
python爬取天气数据的实例详解

就在前几天还是二十多度的舒适温度,今天一下子就变成了个位数,小编已经感受到冬天寒风的无情了。之前对获取天气都是数据上的搜集,做成了一个数据表后,对温度变化的感知并不直观。那么,我们能不能用python中的方法做一个天气数据分析的图形,帮助我们更直接的看出天气变化呢?
使用pygal绘图,使用该模块前需先安装pip install pygal,然后导入import pygal
bar = pygal.Line() # 创建折线图
bar.add('最低气温', lows) #添加两线的数据序列
bar.add('最高气温', highs) #注意lows和highs是int型的列表
bar.x_labels = daytimes
bar.x_labels_major = daytimes[::30]
bar.x_label_rotation = 45
bar.title = cityname+'未来七天气温走向图' #设置图形标题
bar.x_title = "日期" #x轴标题
bar.y_title = "气温(摄氏度)" # y轴标题
bar.legend_at_bottom = True
bar.show_x_guides = False
bar.show_y_guides = True
bar.render_to_file('temperate1.svg') # 将图像保存为SVG文件,可通过浏览器
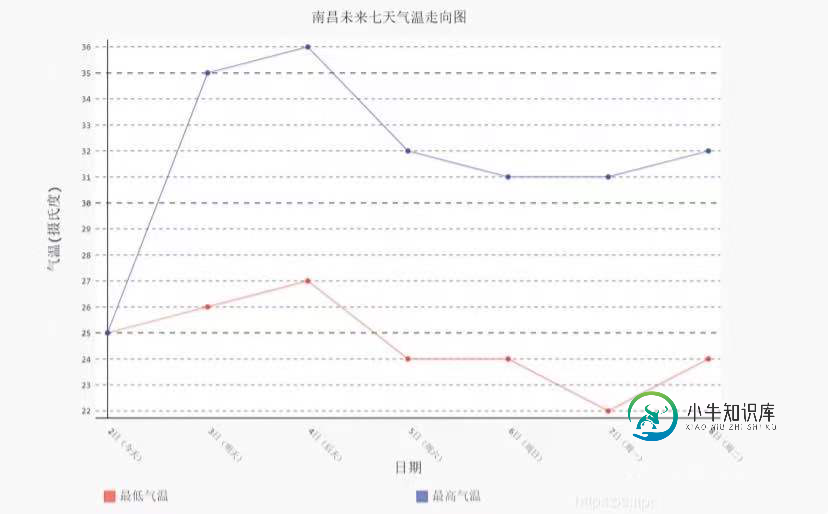
最终生成的图形如下图所示,直观的显示了天气情况:
完整代码
import csv
import sys
import urllib.request
from bs4 import BeautifulSoup # 解析页面模块
import pygal
import cityinfo
cityname = input("请输入你想要查询天气的城市:")
if cityname in cityinfo.city:
citycode = cityinfo.city[cityname]
else:
sys.exit()
url = '非常抱歉,网页无法访问' + citycode + '.shtml'
header = ("User-Agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36") # 设置头部信息
http_handler = urllib.request.HTTPHandler()
opener = urllib.request.build_opener(http_handler) # 修改头部信息
opener.addheaders = [header]
request = urllib.request.Request(url) # 制作请求
response = opener.open(request) # 得到应答包
html = response.read() # 读取应答包
html = html.decode('utf-8') # 设置编码,否则会乱码
# 根据得到的页面信息进行初步筛选过滤
final = [] # 初始化一个列表保存数据
bs = BeautifulSoup(html, "html.parser") # 创建BeautifulSoup对象
body = bs.body
data = body.find('div', {'id': '7d'})
print(type(data))
ul = data.find('ul')
li = ul.find_all('li')
# 爬取自己需要的数据
i = 0 # 控制爬取的天数
lows = [] # 保存低温
highs = [] # 保存高温
daytimes = [] # 保存日期
weathers = [] # 保存天气
for day in li: # 便利找到的每一个li
if i < 7:
temp = [] # 临时存放每天的数据
date = day.find('h1').string # 得到日期
#print(date)
temp.append(date)
daytimes.append(date)
inf = day.find_all('p') # 遍历li下面的p标签 有多个p需要使用find_all 而不是find
#print(inf[0].string) # 提取第一个p标签的值,即天气
temp.append(inf[0].string)
weathers.append(inf[0].string)
temlow = inf[1].find('i').string # 最低气温
if inf[1].find('span') is None: # 天气预报可能没有最高气温
temhigh = None
temperate = temlow
else:
temhigh = inf[1].find('span').string # 最高气温
temhigh = temhigh.replace('℃', '')
temperate = temhigh + '/' + temlow
# temp.append(temhigh)
# temp.append(temlow)
lowStr = ""
lowStr = lowStr.join(temlow.string)
lows.append(int(lowStr[:-1])) # 以上三行将低温NavigableString转成int类型并存入低温列表
if temhigh is None:
highs.append(int(lowStr[:-1]))
highStr = ""
highStr = highStr.join(temhigh)
highs.append(int(highStr)) # 以上三行将高温NavigableString转成int类型并存入高温列表
temp.append(temperate)
final.append(temp)
i = i + 1
# 将最终的获取的天气写入csv文件
with open('weather.csv', 'a', errors='ignore', newline='') as f:
f_csv = csv.writer(f)
f_csv.writerows([cityname])
f_csv.writerows(final)
# 绘图
bar = pygal.Line() # 创建折线图
bar.add('最低气温', lows)
bar.add('最高气温', highs)
bar.x_labels = daytimes
bar.x_labels_major = daytimes[::30]
# bar.show_minor_x_labels = False # 不显示X轴最小刻度
bar.x_label_rotation = 45
bar.title = cityname+'未来七天气温走向图'
bar.x_title = "日期"
bar.y_title = "气温(摄氏度)"
bar.legend_at_bottom = True
bar.show_x_guides = False
bar.show_y_guides = True
bar.render_to_file('temperate.svg')
Python爬取天气数据实例扩展:
