
对DataFrame数据中的重复行,利用groupby累加合并的方法详解

pandas读取一组数据,可能存在重复索引,虽然可以利用drop_duplicate直接删除,但是会删除重要信息。
比如同一ID用户,多次登录学习时间。要计算该用户总共‘'学习时间‘',就要把重复的ID的‘'学习时间‘'累加。
可以结合groupby和sum函数完成该操作。
html" target="_blank">实例如下:
新建一个DataFrame,计算每个 id 的总共学习时间。其中 id 为one/two的存在重复学习时间。先利用 groupby 按照键 id 分组,然后利用sum()函数求和,即可得到每个id的总共学习时间。
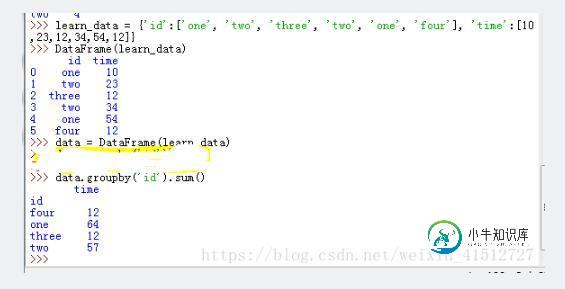
以上这篇对DataFrame数据中的重复行,利用groupby累加合并的方法详解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持小牛知识库。
-
问题内容: 如果我的数据框具有包含相同名称的列,是否可以将具有相同名称的列与某种功能(即求和)结合起来? 例如: 如何通过对列名称相同的每一行求和来折叠NY-WEB01列(有一堆重复的列,而不仅仅是NY-WEB01)? 问题答案: 我相信这可以满足您的要求: 或者,取决于df的长度,快3%至15%: 编辑:要将其扩展到总和之外,请使用(的缩写):
-
本文向大家介绍对python 合并 累加两个dict的实例详解,包括了对python 合并 累加两个dict的实例详解的使用技巧和注意事项,需要的朋友参考一下 比如说有两个dict:x和y 1.比较快的自己写的, 2.调用api,这个慢一点 以上这篇对python 合并 累加两个dict的实例详解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持呐喊教程。
-
我有一个熊猫DataFrame,我想通过使用Groupby并根据小时时间增量添加任意数量的列,并从第三列填充数据,将其转换为时间表(出于可视化目的)。 源数据帧可能如下所示: 我的目标是: 我无法得到的是(如果不使用循环手动构造),根据第一个数据帧中的唯一或小时范围添加任意数量的列(在groupby操作之后),然后根据第一个数据帧中的小时和楼层列计算每个列的值。 有什么想法吗?
-
本文向大家介绍mysql利用group_concat()合并多行数据到一行,包括了mysql利用group_concat()合并多行数据到一行的使用技巧和注意事项,需要的朋友参考一下 假设两个表a,b,b中通过字段id与a表关联,a表与b表为一对多的关系。假设b表中存在一字段name,现需要查询a表中的记录,同时获取存储在b表中的name信息,按照常规查询,b表中有多少记录,则会显示多少行,如果需
-
问题内容: 这个问题已经在这里有了答案 : 8年前关闭。 可能重复: 连接行值T-SQL 我是SQL Server的新手,曾经尝试过一些互联网上建议的技术,例如使用临时变量,XML路径等,但是所有这些都不满足我的要求。 我正在使用Toad for SQL Server 5.5版创建SQL脚本,而我用来查询数据库服务器的帐户仅具有READ访问权限。因此不能使用我相信的声明。 表名: 预期产量: 问题
-
问题内容: 我有一个临时数据库表,其中某些数据是重复的。 如上所示,有些行是多余的,可以合并为单个行而不会违反数据有效性。我想尽可能合并这样的行,结果应该像这样 如何做到这一点? 问题答案: 如果可以确保所有开始日期和结束日期都是连续的,请尝试以下操作: