
Spring Batch入门教程篇

SpringBatch介绍:
SpringBatch 是一个大数据量的并行处理框架。通常用于数据的离线迁移,和数据处理,⽀持事务、并发、流程、监控、纵向和横向扩展,提供统⼀的接⼝管理和任务管理;SpringBatch是SpringSource和埃森哲为了统一业界并行处理标准为广大开发者提供方便开发的一套框架。
官方地址:github.com/spring-projects/spring-batch
- SpringBatch 本身提供了重试,异常处理,跳过,重启、任务处理统计,资源管理等特性,这些特性开发者看重他的主要原因;
- SpringBatch 是一个轻量级的批处理框架;
- SpringBatch 结构分层,业务与处理策略、结构分离;
- 任务的运行的实例状态,执行数据,参数都会落地到数据库;
快速入门
pom.xml 添加
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-batch</artifactId> </dependency>
创建BatchConfig(可以是其他类名)
@Configuration
@EnableBatchProcessing
public class BatchConfig {
// tag::readerwriterprocessor[]
@Bean
public FlatFileItemReader<Person> flatFileItemReader() {
FlatFileItemReader<Person> reader = new FlatFileItemReader<>();
reader.setResource(new ClassPathResource("sample-data.csv"));
FixedLengthTokenizer fixedLengthTokenizer = new FixedLengthTokenizer();
reader.setLineMapper(new DefaultLineMapper<Person>() {{
setLineTokenizer(new DelimitedLineTokenizer() {{
setNames(new String[]{"firstName", "lastName"});
}});
setFieldSetMapper(new BeanWrapperFieldSetMapper<Person>() {{
setTargetType(Person.class);
}});
}});
return reader;
}
@Bean
public JdbcPagingItemReader<Person> jdbcPagingItemReader(DataSource dataSource) {
JdbcPagingItemReader<Person> reader = new JdbcPagingItemReader<>();
reader.setDataSource(dataSource);
reader.setFetchSize(100);
reader.setQueryProvider(new MySqlPagingQueryProvider() {{
setSelectClause("SELECT person_id,first_name,last_name");
setFromClause("from people");
setWhereClause("last_name=:lastName");
setSortKeys(new HashMap<String, Order>() {{
put("person_id", Order.ASCENDING);
}});
}});
reader.setParameterValues(new HashMap<String, Object>() {{
put("lastName", "DOE");
}});
reader.setRowMapper(new BeanPropertyRowMapper<>(Person.class));
return reader;
}
@Bean
public JdbcBatchItemWriter<Person> jdbcBatchItemWriter(DataSource dataSource) {
JdbcBatchItemWriter<Person> writer = new JdbcBatchItemWriter<>();
writer.setItemSqlParameterSourceProvider(new BeanPropertyItemSqlParameterSourceProvider<>());
writer.setSql("INSERT INTO people (first_name, last_name) VALUES (:firstName, :lastName)");
writer.setDataSource(dataSource);
return writer;
}
/*@Bean
public FlatFileItemWriter<Person> flatFileItemWriter(DataSource dataSource) {
FlatFileItemWriter<Person> writer = new FlatFileItemWriter<>();
writer.setAppendAllowed(true);
writer.setEncoding("UTF-8");
// writer.set(dataSource);
return writer;
}*/
// end::readerwriterprocessor[]
// tag::jobstep[]
@Bean
