
使用matlab或python将txt文件转为excel表格

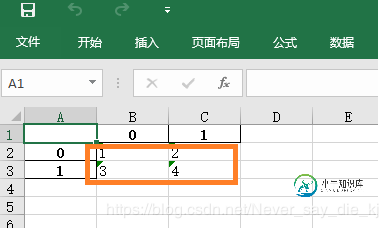
假设txt文件为:

一、matlab代码
data=importdata('data.txt');
xlswrite('data.xls',data);
二、python代码
利用pandas的DataFrame输出为Excel【但是输出会有索引】
结果为:
import numpy as np import pandas as pd def getData(path): with open(path, 'r') as file: data = [] for line in file.readlines(): # strip()方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列 # split()函数默认可以按空格分割,并且把结果中的空字符串删除掉,留下有用信息 rowline = line.strip().split() data.append(rowline) #将列表转为numpy数组 temp=np.array(data) return temp def printExcel(data): #numpy数组转为pandas的DataFrame数据 data_pd=pd.DataFrame(data) writer=pd.ExcelWriter('data.xlsx') data_pd.to_excel(writer) writer.save() printExcel(getData('data.txt'))
使用xlrd、xlwt来操作excel
windows下载:
pip install xlrd pip Install xlwt
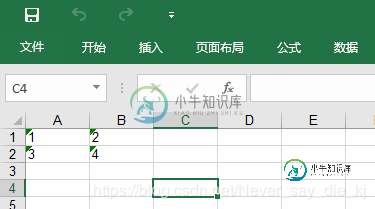
结果:
代码:
import numpy as np
import pandas as pd
import xlrd,xlwt
def getData(path):
with open(path, 'r') as file:
data = []
for line in file.readlines():
# strip()方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列
# split()函数默认可以按空格分割,并且把结果中的空字符串删除掉,留下有用信息
rowline = line.strip().split()
data.append(rowline)
#将列表转为numpy数组
temp=np.array(data)
return temp
def printExcel(data):
f=xlwt.Workbook() #创建工作簿
sheet=f.add_sheet('sheet1')
for i in range(len(data)):
for j in range(len(data[i])):
sheet.write(i,j,data[i][j])
f.save('data1.xls')
printExcel(getData('data.txt'))
总结
以上所述是小编给大家介绍的使用matlab或python将txt文件转为excel表格,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对小牛知识库网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!
-
本文向大家介绍python利用pandas将excel文件转换为txt文件的方法,包括了python利用pandas将excel文件转换为txt文件的方法的使用技巧和注意事项,需要的朋友参考一下 python将数据换为txt的方法有很多,可以用xlrd库实现。本人比较懒,不想按太多用的少的插件,利用已有库pandas将excel文件转换为txt文件。 直接上代码: 说明:xxx_dir带目标文件名
-
问题内容: 所以我想将一个简单的制表符分隔的文本文件转换为一个csv文件。如果我使用string.split(’\ n’)将txt文件转换为字符串,则会得到一个列表,其中每个列表项都是字符串,每列之间带有’\ t’。我当时以为我可以用逗号替换’\ t’,但它不会像清单中的字符串一样对待字符串,并允许我使用string.replace。这是我的代码的开始,仍然需要解析选项卡“ \ t”的方法。 问题
-
本文向大家介绍Python将列表数据写入文件(txt, csv,excel),包括了Python将列表数据写入文件(txt, csv,excel)的使用技巧和注意事项,需要的朋友参考一下 写入txt文件 写入csv文件 写入excel文件 以上所述是小编给大家介绍的Python将列表数据写入文件(txt, csv,excel)详解整合,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回
-
找不到很多这个确切用例的例子。基本上,我有两个目录,其中应该包含相同的文件,混合了。xlsx文件和。txt文件。我编写了一系列代码来比较。xlsx文件很好,还可以返回它发现的任何不匹配(行、列)的坐标。 我的代码似乎有一个问题做同样的文本文件,我可以通过excel手动打开这个罚款,这是一个标签分隔的文本文件。 当我尝试将其转换为XSSFWorkbook时,它不喜欢,其中文件excelFile1是我
-
在这里你可以看到我正在处理的一些文件。 与我最相似的问题是这个问题(将一个文本文件文件夹合并到一个CSV中,每个内容都在一个单元格中),但我无法实现那里提出的任何解决方案。 我尝试的最后一个是Nathaniel Verhaaren在前面提到的问题中提出的Python代码,但我得到了与问题作者完全相同的错误(即使在实施了一些建议之后): 与我类似的其他问题(例如,Python:将多个。txt文件解析
-
问题内容: 我正在尝试使用iText库将.txt文件转换为.pdf文件。我面临的问题如下: 我在txt文件中有清晰的格式,与此类似: 在输出中,格式消失了,看起来像这样: 代码如下: 我还尝试使用IDENTITY_H创建BaseFont,但是它不起作用。我猜这是关于编码或类似的东西。你怎么看?我用完了解决方案… 谢谢 LE:正如艾伦(Alan)以及iText页面上的教程所建议的那样,除了我现有的代