
python之MSE、MAE、RMSE的使用

我就废话不多说啦,直接上代码吧!
target = [1.5, 2.1, 3.3, -4.7, -2.3, 0.75]
prediction = [0.5, 1.5, 2.1, -2.2, 0.1, -0.5]
error = []
for i in range(len(target)):
error.append(target[i] - prediction[i])
print("Errors: ", error)
print(error)
squaredError = []
absError = []
for val in error:
squaredError.append(val * val)#target-prediction之差平方
absError.append(abs(val))#误差绝对值
print("Square Error: ", squaredError)
print("Absolute Value of Error: ", absError)
print("MSE = ", sum(squaredError) / len(squaredError))#均方误差MSE
from math import sqrt
print("RMSE = ", sqrt(sum(squaredError) / len(squaredError)))#均方根误差RMSE
print("MAE = ", sum(absError) / len(absError))#平均绝对误差MAE
targetDeviation = []
targetMean = sum(target) / len(target)#target平均值
for val in target:
targetDeviation.append((val - targetMean) * (val - targetMean))
print("Target Variance = ", sum(targetDeviation) / len(targetDeviation))#方差
print("Target Standard Deviation = ", sqrt(sum(targetDeviation) / len(targetDeviation)))#标准差
补充拓展:回归模型指标:MSE 、 RMSE、 MAE、R2
sklearn调用
# 测试集标签预测
y_predict = lin_reg.predict(X_test)
# 衡量线性回归的MSE 、 RMSE、 MAE、r2
from math import sqrt
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import mean_squared_error
from sklearn.metrics import r2_score
print("mean_absolute_error:", mean_absolute_error(y_test, y_predict))
print("mean_squared_error:", mean_squared_error(y_test, y_predict))
print("rmse:", sqrt(mean_squared_error(y_test, y_predict)))
print("r2 score:", r2_score(y_test, y_predict))
原生实现
# 测试集标签预测
y_predict = lin_reg.predict(X_test)
# 衡量线性回归的MSE 、 RMSE、 MAE
mse = np.sum((y_test - y_predict) ** 2) / len(y_test)
rmse = sqrt(mse)
mae = np.sum(np.absolute(y_test - y_predict)) / len(y_test)
r2 = 1-mse/ np.var(y_test)
print("mse:",mse," rmse:",rmse," mae:",mae," r2:",r2)
相关公式
MSE

RMSE
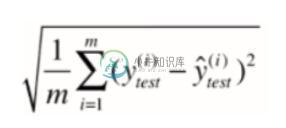
MAE
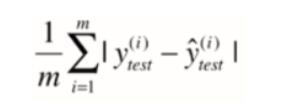
R2

以上这篇python之MSE、MAE、RMSE的使用就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持小牛知识库。
-
我有一个如下的数据集。在该数据集中,有不同颜色的温度计,给定“真实”或参考温度,根据一些测量方法“方法1”和“方法2”,它们测量的差异有多大。 我在计算我需要的两个重要参数时遇到困难,这两个参数是平均绝对误差(MAE)和平均符号误差(MSE)。我想为每个方法使用非NaN值并打印结果。 我能够得到的点,我可以返回一个两列系列的索引和和,但在这种情况下的问题是,我需要除以方法值的数量总和,这取决于有多
-
我正在尝试创建反向传播,但我不想使用TF中的GradientDescentOptimizer。我只是想更新我自己的权重和偏差。问题是,均方误差或成本并没有接近于零。它只是停留在0.2xxx左右。是因为我的输入是520x1600(是的,每个输入有1600个单位,是的,有520个单位),还是我隐藏层中的神经元数量有问题?我曾尝试使用GradientDescentOptimizer和minimize(c
-
您好,我在为我的LTSM模型找到正确的inputshape时遇到问题。我一直试图找到一个合适的形状,但很难理解需要什么。 我认为问题在于ytest和ytrain的形状。为什么它的形状与xtrain和xtest不同? 当我试图适应这个模型时: 我尝试从其他职位实施解决方案,例如: https://datascience.stackexchange.com/questions/39334/recurr
-
本文向大家介绍Python入门之modf()方法的使用,包括了Python入门之modf()方法的使用的使用技巧和注意事项,需要的朋友参考一下 modf()方法返回两个项的元组x的整数小数部分。这两个元组具有相同x符号。则返回一个浮点数的整数部分。 语法 以下是modf()方法的语法: 注意:此函数是无法直接访问的,所以我们需要导入math模块,然后需要用math的静态对象来调用这个函数。 参数
-
本文向大家介绍Python爬虫之UserAgent的使用实例,包括了Python爬虫之UserAgent的使用实例的使用技巧和注意事项,需要的朋友参考一下 问题: 在Python爬虫的过程中经常要模拟UserAgent, 因此自动生成UserAgent十分有用, 最近看到一个Python库(fake-useragent),可以随机生成各种UserAgent, 在这里记录一下, 留给自己爬虫使用。
-
本文向大家介绍python爬虫之urllib3的使用示例,包括了python爬虫之urllib3的使用示例的使用技巧和注意事项,需要的朋友参考一下 Urllib3是一个功能强大,条理清晰,用于HTTP客户端的Python库。许多Python的原生系统已经开始使用urllib3。Urllib3提供了很多python标准库urllib里所没有的重要特性: 线程安全 连接池 客户端SSL/TLS验证 文