public Job importUserJob(JobBuilderFactory jobBuilderFactory, JobCompletionNotificationListener listener, Step step) {
return jobBuilderFactory.get("importUserJob")
.incrementer(new RunIdIncrementer())
.listener(listener)
.start(step)
.build();
}
@Bean
public Step step1(StepBuilderFactory stepBuilderFactory, PersonItemProcessor processor, ItemWriter jdbcBatchItemWriter, ItemReader flatFileItemReader) {
/*CompositeItemProcessor compositeItemProcessor = new CompositeItemProcessor();
compositeItemProcessor.setDelegates(Lists.newArrayList(processor, processor));*/
return stepBuilderFactory.get("step1")
.<Person, Person>chunk(10)
.reader(flatFileItemReader)
.processor(processor)
.writer(jdbcBatchItemWriter)
.build();
}
// end::jobstep[]
}
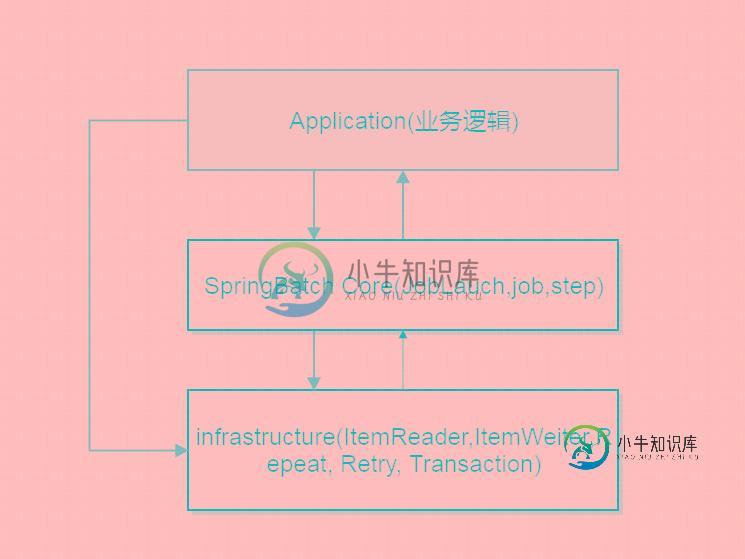
Spring Batch的分层架构
- Insfrastructure 策略管理:包括任务的失败重试,异常处理,事务,skip,以及数据的输入输出(文本文件,DB,Message)
- Core: springBatch 的核心,包括JobLauch,job,step等等
- Application: 业务处理,创建任务,决定任务的执行方式(定时任务,手动触发等)
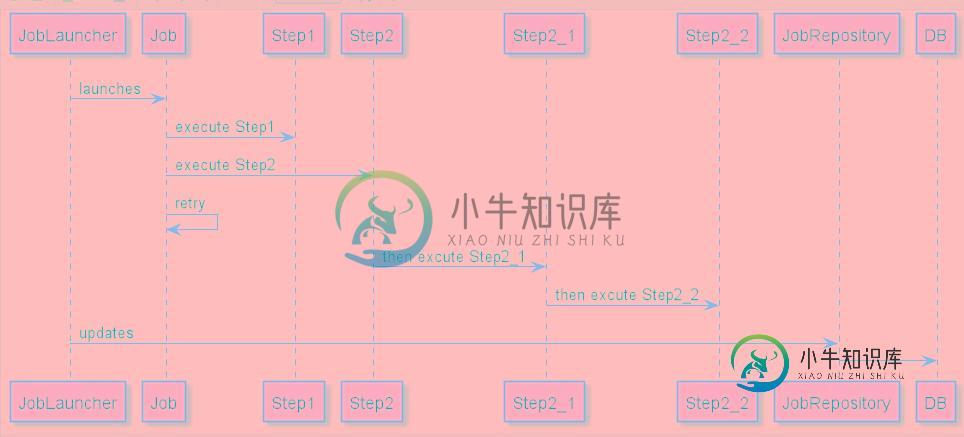
Spring Batch执行流程
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作能带来一定的帮助,如果有疑问大家可以留言交流,谢谢大家对小牛知识库的支持。
-
主要内容:面向读者,前提条件,问题反馈Spring Batch是一个轻量级框架,用于在开发企业应用程序中批处理应用程序。 本教程解释了Spring Batch的基本概念,并展示了如何在实际环境中使用它。 面向读者 本教程对于那些需要处理大量涉及诸如事务管理,作业处理统计,资源管理等重复操作的记录的专业人员来说尤其有用。Spring Batch是处理大容量的非常有效的框架 批量作业。 前提条件 Spring Batch建立在Spring
-
扩展由不同但相互联系的组件组成。组件可以包括 后台脚本,内容脚本,选项页,交互页面和各种逻辑文件。扩展组件是使用 Web 开发技术创建的:HTML,CSS 和 JavaScript。扩展的组件各有其功能,并且是可选的。 本教程将构建一个扩展,允许用户更改 developer.chrome.com 上任何页面的背景颜色。 我们将使用许多核心组件来介绍它们之间的关系。 首先,创建一个新目录来保存扩展名
-
主要内容:下载并运行ElasticSearch,使用REST API与Sense,文档管理(CRUD),由ID获取文档/索引,搜索,过滤,以下是纠正/补充内容:ElasticSearch是一个高度可扩展的开源搜索引擎并使用REST API,所以您值得拥有。 在本教程中,将介绍开始使用ElasticSearch的一些主要概念。 下载并运行ElasticSearch ElasticSearch可以从elasticsearch.org下载对应的文件格式,如和。下载并提取一个运行它的软件包之后不会容易得
-
我们常用的操作系统是微软的 Windows 或是苹果的 OS X,因为它容易操作,所以使用者很多。 其实还有一种操作系统,这个操作系统本身就是开源免费的,谁都可以免费使用和安装,它就是 linux。 可是国内很少有用户使用 linux,主要是这个需要学习,不然很难操作。 linux 系统入门学习教程,坚持“理论够用、侧重实用”的原则,用案例来讲解每个知识点,对 Linux 做了较为详尽的阐述,来帮
-
vux@2.x 推荐webpack+vue-loader方式的开发,如果要使用umd文件,请参照文档。不建议使用引入script的方式进行开发,因为它会带来一系列的开发、维护、效率、部署问题。 Life is short, use webpack. vux2 模板 vux2 模板 fork 自 webpack 模板,基本和官方同步。 默认为 webpack2 模板 npm install vue-
-
在本篇教程中,我们假定您已经安装好Scrapy。 如若不然,请参考 安装指南 。 接下来以 Open Directory Project(dmoz) (dmoz) 为例来讲述爬取。 本篇教程中将带您完成下列任务: 创建一个Scrapy项目 定义提取的Item 编写爬取网站的 spider 并提取 Item 编写 Item Pipeline 来存储提取到的Item(即数据) Scrapy由 Pyth
-
RGSS全称是Ruby Game Scripting System,意指Ruby 游戏脚本系统,是应用面向对象的脚本语言 Ruby 开发 Windows 2D 游戏的系统。
-
本教程适合不熟悉 Java 技术,但想成为高效的 Java 程序员的软件开发人员。耐心学完本教程之后,即可使用 Java 语言和平台正常地执行面向对象编程 (OOP) 和实际应用程序开发。