
利用Python进行数据可视化常见的9种方法!超实用!

前言
如同艺术家们用绘画让人们更贴切的感知世界,数据可视化也能让人们更直观的传递数据所要表达的信息。
我们今天就分享一下如何用 Python 简单便捷的完成数据可视化。
其实利用 Python 可视化数据并不是很麻烦,因为 Python 中有两个专用于可视化的库 matplotlib 和 seaborn 能让我们很容易的完成任务。
- Matplotlib:基于Python的绘图库,提供完全的 2D 支持和部分 3D 图像支持。在跨平台和互动式环境中生成高质量数据时,matplotlib 会很有帮助。也可以用作制作动画。
- Seaborn:该 Python 库能够创建富含信息量和美观的统计图形。Seaborn 基于 matplotlib,具有多种特性,比如内置主题、调色板、可以可视化单变量数据、双变量数据,线性回归数据和数据矩阵以及统计型时序数据等,能让我们创建复杂的可视化图形。
我们用 Python 可以做出哪些可视化图形?
那么这里可能有人就要问了,我们为什么要做数据可视化?比如有下面这个图表:
当然如果你把这张图表丢给别人,他们倒是也能看懂,但无法很直观的理解其中的信息,而且这种形式的图表看上去也比较 low,这个时候我们如果换成直观又美观的可视化图形,不仅能突显逼格,也能让人更容易的看懂数据。
下面我们就用上面这个简单的数据集作为例子,展示用 Python 做出9种可视化效果,并附有相关代码。
导入数据集
import matplotlib.pyplot as plt
import pandas as pd
df=pd.read_excel("E:/First.xlsx", "Sheet1")
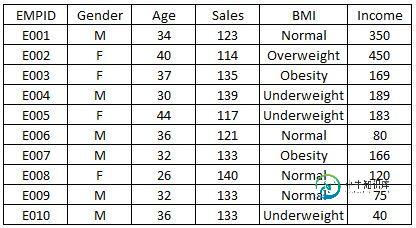
可视化为直方图
fig=plt.figure() #Plots in matplotlib reside within a figure object, use plt.figure to create new figure
#Create one or more subplots using add_subplot, because you can't create blank figure
ax = fig.add_subplot(1,1,1)
#Variable
ax.hist(df['Age'],bins = 7) # Here you can play with number of bins
Labels and Tit
plt.title('Age distribution')
plt.xlabel('Age')
plt.ylabel('#Employee')
plt.show()
可视化为箱线图
import matplotlib.pyplot as plt import pandas as pd fig=plt.figure() ax = fig.add_subplot(1,1,1) #Variable ax.boxplot(df['Age']) plt.show()

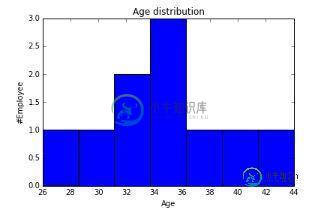
可视化为小提琴图
import seaborn as sns sns.violinplot(df['Age'], df['Gender']) #Variable Plot sns.despine()
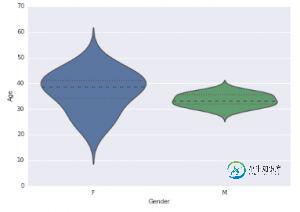
可视化为条形图
var = df.groupby('Gender').Sales.sum() #grouped sum of sales at Gender level
fig = plt.figure()
ax1 = fig.add_subplot(1,1,1)
ax1.set_xlabel('Gender')
ax1.set_ylabel('Sum of Sales')
ax1.set_title("Gender wise Sum of Sales")
var.plot(kind='bar')
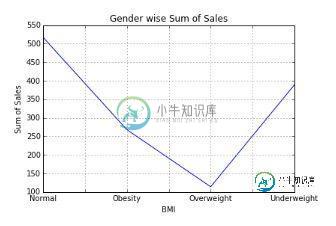
可视化为折线图
var = df.groupby('BMI').Sales.sum()
fig = plt.figure()
ax1 = fig.add_subplot(1,1,1)
ax1.set_xlabel('BMI')
ax1.set_ylabel('Sum of Sales')
ax1.set_title("BMI wise Sum of Sales")
var.plot(kind='line')
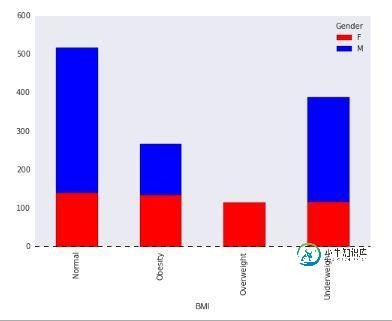
可视化为堆叠柱状图
var = df.groupby(['BMI','Gender']).Sales.sum() var.unstack().plot(kind='bar',stacked=True, color=['red','blue'], grid=False)
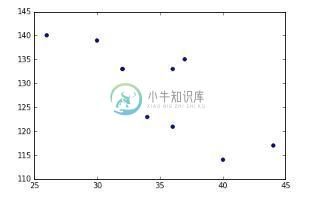
可视化为散点图
fig = plt.figure() ax = fig.add_subplot(1,1,1) ax.scatter(df['Age'],df['Sales']) #You can also add more variables here to represent color and size. plt.show()
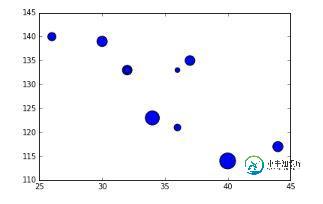
可视化为泡泡图
fig = plt.figure() ax = fig.add_subplot(1,1,1) ax.scatter(df['Age'],df['Sales'], s=df['Income']) # Added third variable income as size of the bubble plt.show()
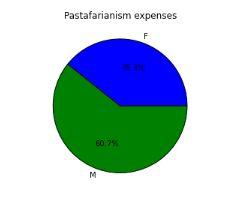
