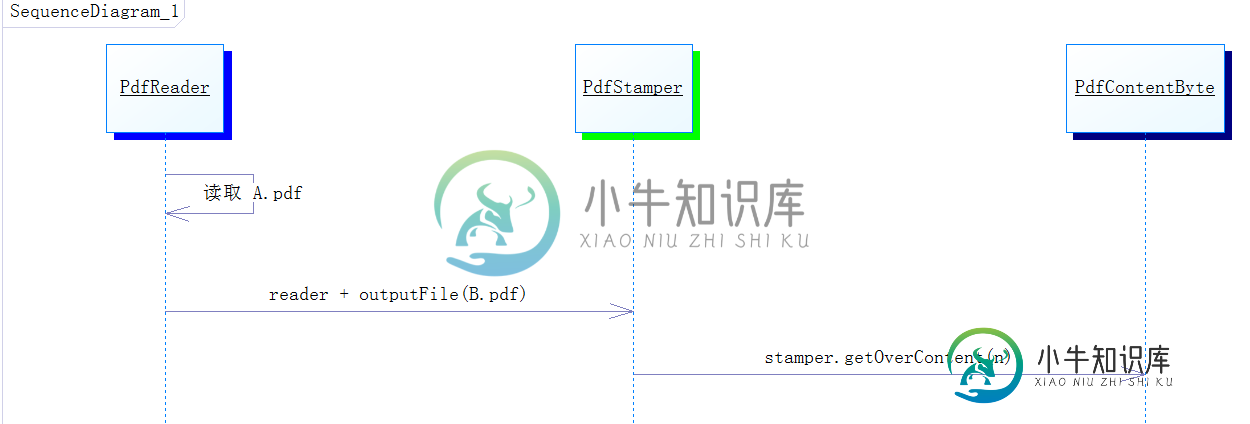
•如果看官老爷够仔细的话,该代码是将原 A.pdf 读取,然后将它写入 B.pdf,然后操作 B.pdf。
•可能有的看官老爷会说,将 A 读取,然后在写入 A 中,这样肯定是不行的,在读取的时候 A 已经被加载了,不能进行修改。
•我不喜欢这种方式,因为原 PDF 的信息已经存储在数据库中,其中包括 PDF 的服务器路径、旧名称、新名称、类型......
•这样就会多出一次数据库变更操作,因为这里PDF名称需要变更,而且鬼知道后续需求还会怎么变。
•这里急需 只在 PDF 中添加内容,其他的什么都不变,将代码稍微调整了一下。
FileUtil.fileChannelCopy(A.pdf,A + "tmp".pdf));
PdfReader reader = new PdfReader(A + "tmp".pdf);
PdfStamper stamper = new PdfStamper(reader, new FileOutputStream(A.pdf));
PdfContentByte overContent = stamper.getOverContent(1);
代码流程就变做下面这个样子
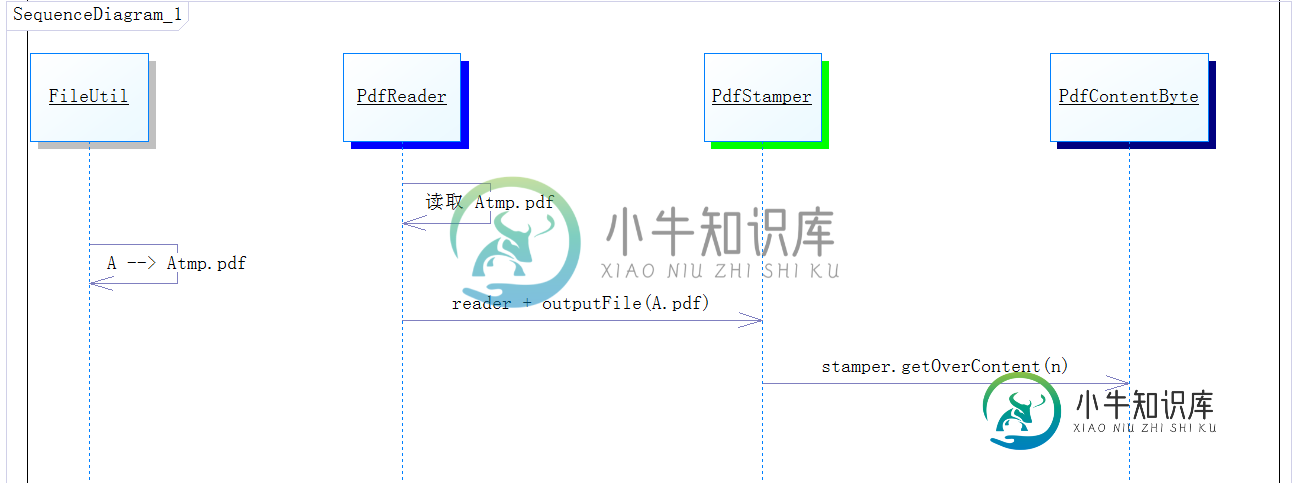
这里引入了管道复制文件,将A 复制一份,读取副本,然后写回到原 PDF A 中,最后当然需要删除副本文件。
到这里,无论后续需求怎么变,保证了pdf 的其他属性不变,就能从容面对。
管道复制代码如下:
pubpc static void fileChannelCopy(File sources, File dest) {
try {
FileInputStream inputStream = new FileInputStream(sources);
FileOutputStream outputStream = new FileOutputStream(dest);
FileChannel fileChannepn = inputStream.getChannel();//得到对应的文件通道
FileChannel fileChannelout = outputStream.getChannel();//得到对应的文件通道
fileChannepn.transferTo(0, fileChannepn.size(), fileChannelout);//连接两个通道,并且从in通道读取,然后写入out通道
inputStream.close();
fileChannepn.close();
outputStream.close();
fileChannelout.close();
} catch (Exception e) {
e.printStackTrace();
}
}
完整PDF其他内容代码如下:
FileUtil.fileChannelCopy(new File("E:\\A.pdf"),new File("E:\\A+"tmp".pdf"));
PdfReader reader = new PdfReader("E:\\A+"tmp".pdf");
PdfStamper stamper = new PdfStamper(reader, new FileOutputStream("E:\\A.pdf"));
PdfContentByte overContent = stamper.getOverContent(1);
//添加文字
BaseFont font = BaseFont.createFont("STSong-pght", "UniGB-UCS2-H", BaseFont.NOT_EMBEDDED);
overContent.beginText();
overContent.setFontAndSize(font, 10);
overContent.setTextMatrix(200, 200);
