
论Java Web应用中调优线程池的重要性

不论你是否关注,Java Web应用都或多或少的使用了线程池来处理请求。线程池的实现细节可能会被忽视,但是有关于线程池的使用和调优迟早是需要了解的。本文主要介绍Java线程池的使用和如何正确的配置线程池。
单线程
我们先从基础开始。无论使用哪种应用服务器或者框架(如Tomcat、Jetty等),他们都有类似的基础实现。Web服务的基础是套接字(socket),套接字负责监听端口,等待TCP连接,并接受TCP连接。一旦TCP连接被接受,即可从新创建的TCP连接中读取和发送数据。
为了能够理解上述流程,我们不直接使用任何应用服务器,而是从零开始构建一个简单的Web服务。该服务是大部分应用服务器的缩影。一个简单的单线程Web服务大概是这样的:
ServerSocket listener = new ServerSocket(8080);
try {
while (true) {
Socket socket = listener.accept();
try {
handleRequest(socket);
} catch (IOException e) {
e.printStackTrace();
}
}
} finally {
listener.close();
}
上述代码创建了一个 服务端套接字(ServerSocket) ,监听8080端口,然后循环检查这个套接字,查看是否有新的连接。一旦有新的连接被接受,这个套接字会被传入handleRequest方法。这个方法会将数据流解析成HTTP请求,进行响应,并写入响应数据。在这个简单的示例中,handleRequest方法仅仅实现数据流的读入,返回一个简单的响应数据。在通常实现中,该方法还会复杂的多,比如从数据库读取数据等。
final static String response =
“HTTP/1.0 200 OK/r/n” +
“Content-type: text/plain/r/n” +
“/r/n” +
“Hello World/r/n”;
public static void handleRequest(Socket socket) throws IOException {
// Read the input stream, and return “200 OK”
try {
BufferedReader in = new BufferedReader(
new InputStreamReader(socket.getInputStream()));
log.info(in.readLine());
OutputStream out = socket.getOutputStream();
out.write(response.getBytes(StandardCharsets.UTF_8));
} finally {
socket.close();
}
}
由于只有一个线程来处理请求,每个请求都必须等待前一个请求处理完成之后才能够被响应。假设一个请求响应时间为100毫秒,那么这个服务器的每秒响应数(tps)只有10。
多线程
虽然handleRequest方法可能阻塞在IO上,但是CPU仍然可以处理更多的请求。但是在单线程情况下,这是无法做到的。因此,可以通过创建多线程的方式,来提升服务器的并行处理能力。
public static class HandleRequestRunnable implements Runnable {
final Socket socket;
public HandleRequestRunnable(Socket socket) {
this.socket = socket;
}
public void run() {
try {
handleRequest(socket);
} catch (IOException e) {
e.printStackTrace();
}
}
}
ServerSocket listener = new ServerSocket(8080);
try {
while (true) {
Socket socket = listener.accept();
new Thread(new HandleRequestRunnable(socket)).start();
}
} finally {
listener.close();
}
这里,accept()方法仍然在主线程中调用,但是一旦TCP连接建立之后,将会创建一个新的线程来处理新的请求,既在新的线程中执行前文中的handleRequest方法。
通过创建新的线程,主线程可以继续接受新的TCP连接,且这些信求可以并行的处理。这个方式称为“每个请求一个线程(thread per request)”。当然,还有其他方式来提高处理性能,例如 NGINX 和 Node.js 使用的异步事件驱动模型,但是它们不使用线程池,因此不在本文的讨论范围。
在每个请求一个线程实现中,创建一个线程(和后续的销毁)开销是非常昂贵的,因为JVM和操作系统都需要分配资源。另外,上面的实现还有一个问题,即创建的线程数是不可控的,这将可能导致系统资源被迅速耗尽。
资源耗尽
