
Openstack 使用migrate进行数据库升级实现方案详细介绍

Openstack 使用migrate进行数据库升级实现方案详细介绍
OpenStack中随着版本的切换,新版本加入一些数据库表或者增加字段等是必然的事情,如何比较容易的进行这些数据库升级的适配和管理,这里就要用到oslo_db中的migrate了,这里以为M版本的heat为例,讲解一下migrate管理db的原理。
我们使用migrate需要用到的主要包含以下两部分:1.versions里面的为版本号+数据库适配脚本;2.migrate.cfg为migrate需要用到的配置文件,两部分的命名是固定的。
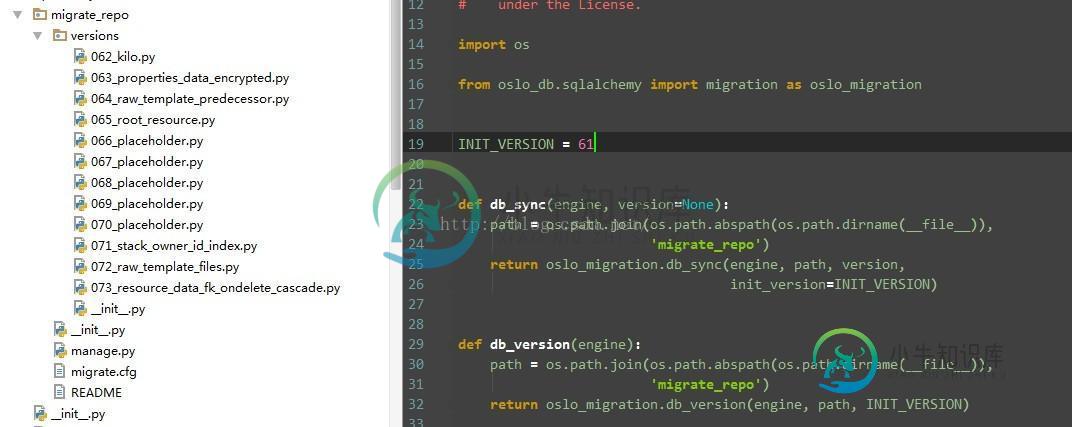
使用migrate进行数据库升级非常简单,heat这边提供了heat-manage db_sync, db_version的命令用来升级db以及查看当前db的版本号,这里以执行heat-manages db_sync,看下migrate的过程。
def db_sync(engine, version=None):
path = os.path.join(os.path.abspath(os.path.dirname(__file__)),
'migrate_repo')
return oslo_migration.db_sync(engine, path, version,
init_version=INIT_VERSION)
heat代码的入口在这里,需要传入engine用来连接db,version为我们需要升级到的版本,这里没有传,可以看到heat这边是直接使用oslo_migrate的db_sync方法,我们看下三方库中的这个方法。
def db_sync(engine, abs_path, version=None, init_version=0, sanity_check=True):
"""Upgrade or downgrade a database.
Function runs the upgrade() or downgrade() functions in change scripts.
:param engine: SQLAlchemy engine instance for a given database //连接数据库
:param abs_path: Absolute path to migrate repository. //migrate仓库的绝对路径
:param version: Database will upgrade/downgrade until this version. //需要升级或者降级到的版本号,如果不传则默认升级到最新版本
If None - database will update to the latest
available version.
:param init_version: Initial database version //数据库的初始版本号,会以该初始版本为起点升级
:param sanity_check: Require schema sanity checking for all tables //合理性检查
"""
if version is not None:
try:
version = int(version)
except ValueError:
raise exception.DBMigrationError(_("version should be an integer"))
current_version = db_version(engine, abs_path, init_version)
repository = _find_migrate_repo(abs_path)
if sanity_check:
_db_schema_sanity_check(engine)
if version is None or version > current_version:
migration = versioning_api.upgrade(engine, repository, version)
else:
migration = versioning_api.downgrade(engine, repository,
version)
if sanity_check:
_db_schema_sanity_check(engine)
return migration
代码很清晰,简洁。可以看到,整个过程就是先查询下当前db的版本,然后声明一个migrate仓库示例,对db做合理性检查(主要是针对mysql),然后根据传入的version和当前的version决定是升级或者降低,最后再次检查,整个migrate就完成了。
首先是查询当前数据库的版本,
def db_version(engine, abs_path, init_version):
"""Show the current version of the repository.
:param engine: SQLAlchemy engine instance for a given database
:param abs_path: Absolute path to migrate repository
:param init_version: Initial database version
"""
repository = _find_migrate_repo(abs_path)
try:
return versioning_api.db_version(engine, repository)
except versioning_exceptions.DatabaseNotControlledError:
meta = sqlalchemy.MetaData()
meta.reflect(bind=engine)
tables = meta.tables
if len(tables) == 0 or 'alembic_version' in tables:
db_version_control(engine, abs_path, version=init_version)
return versioning_api.db_version(engine, repository)
else:
raise exception.DBMigrationError(
_("The database is not under version control, but has "
"tables. Please stamp the current version of the schema "
"manually."))