import requests from bs4 import BeautifulSoup from pyecharts import Bar ALL_DATA = [] def send_parse_urls(start_urls): headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.122 Safari/537.36" } for start_url in start_urls: response = requests.get(start_url,headers=headers) # 编码问题的解决 response = response.text.encode("raw_unicode_escape").decode("utf-8") soup = BeautifulSoup(response,"html5lib") #lxml解析器:性能比较好,html5lib:适合页面结构比较混乱的 div_tatall = soup.find("div",class_="conMidtab") #find() 找符合要求的第一个元素 tables = div_tatall.find_all("table") #find_all() 找到符合要求的所有元素的列表 for table in tables: trs = table.find_all("tr") info_trs = trs[2:] for index,info_tr in enumerate(info_trs): # 枚举函数,可以获得索引 # print(index,info_tr) # print("="*30) city_td = info_tr.find_all("td")[0] temp_td = info_tr.find_all("td")[6] # if的判断的index的特殊情况应该在一般情况的后面,把之前的数据覆盖 if index==0: city_td = info_tr.find_all("td")[1] temp_td = info_tr.find_all("td")[7] city=list(city_td.stripped_strings)[0] temp=list(temp_td.stripped_strings)[0] ALL_DATA.append({"city":city,"temp":temp}) return ALL_DATA def get_start_urls(): start_urls = [ "http://www.weather.com.cn/textFC/hb.shtml", "http://www.weather.com.cn/textFC/db.shtml", "http://www.weather.com.cn/textFC/hd.shtml", "http://www.weather.com.cn/textFC/hz.shtml", "http://www.weather.com.cn/textFC/hn.shtml", "http://www.weather.com.cn/textFC/xb.shtml", "http://www.weather.com.cn/textFC/xn.shtml", "http://www.weather.com.cn/textFC/gat.shtml", ] return start_urls def main(): """ 主程序逻辑 展示全国实时温度最低的十个城市气温排行榜的柱状图 """ # 1 获取所有起始url start_urls = get_start_urls() # 2 发送请求获取响应、解析页面 data = send_parse_urls(start_urls) # print(data) # 4 数据可视化 #1排序 data.sort(key=lambda data:int(data["temp"])) #2切片,选择出温度最低的十个城市和温度值 show_data = data[:10] #3分出城市和温度 city = list(map(lambda data:data["city"],show_data)) temp = list(map(lambda data:int(data["temp"]),show_data)) #4创建柱状图、生成目标图 chart = Bar("中国最低气温排行榜") #需要安装pyechart模块 chart.add("",city,temp) chart.render("tempture.html") if __name__ == '__main__': main()
到此这篇关于python爬取天气数据的实例详解的文章就介绍到这了,更多相关python爬虫天气数据的分析内容请搜索小牛知识库以前的文章或继续浏览下面的相关文章希望大家以后多多支持小牛知识库!
-
21.1 注册免费API和阅读文档 本节通过一个API接口(和风天气预报)爬取天气信息,该接口为个人开发者提供了一个免费的预报数据(有次数限制)。 首先访问和风天气网,注册一个账户。注册地址:https://console.heweather.com/ 在登陆后的控制台中可以看到个人认证的key(密钥),这个key就是访问API接口的钥匙。 获取key之后阅读API文档:https://www.h
-
本文向大家介绍Python爬取数据并写入MySQL数据库的实例,包括了Python爬取数据并写入MySQL数据库的实例的使用技巧和注意事项,需要的朋友参考一下 首先我们来爬取 http://html-color-codes.info/color-names/ 的一些数据。 按 F12 或 ctrl+u 审查元素,结果如下: 结构很清晰简单,我们就是要爬 tr 标签里面的 style 和 tr 下几
-
本文向大家介绍Python爬取国外天气预报网站的方法,包括了Python爬取国外天气预报网站的方法的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Python爬取国外天气预报网站的方法。分享给大家供大家参考。具体如下: crawl_weather.py如下: FetchLocation.py如下: 希望本文所述对大家的python程序设计有所帮助。
-
本文向大家介绍Python爬虫爬取、解析数据操作示例,包括了Python爬虫爬取、解析数据操作示例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Python爬虫爬取、解析数据操作。分享给大家供大家参考,具体如下: 爬虫 当当网 http://search.dangdang.com/?key=python&act=input&page_index=1 获取书籍相关信息 面向对象思想 利用不
-
本文向大家介绍python 中xpath爬虫实例详解,包括了python 中xpath爬虫实例详解的使用技巧和注意事项,需要的朋友参考一下 案例一: 某套图网站,套图以封面形式展现在页面,需要依次点击套图,点击广告盘链接,最后到达百度网盘展示页面。 这一过程通过爬虫来实现,收集百度网盘地址和提取码,采用xpath爬虫技术 1、首先分析图片列表页,该页按照更新先后顺序暂时套图封面,查看HTML结构。
-
本文向大家介绍python爬虫实现爬取同一个网站的多页数据的实例讲解,包括了python爬虫实现爬取同一个网站的多页数据的实例讲解的使用技巧和注意事项,需要的朋友参考一下 对于一个网站的图片、文字音视频等,如果我们一个个的下载,不仅浪费时间,而且很容易出错。Python爬虫帮助我们获取需要的数据,这个数据是可以快速批量的获取。本文小编带领大家通过python爬虫获取获取总页数并更改url的方法,实