每个线程都需要一定的栈内存空间。在最近的64位JVM中, 默认的栈大小 是1024KB。如果服务器收到大量请求,或者handleRequest方法执行很慢,服务器可能因为创建了大量线程而崩溃。例如有1000个并行的请求,创建出来的1000个线程需要使用1GB的JVM内存作为线程栈空间。另外,每个线程代码执行过程中创建的对象,还可能会在堆上创建对象。这样的情况恶化下去,将会超出JVM堆内存,并产生大量的垃圾回收操作,最终引发 内存溢出(OutOfMemoryErrors) 。
这些线程不仅仅会消耗内存,它们还会使用其他有限的资源,例如文件句柄、数据库连接等。不可控的创建线程,还可能引发其他类型的错误和崩溃。因此,避免资源耗尽的一个重要方式,就是避免不可控的数据结构。
顺便说下,由于线程栈大小引发的内存问题,可以通过-Xss开关来调整栈大小。缩小线程栈大小之后,可以减少每个线程的开销,但是可能会引发 栈溢出(StackOverflowErrors) 。对于一般应用程序而言,默认的1024KB过于富裕,调小为256KB或者512KB可能更为合适。Java允许的最小值是160KB。
线程池
为了避免持续创建新线程,可以通过使用简单的线程池来限定线程池的上限。线程池会管理所有线程,如果线程数还没有达到上限,线程池会创建线程到上限,且尽可能复用空闲的线程。
ServerSocket listener = new ServerSocket(8080);
ExecutorService executor = Executors.newFixedThreadPool(4);
try {
while (true) {
Socket socket = listener.accept();
executor.submit( new HandleRequestRunnable(socket) );
}
} finally {
listener.close();
}
在这个示例中,没有直接创建线程,而是使用了ExecutorService。它将需要执行的任务(需要实现Runnables接口)提交到线程池,使用线程池中的线程执行代码。示例中,使用线程数量为4的固定大小线程池来处理所有请求。这限制了处理请求的线程数量,也限制了资源的使用。
除了通过 newFixedThreadPool 方法创建固定大小线程池,Executors类还提供了 newCachedThreadPool 方法。复用线程池还是有可能导致不可控的线程数,但是它会尽可能使用之前已经创建的空闲线程。通常该类型线程池适合使用在不会被外部资源阻塞的短任务上。
工作队列
使用了固定大小线程池之后,如果所有的线程都繁忙,再新来一个请求将会发生什么呢?ThreadPoolExecutor使用一个队列来保存等待处理的请求,固定大小线程池默认使用无限制的链表。注意,这又可能引起资源耗尽问题,但只要线程处理的速度大于队列增长的速度就不会发生。然后前面示例中,每个排队的请求都会持有套接字,在一些操作系统中,这将会消耗文件句柄。由于操作系统会限制进程打开的文件句柄数,因此最好限制下工作队列的大小。
public static ExecutorService newBoundedFixedThreadPool(int nThreads, int capacity) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(capacity),
new ThreadPoolExecutor.DiscardPolicy());
}
public static void boundedThreadPoolServerSocket() throws IOException {
ServerSocket listener = new ServerSocket(8080);
ExecutorService executor = newBoundedFixedThreadPool(4, 16);
try {
while (true) {
Socket socket = listener.accept();
executor.submit( new HandleRequestRunnable(socket) );
}
} finally {
listener.close();
}
}
这里我们没有直接使用Executors.newFixedThreadPool方法来创建线程池,而是自己构建了ThreadPoolExecutor对象,并将工作队列长度限制为16个元素。
如果所有的线程都繁忙,新的任务将会填充到队列中,由于队列限制了大小为16个元素,如果超过这个限制,就需要由构造ThreadPoolExecutor对象时的最后一个参数来处理了。示例中,使用了 抛弃策略(DiscardPolicy) ,即当队列到达上限时,将抛弃新来的任务。初次之外,还有 中止策略(AbortPolicy) 和 调用者执行策略(CallerRunsPolicy) 。前者将抛出一个异常,而后者会再调用者线程中执行任务。
对于Web应用来说,最优的默认策略应该是抛弃或者中止策略,并返回一个错误给客户端(如 HTTP 503 错误)。当然也可以通过增加工作队列长度的方式,避免抛弃客户端请求,但是用户请求一般不愿意进行长时间的等待,且这样会更多的消耗服务器资源。工作队列的用途,不是无限制的响应客户端请求,而是平滑突发暴增的请求。通常情况下,工作队列应该是空的。
线程数调优