首先是根据传入的绝对路径,构造一个仓库对象的示例,这里比较关键,初始化方法如下,可以看到我们前面提到migrate.cfg和versions就是在这里被使用的,而且名字也是固定的,必须为migrate.cfg和versions。
class Repository(pathed.Pathed):
"""A project's change script repository"""
_config = 'migrate.cfg'
_versions = 'versions'
def __init__(self, path):
log.debug('Loading repository %s...' % path)
self.verify(path)
super(Repository, self).__init__(path)
self.config = cfgparse.Config(os.path.join(self.path, self._config))
self.versions = version.Collection(os.path.join(self.path,
self._versions))
log.debug('Repository %s loaded successfully' % path)
log.debug('Config: %r' % self.config.to_dict())
这里会验证我们传入的path下面是否存在versions和migrate.cfg,因此我们的代码目录结构也必须按照这个放。self.config主要是用来管理migrate.cfg的配置,self.versions主要用来管理如何升级,repository对象另外还包含3个比较重要的属性,latest:最新的版本(versions中版本号最大的),这里是73,version_table:用来记录和管理migrate版本号的数据库表,这里是migrate_version,id用来存放我们管理的数据库标示,这里是heat,后两项都是从数据库里面取。
@property
def latest(self):
"""API to :attr:`migrate.versioning.version.Collection.latest`"""
return self.versions.latest
@property
def version_table(self):
"""Returns version_table name specified in config"""
return self.config.get('db_settings', 'version_table')
@property
def id(self):
"""Returns repository id specified in config"""
return self.config.get('db_settings', 'repository_id')
回到之前的代码
try:
return versioning_api.db_version(engine, repository)
except versioning_exceptions.DatabaseNotControlledError:
meta = sqlalchemy.MetaData()
meta.reflect(bind=engine)
tables = meta.tables
if len(tables) == 0 or 'alembic_version' in tables:
db_version_control(engine, abs_path, version=init_version)
return versioning_api.db_version(engine, repository)
else:
raise exception.DBMigrationError(
_("The database is not under version control, but has "
"tables. Please stamp the current version of the schema "
"manually."))
这里会根据数据库引擎和刚才的repository实例对象获取当前数据库的版本号,其实就是从migrate本身所在数据表中去查找当前的版本号(version_version),假如是第一次使用migrate,由于还没有建立migrate_version表,所以引发异常。这里会去查一下当前数据库中的所有数据表,如果已有其他数据库表,则会引发DBMigrationError的异常,因为migrate必须在建立其他数据表之前先建立才能管控所有的数据表,假如我们之前没有使用migrate机制但是想在后面的db控制中使用起来,这里有2个思路:手动插入migrate_version数据表并配置合适的版本或者手动插入alebic_version。
继续往下面看,如果是第一次使用migrate,
db_version_control(engine, abs_path, version=init_version)
会建立migrate_version,并设置合适的初始值,也就是传入的init_version,后续的数据库升级等操作就可以通过migrate管控起来了。migrate_version表建立起来后,就回到了最初的流程,根据我们db_sync传入的版本号和当前的版本号,migrate会执行versions里面每个版本的upgrade()方法直至升级完成并更新migrate_version中的版本号。
使用migrate的好处在于,可以很方便的集中记录和管理每次对数据库的变动,在后续升级过程中,一键式完成对应的适配操作,非常方便,并且不会出现重复增加字段等操作,在开发过程中,我们只要知道了migrate的原理,就能很方便的使用起来了。
感谢阅读,希望能帮助到大家,谢谢大家对本站的支持!
-
本文向大家介绍python中使用mysql数据库详细介绍,包括了python中使用mysql数据库详细介绍的使用技巧和注意事项,需要的朋友参考一下 一、安装mysql 如果是windows 用户,mysql 的安装非常简单,直接下载安装文件,双击安装文件一步一步进行操作即可。 Linux 下的安装可能会更加简单,除了下载安装包进行安装外,一般的linux 仓库中都会有mysql ,我们只需要通过一
-
本文向大家介绍OpenStack 工作流workflows使用原理详细介绍,包括了OpenStack 工作流workflows使用原理详细介绍的使用技巧和注意事项,需要的朋友参考一下 Workflows 工作流是复杂的forms(表单)和tabs,每一个workflow必须包含 Workflow,Step 和 Action 下面举例讲解workflow用法: 接下来的例子讲解了数据是如何从urls
-
本文向大家介绍CentOS6.5 升级 Python 2.7 版本详细介绍,包括了CentOS6.5 升级 Python 2.7 版本详细介绍的使用技巧和注意事项,需要的朋友参考一下 CentOS6.5 升级 Python 2.7 版 概要 CentOS 6.5中预安装了Python-2.6.6,其比较新的Python-2.7.9(CentOS 7预装版本)主要区别在于新版本的Python导入了
-
本文向大家介绍CentOS 一键安装Openstack详细介绍,包括了CentOS 一键安装Openstack详细介绍的使用技巧和注意事项,需要的朋友参考一下 CentOS 一键安装Openstack 最近再看Openstack相关知识,一直想试试安装一下,可是参考了很多资料,并不如人意。由于一直用的Linux版本为CentOS,大部分Openstack安装都要求在Ubuntu上进行
-
问题内容: 我已经在Google Store中有一个应用程序。我正在使用具有3个表的内置数据库,并在应用程序首次启动时将其复制。现在,我想升级到该应用程序并添加另一个表。下面是我的代码。 我想问几个问题。上面的代码未升级。 现在,如果我是该应用程序的新用户,是否需要编辑旧数据库并制作另一个CKRecording表,并用放置在资产中的当前数据库替换该数据库,或者上述代码也适用于新用户? 问题答案:
-
本文向大家介绍OpenStack Keystone的基本概念详细介绍,包括了OpenStack Keystone的基本概念详细介绍的使用技巧和注意事项,需要的朋友参考一下 OpenStack Keystone的基本概念理解 Keystone简介 Keystone(OpenStack Identity Service)是OpenStack框架中,负责身份验证、服务规则和服务令牌的功能, 它实现了