
在Python中使用NLTK库实现对词干的提取的教程

什么是词干提取?
在语言形态学和信息检索里,词干提取是去除词缀得到词根的过程─—得到单词最一般的写法。对于一个词的形态词根,词干并不需要完全相同;相关的词映射到同一个词干一般能得到满意的结果,即使该词干不是词的有效根。从1968年开始在计算机科学领域出现了词干提取的相应算法。很多搜索引擎在处理词汇时,对同义词采用相同的词干作为查询拓展,该过程叫做归并。
一个面向英语的词干提取器,例如,要识别字符串“cats”、“catlike”和“catty”是基于词根“cat”;“stemmer”、“stemming”和“stemmed”是基于词根“stem”。一根词干提取算法可以简化词 “fishing”、“fished”、“fish”和“fisher” 为同一个词根“fish”。
技术方案的选择
Python和R是数据分析的两种主要语言;相对于R,Python更适合有大量编程背景的数据分析初学者,尤其是已经掌握Python语言的程序员。所以我们选择了Python和NLTK库(Natual Language Tookit)作为文本处理的基础框架。此外,我们还需要一个数据展示工具;对于一个数据分析师来说,数据库的冗繁安装、连接、建表等操作实在是不适合进行快速的数据分析,所以我们使用Pandas作为结构化数据和分析工具。
环境搭建
我们使用的是Mac OS X,已预装Python 2.7.
安装NLTK
sudo pip install nltk
安装Pandas
sudo pip install pandas
对于数据分析来说,最重要的是分析结果,iPython notebook是必备的一款利器,它的作用在于可以保存代码的执行结果,例如数据表格,下一次打开时无需重新运行即可查看。
安装iPython notebook
sudo pip install ipython
创建一个工作目录,在工作目录下启动iPython notebook,服务器会开启http://127.0.0.1:8080页面,并将创建的代码文档保存在工作目录之下。
mkdir Codes cd Codes ipython notebook
文本处理
数据表创建
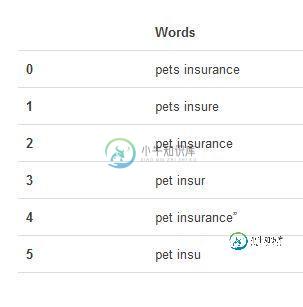
使用Pandas创建数据表 我们使用得到的样本数据,建立DataFrame——Pandas中一个支持行、列的2D数据结构。
from pandas import DataFrame import pandas as pd d = ['pets insurance','pets insure','pet insurance','pet insur','pet insurance"','pet insu'] df = DataFrame(d) df.columns = ['Words'] df
显示结果
NLTK分词器介绍
RegexpTokenizer:正则表达式分词器,使用正则表达式对文本进行处理,就不多作介绍。
PorterStemmer:波特词干算法分词器,原理可看这里:http://snowball.tartarus.org/algorithms/english/stemmer.html" target="_blank">html
第一步,我们创建一个去除标点符号等特殊字符的正则表达式分词器:
import nltk tokenizer = nltk.RegexpTokenizer(r'w+')
接下来,对准备好的数据表进行处理,添加词干将要写入的列,以及统计列,预设默认值为1:
df["Stemming Words"] = "" df["Count"] = 1
读取数据表中的Words列,使用波特词干提取器取得词干:
j = 0
while (j <= 5):
for word in tokenizer.tokenize(df["Words"][j]):
df["Stemming Words"][j] = df["Stemming Words"][j] + " " + nltk.PorterStemmer().stem_word(word)
j += 1
df
Good!到这一步,我们已经基本上实现了文本处理,结果显示如下:

分组统计
在Pandas中进行分组统计,将统计表格保存到一个新的DataFrame结构uniqueWords中:
uniqueWords = df.groupby(['Stemming Words'], as_index = False).sum().sort(['Count']) uniqueWords