前面的示例展示了如何创建和使用线程池,但是,使用线程池的核心问题在于应该使用多少线程。首先,我们要确保达到线程上限时,不会引起资源耗尽。这里的资源包括内存(堆和栈)、打开文件句柄数量、TCP连接数、远程数据库连接数和其他有限的资源。特别的,如果线程任务是计算密集型的,CPU核心数量也是资源限制之一,一般情况下线程数量不要超过CPU核心数量。
由于线程数的选定依赖于应用程序的类型,可能需要经过大量性能测试之后,才能得出最优的结果。当然,也可以通过增加资源数的方式,来提升应用程序的性能。例如,修改JVM堆内存大小,或者修改操作系统的文件句柄上限等。然后,这些调整最终还是会触及理论上限。
利特尔法则
利特尔法则 描述了在稳定系统中,三个变量之间的关系。
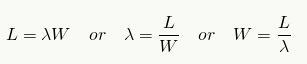
其中L表示平均请求数量,λ表示请求的频率,W表示响应请求的平均时间。举例来说,如果每秒请求数为10次,每个请求处理时间为1秒,那么在任何时刻都有10个请求正在被处理。回到我们的话题,就是需要使用10个线程来进行处理。如果单个请求的处理时间翻倍,那么处理的线程数也要翻倍,变成20个。
理解了处理时间对于请求处理效率的影响之后,我们会发现,通常理论上限可能不是线程池大小的最佳值。线程池上限还需要参考任务处理时间。
假设JVM可以并行处理1000个任务,如果每个请求处理时间不超过30秒,那么在最坏情况下,每秒最多只能处理33.3个请求。然而,如果每个请求只需要500毫秒,那么应用程序每秒可以处理2000个请求。
拆分线程池
在微服务或者面向服务架构(SOA)中,通常需要访问多个后端服务。如果其中一个服务性能下降,可能会引起线程池线程耗尽,从而影响对其他服务的请求。
应对后端服务失效的有效办法是隔离每个服务所使用的线程池。在这种模式下,仍然有一个分派的线程池,将任务分派到不同的后端请求线程池中。该线程池可能因为一个缓慢的后端而没有负载,而将负担转移到了请求缓慢后端的线程池中。
另外,多线程池模式还需要避免死锁问题。如果每个线程都阻塞在等待未被处理请求的结果上时,就会发生死锁。因此,多线程池模式下,需要了解每个线程池执行的任务和它们之间的依赖,这样可以尽可能避免死锁问题。
总结
即使没有在应用程序中直接使用线程池,它们也很有可能在应用程序中被应用服务器或者框架间接使用。 Tomcat 、 JBoss 、 Undertow 、 Dropwizard 等框架,都提供了调优线程池(servlet执行使用的线程池)的选项。
希望本文能够提升对线程池的了解,对大家学习有所帮助。
-
每个人我对使用线程池有一个误解。实际结果与该类的API描述不同。当我在线程池中使用时,它不重用线程,线程池等待构造函数中设置的KeepAliveTime,然后杀死这个线程并创建一个新线程。当我将KeepAliveTime设置为较小值时,比如1秒或更短,它会删除一个线程并重新创建它,但如果我设置一分钟,则不会创建新线程,因为不允许创建,队列已经满,所以所有任务都会被拒绝,但KeepAliveTime
-
如何从线程池中找到60%(或N%)的线程可用性?这背后的逻辑是什么? 父线程使用线程池线程生成多个网址,并等待所有子线程完成。 代码如下所示 父线程 子线程 用于跨线程通信的对象数据 在上述代码中,所需的线程硬编码为: 这种硬编码会导致线程池不足吗?如果线程池中没有可用的线程,会发生什么?如何在托管服务器的线程池中查找可用线程的总数? 谢谢。
-
本文向大家介绍为什么要用线程池? 相关面试题,主要包含被问及为什么要用线程池? 时的应答技巧和注意事项,需要的朋友参考一下 池化技术相比大家已经屡见不鲜了,线程池、数据库连接池、Http 连接池等等都是对这个思想的应用。池化技术的思想主要是为了减少每次获取资源的消耗,提高对资源的利用率。** 线程池提供了一种限制和管理资源(包括执行一个任务)。 每个线程池还维护一些基本统计信息,例如已完成任务的数
-
我的工作与Javawebapp与Apache Tomcat一起运行。Tomcat线程池的最大线程数为800,minSpareThread为25。当它运行时,它通常在给定时间运行大约400个线程。 比方说,我有一个计算成本很高的非阻塞任务,我必须在我的Tomcat应用程序中完成,在这个应用程序中,ForkJoinPool。commonPool用于更有效地解决任务。 因为我的ApacheTomcat应
-
主要内容:1 ScheduledThreadPoolExecutor的概述,2 ScheduledThreadPoolExecutor的重要属性,3 ScheduledFutureTask内部类,4 DelayedWorkQueue内部类,5 ScheduledThreadPoolExecutor的构造器,6 schedule一次性任务,6.1 triggerTime任务触发时间点,6.2 delayedExecute延迟/定期执行核心方法,,,,,,,此前我们学习了ThreadPoolExec
-
我使用线程池执行器,将其替换为旧版线程。 我创建了如下执行器: 这里的核心大小是maxpoolsize/5。我已经在应用程序启动时预先启动了所有核心线程,大约160个线程。 在传统设计中,我们创建并启动了大约670个线程。 但关键是,即使在使用Executor并创建和替换遗留设计之后,我们也不会得到更好的结果。 对于结果内存管理,我们使用Top命令来查看内存使用情况。对于时间,我们将System.