
Select count(*)、Count(1)和Count(列)的区别及执行方式

在SQL Server中Count(*)或者Count(1)或者Count([列])或许是最常用的聚合函数。很多人其实对这三者之间是区分不清的。本文会阐述这三者的作用,关系以及背后的原理。
往常我经常会看到一些所谓的优化建议不使用Count(* )而是使用Count(1),从而可以提升性能,给出的理由是Count( *)会带来全表扫描。而实际上如何写Count并没有区别。
Count(1)和Count(*)实际上的意思是,评估Count()中的表达式是否为NULL,如果为NULL则不计数,而非NULL则会计数。比如我们看代码1所示,在Count中指定NULL(优化器不允许显式指定NULL,因此需要赋值给变量才能指定)。
DECLARE @xx INT SET @xx=NULL SELECT COUNT(@xx) FROM [AdventureWorks2012].[Sales].[SalesOrderHeader]
代码清单1.Count中指定NULL
由于所有行都为NULL,则结果全不计数为0,结果如图1所示。

图1.显而易见,结果为0
因此当你指定Count(*) 或者Count(1)或者无论Count(‘anything')时结果都会一样,因为这些值都不为NULL,如图2所示。
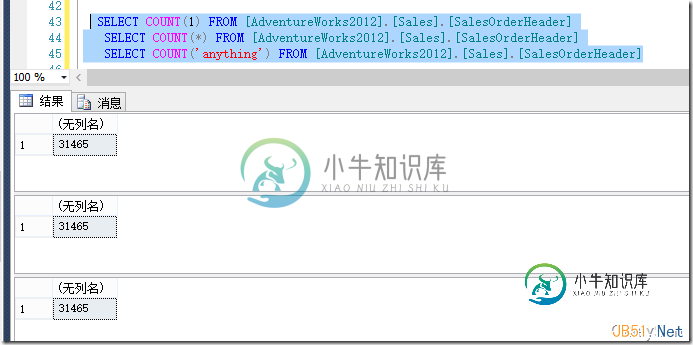
图2.只要在Count中指定非NULL表达式,结果没有任何区别
那Count列呢?
对于Count(列)来说,同样适用于上面规则,评估列中每一行的值是否为NULL,如果为NULL则不计数,不为NULL则计数。因此Count(列)会计算列或这列的组合不为空的计数。
那Count(*)具体如何执行?
前面提到Count( )有不为NULL的值时,在SQL Server中只需要找出具体表中不为NULL的行数即可,也就是所有行(如果一行值全为NULL则该行相当于不存在)。那么最简单的执行办法是找一列NOT NULL的列,如果该列有索引,则使用该索引,当然,为了性能,SQL Server会选择最窄的索引以减少IO。
我们在Adventureworks2012示例数据库的[Person].[Address]表上删除所有的非聚集索引,在ModifyDate这个数据类型为DateTime的列上建立索引,我们看执行计划,如图3所示:
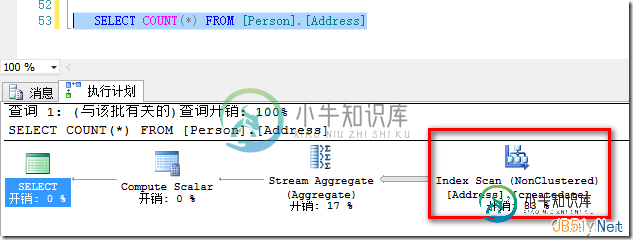
图3.使用了CreateDate的索引
我们继续在StateProvinceID列上建立索引,该列为INT列,占4字节,相比之前8字节 DateTime类型的列更短,因此SQL Server选择了StateProvinceID索引。如图4所示。
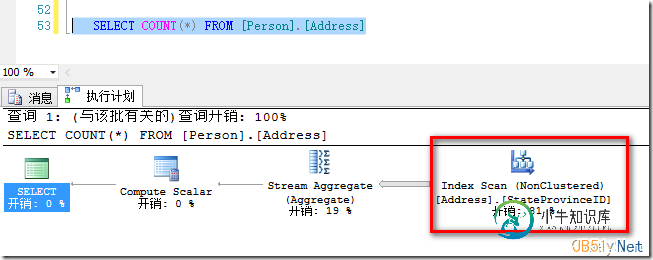
图4.选择了更短的StateProvinceID索引
因此,如果某个表上Count(*)用的比较多时,考虑在一个最短的列建立一个单列索引,会极大的提升性能。
-
本文向大家介绍count(*),count(1)和count(列名)的区别?相关面试题,主要包含被问及count(*),count(1)和count(列名)的区别?时的应答技巧和注意事项,需要的朋友参考一下 count(*),count(1)在统计的时候不会忽略Null,count(列名)在统计的时候会忽略Null。若列名为主键,count(列名)会比count(1),count(*)快,反之则c
-
主要内容:1 几种count查询的区别,2 优化COUNT()查询MySQL的count(*)、count(1) 和count(字段)的区别以及count()查询优化手段。 1 几种count查询的区别 count()是一个聚合函数,对于返回的结果集,一行行地判断,如果count函数的参数不是NULL,累计值就加1,否则不加。最后返回累计值。 count(*)、count(主键id)和count(1) 都表示返回满足条件的结果集的总行数;而count(字段),则
-
问题内容: 和,mysql有什么区别。 问题答案: 计算结果集中的所有行(如果使用GROUP BY,则为组)。 只计算不为空的那些行。即使没有NULL值,在某些情况下这也会变慢,因为必须检查该值(除非该列不可为空)。 与1 相同,因为1永远不能为NULL。 要查看结果的差异,您可以尝试以下小实验: 结果:
-
问题内容: 我有以下查询: 会有什么区别,如果我更换,所有呼叫count(column_name)到count(*)? 这个问题的灵感源于我如何在Oracle的表中找到重复的值?。 为了澄清接受的答案(也许我的问题),替换count(column_name)与count(*)将在包含一个结果返回额外的行null和计数null列中的值。 问题答案: 计数为而不是 [编辑]添加了此代码,以便人们可以运
-
问题内容: 只是想知道您是否有人用光了,性能是否存在明显差异,或者这仅仅是过去的日子所养成的传统习惯? 具体的数据库是。 问题答案: 没有区别。 原因: 在线书籍上说“ ” “ 1”是非空表达式:因此与相同。优化器可以识别它是什么:琐碎的。 与或相同 例子: 相同的IO,相同的计划,作品 编辑,2011年8月 关于DBA.SE的类似问题。 编辑,2011年12月 在ANSI-92中专门提到(请查找
-
问题内容: 我有一个这样的表: 我现在想获取所有具有多个值的条目。预期结果将是: 我试图做到这一点是这样的: 但是甲骨文不喜欢它。 所以我尝试了这个 …没有成功。 有任何想法吗? 问题答案: 使用该子句比较聚合。 另外,您需要根据要汇总的内容进行分组,以使查询正常运行。以下是一个开始,但是由于您缺少group by子句,因此仍然无法正常工作。您到底想算什么?