可视化为饼状图
var=df.groupby(['Gender']).sum().stack()
temp=var.unstack()
type(temp)
x_list = temp['Sales']
label_list = temp.index
pyplot.axis("equal") #The pie chart is oval by default. To make it a circle use pyplot.axis("equal")
#To show the percentage of each pie slice, pass an output format to the autopctparameter
plt.pie(x_list,labels=label_list,autopct="%1.1f%%")
plt.title("Pastafarianism expenses")
plt.show()
可视化为热度图
import numpy as np
#Generate a random number, you can refer your data values also
data = np.random.rand(4,2)
rows = list('1234') #rows categories
columns = list('MF') #column categories
fig,ax=plt.subplots()
#Advance color controls
ax.pcolor(data,cmap=plt.cm.Reds,edgecolors='k')
ax.set_xticks(np.arange(0,2)+0.5)
ax.set_yticks(np.arange(0,4)+0.5)
# Here we position the tick labels for x and y axis
ax.xaxis.tick_bottom()
ax.yaxis.tick_left()
#Values against each labels
ax.set_xticklabels(columns,minor=False,fontsize=20)
ax.set_yticklabels(rows,minor=False,fontsize=20)
plt.show()
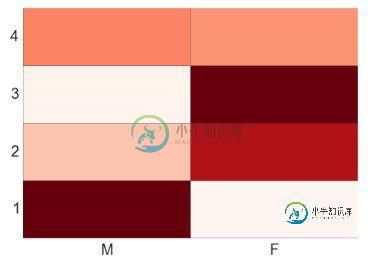
你也可以自己试着根据两个变量比如性别(X 轴)和 BMI(Y 轴)绘出热度图。
结语
本文我们分享了如何利用 Python 及 matplotlib 和 seaborn 库制作出多种多样的可视化图形。通过上面的例子,我们应该可以感受到利用可视化能多么美丽的展示数据。而且和其它语言相比,使用 Python 进行可视化更容易简便一些。
好了,以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,如果有疑问大家可以留言交流,谢谢大家对小牛知识库的支持。
参考资料:
https://www.analyticsvidhya.com/blog/2015/05/data-visualization-python/
-
本文向大家介绍Python数据可视化:箱线图多种库画法,包括了Python数据可视化:箱线图多种库画法的使用技巧和注意事项,需要的朋友参考一下 概念 箱线图通过数据的四分位数来展示数据的分布情况。例如:数据的中心位置,数据间的离散程度,是否有异常值等。 把数据从小到大进行排列并等分成四份,第一分位数(Q1),第二分位数(Q2)和第三分位数(Q3)分别为数据的第25%,50%和75%的数字。 四分位
-
本文向大家介绍python如何爬取网站数据并进行数据可视化,包括了python如何爬取网站数据并进行数据可视化的使用技巧和注意事项,需要的朋友参考一下 前言 爬取拉勾网关于python职位相关的数据信息,并将爬取的数据已csv各式存入文件,然后对csv文件相关字段的数据进行清洗,并对数据可视化展示,包括柱状图展示、直方图展示、词云展示等并根据可视化的数据做进一步的分析,其余分析和展示读者可自行发挥
-
本文向大家介绍用Python解析XML的几种常见方法的介绍,包括了用Python解析XML的几种常见方法的介绍的使用技巧和注意事项,需要的朋友参考一下 一、简介 XML(eXtensible Markup Language)指可扩展标记语言,被设计用来传输和存储数据,已经日趋成为当前许多新生技术的核心,在不同的领域都有着不同的应用。它是web发展到一定阶段的必然产物,既具有SGML的
-
不知道大伙有没有看到过这一句话:“中国(疫苗研发)非常困难,因为在中国我们没有办法做第三期临床试验,因为没有病人了。”这句话是中国工程院院士钟南山在上海科技大学2021届毕业典礼上提出的。这句话在全网流传,被广大网友称之为“凡尔赛”发言。今天让我们用数据来看看这句话是不是“凡尔赛”本赛。在开始之前我们先来说说今天要用到的python库吧!1.数据获取部分requests lxml json openpyxl2.数据可视化部分pandas pyecharts(可视化库)
-
大数据面临数据规模大、数据变化快、数据类型多、价值密度低4个挑战,而传统的数据可视化工具难以应对。传统的数据可视化工具仅仅将数据加以组合,通过不同的展现方式提供给用户,用于发现数据之间的关联信息。近年来,随着云和大数据时代的来临,数据可视化产品已经不再满足于使用传统的数据可视化工具来对数据仓库中的数据抽取、归纳并简单的展现。新型的数据可视化产品必须满足互联网爆发的大数据需求,必须快速的收集、筛选、
-
统计图表是最早的数据可视化形式之一,作为基本的可视化元素仍然被广泛的使用。对于很多复杂的大型可视化系统来说,这类图表更是作为基本的组成元素而不可或缺。同时,随着大数据可视化渲染技术的发展,涌现出很多优秀的开源图表库,例如ECharts、highcharts、LoongChart等,可制作更直观漂亮的图表。 表达内容 图表类型 描述 项目 柱状图/条形图(column/Bar) 表现多个类目数据的大