注意到了吗?依然还有一个pet insu未能成功处理。
拼写检查
对于用户拼写错误的词语,我们首先想到的是拼写检查,针对Python我们可以使用enchant:
sudo pip install enchant
使用enchant进行拼写错误检查,得到推荐词:
import enchant
from nltk.metrics import edit_distance
class SpellingReplacer(object):
def __init__(self, dict_name='en', max_dist=2):
self.spell_dict = enchant.Dict(dict_name)
self.max_dist = 2
def replace(self, word):
if self.spell_dict.check(word):
return word
suggestions = self.spell_dict.suggest(word)
if suggestions and edit_distance(word, suggestions[0]) <=
self.max_dist:
return suggestions[0]
else:
return word
from replacers import SpellingReplacer
replacer = SpellingReplacer()
replacer.replace('insu')
'insu'
但是,结果依然不是我们预期的“insur”。能不能换种思路呢?
算法特殊性
用户输入非常重要的特殊性来自于行业和使用场景。采取通用的英语大词典来进行拼写检查,无疑是行不通的,并且某些词语恰恰是拼写正确,但本来却应该是另一个词。但是,我们如何把这些背景信息和数据分析关联起来呢?
经过一番思考,我认为最重要的参考库恰恰就在已有的数据分析结果中,我们回来看看:

已有的5个“pet insur”,其实就已经给我们提供了一份数据参考,我们已经可以对这份数据进行聚类,进一步除噪。
相似度计算
对已有的结果进行相似度计算,将满足最小偏差的数据归类到相似集中:
import Levenshtein
minDistance = 0.8
distance = -1
lastWord = ""
j = 0
while (j < 1):
lastWord = uniqueWords["Stemming Words"][j]
distance = Levenshtein.ratio(uniqueWords["Stemming Words"][j], uniqueWords["Stemming Words"][j + 1])
if (distance > minDistance):
uniqueWords["Stemming Words"][j] = uniqueWords["Stemming Words"][j + 1]
j += 1
uniqueWords
查看结果,已经匹配成功!

最后一步,重新对数据结果进行分组统计:
uniqueWords = uniqueWords.groupby(['Stemming Words'], as_index = False).sum() uniqueWords
到此,我们已经完成了初步的文本处理。

-
我是新的Python和nltk。我已经将代码从https://gist.github.com/alexbowe/879414转换为下面给定的代码,使其运行于许多文档/文本块。但我得到了以下错误 有人能帮我解决这个问题吗。我必须从数以百万计的产品评论中提取名词短语。我使用了使用Java的Standford NLP工具包,但速度非常慢,所以我认为在python中使用nltk会更好。如果有更好的解决方案
-
我试图从文本或语料库中提取关键词。这些不是最常见的词,而是最“关于”文本的词。我有一个比较示例,我生成的列表与示例列表非常不同。你能给我一个指针来生成一个很好的关键字列表,其中不包括像“you”和“tis”这样的低义词吗? 我用“罗密欧与朱丽叶”作为我的文本。我的做法(见斯科特 我收到了很多像“你”、“她”和“它”这样的词,但它们并没有出现在它们的列表中,我也没有收到像“放逐”和“教堂墓地”这样的
-
问题内容: 在Java中是否有任何可阻止的库! 问题答案: 在其网站上有Porter的词干提取器的实现。该代码不是Java风格的代码,但是它可以实现预期的功能,而且它只是一个类。
-
本文向大家介绍在Python中使用NLTK删除停用词,包括了在Python中使用NLTK删除停用词的使用技巧和注意事项,需要的朋友参考一下 当计算机处理自然语言时,某些极端通用的单词似乎在帮助选择符合用户需求的文档方面几乎没有值,因此完全从词汇表中排除了。这些单词称为停用词。 例如,如果您输入的句子为- 停止单词删除后,您将获得输出- NLTK收集了这些停用词,我们可以将其从任何给定的句子中删除。
-
问题内容: 我正在尝试从文本中提取人名。 有人有推荐的方法吗? 这就是我尝试过的(下面的代码):我正在使用查找所有标记为人的东西,然后生成该人所有NNP部分的列表。我正在跳过只有一个NNP可以避免抓住一个姓氏的人。 我得到了不错的结果,但是想知道是否有更好的方法来解决这个问题。 码: 输出: 除了维珍银河,这都是有效的输出。当然,在本文中了解维珍银河不是人的名字是很困难的(也许是不可能的)部分。
-
NLTK书中有几个单词计数的例子,但实际上它们不是单词计数,而是标记计数。例如,第1章“计算词汇”中说,下面给出了一个单词计数: 然而,它没有-它给出了一个单词和标点符号计数。你怎样才能得到一个真正的字数(忽略标点符号)? 同样,如何获得一个单词中的平均字符数?显而易见的答案是: 但是,这将关闭,因为: len(文本的字符串)是一个字符计数,包括空格 我是不是遗漏了什么?这一定是一个非常常见的NL