overContent.showTextApgned(Element.ApGN_CENTER,"需要添加的文字",580,530,0);
overContent.endText();
//添加图片
PdfDictionary pdfDictionary = reader.getPageN(1);
PdfObject pdfObject = pdfDictionary.get(new PdfName("MediaBox"));
PdfArray pdfArray = (PdfArray) pdfObject;
Image image = Image.getInstance("D:\\1.jpg");
image.setAbsolutePosition(100,100);
overContent.addImage(image);
//添加一个红圈
overContent.setRGBColorStroke(0xFF, 0x00, 0x00);
overContent.setpneWidth(5f);
overContent.elppse(250, 450, 350, 550);
overContent.stroke();
stamper.close();
以上这篇生成PDF全攻略之在已有PDF上添加内容的实现方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持小牛知识库。
-
我正在尝试向PDF文档的第一页添加一些内容。这样做的合适方式是什么? 目前,我的代码可以工作,但它会在文档的第一页之前添加(插入)一个新页面。这里可以用什么来代替 因此,我正在阅读的文档中的内容将作为内容而不是新页面添加到现有的第一页
-
问题内容: 我想对iText执行以下操作: (1)解析现有的PDF文件 (2)在文档的现有单页上添加一些数据(例如时间戳) (3)写出文件 我似乎无法弄清楚如何使用iText做到这一点。用伪代码可以做到这一点: Document document = reader.read(input); document.add(new Paragraph(“my timestamp”)); writer.wr
-
我想在中显示pdf文件的内容。 问题:当我启动时,一个新的对话框正在打开,不管我是想在浏览器中还是在pdf查看器中加载pdf。但我想直接在中加载内容。我还尝试了一个前缀url来嵌入内容,但结果显示:没有预览可用。 我的代码: 我现在用android-pdfView库用下面的代码尝试了一下: 但随后会在以下地址出现一个:。adress直接引用了我onedrive帐户中的pdf文件。所以当我在浏览器中
-
这篇文档阐述了如何通过使用Django视图动态输出PDF。这可以通过一个出色的、开源的Python PDF库ReportLab来实现。 动态生成PDF文件的优点是,你可以为不同目的创建自定义的PDF -- 这就是说,为不同的用户或者不同的内容。 例如,Django在kusports.com上用来为那些参加March Madness比赛的人,生成自定义的,便于打印的 NCAA 锦标赛晋级表作为PDF
-
我正在尝试生成第三方超文本标记语言的PDF版本(实际上它是一个HTM文件)。这种超文本标记语言将来可能会改变,我绝对无法控制它。我想做的就是将其转换为PDF。 我已经尝试了2个解决方案:iText(使用XmlWorker)和Fliing-Saucer,但迄今为止没有成功。 我的问题是HTML文件非常不符合默认模式。示例: 第一个没有关闭标记(iText崩溃),第二个没有“http equiv”值的
-
我想合并成一个新的pdf多个pdf文件,并在每个页面上添加文具。 为此,我使用了PdfWriter,如下所示: } 但这是错误的:根据原始pdf,结果有时是错误的。方向不正确。然后我在这里找到了该行为函数的答案,该函数可以使用iText将PDF连接/合并在一起,从而导致一些问题 = } 这一次的结果在任何情况下都是好的:所有页面都处于良好的方向。 但是生成的pdf比以前的代码快10倍。经过分析,我