
TF-IDF与余弦相似性的应用(一) 自动提取关键词

TF-IDF与余弦相似性的应用(一):自动提取关键词
这个标题看上去好像很复杂,其实我要谈的是一个很简单的问题。
有一篇很长的文章,我要用计算机提取它的关键词(Automatic Keyphrase extraction),完全不加以人工干预,请问怎样才能正确做到?

这个问题涉及到数据挖掘、文本处理、信息检索等很多计算机前沿领域,但是出乎意料的是,有一个非常简单的经典算法,可以给出令人相当满意的结果。它简单到都不需要高等数学,普通人只用10分钟就可以理解,这就是我今天想要介绍的TF-IDF算法。
让我们从一个实例开始讲起。假定现在有一篇长文《中国的蜜蜂养殖》,我们准备用计算机提取它的关键词。

一个容易想到的思路,就是找到出现次数最多的词。如果某个词很重要,它应该在这篇文章中多次出现。于是,我们进行"词频"(Term Frequency,缩写为TF)统计。
结果你肯定猜到了,出现次数最多的词是----"的"、"是"、"在"----这一类最常用的词。它们叫做"停用词"(stop words),表示对找到结果毫无帮助、必须过滤掉的词。
假设我们把它们都过滤掉了,只考虑剩下的有实际意义的词。这样又会遇到了另一个问题,我们可能发现"中国"、"蜜蜂"、"养殖"这三个词的出现次数一样多。这是不是意味着,作为关键词,它们的重要性是一样的?
显然不是这样。因为"中国"是很常见的词,相对而言,"蜜蜂"和"养殖"不那么常见。如果这三个词在一篇文章的出现次数一样多,有理由认为,"蜜蜂"和"养殖"的重要程度要大于"中国",也就是说,在关键词排序上面,"蜜蜂"和"养殖"应该排在"中国"的前面。
所以,我们需要一个重要性调整系数,衡量一个词是不是常见词。如果某个词比较少见,但是它在这篇文章中多次出现,那么它很可能就反映了这篇文章的特性,正是我们所需要的关键词。
用统计学语言表达,就是在词频的基础上,要对每个词分配一个"重要性"权重。最常见的词("的"、"是"、"在")给予最小的权重,较常见的词("中国")给予较小的权重,较少见的词("蜜蜂"、"养殖")给予较大的权重。这个权重叫做"逆文档频率"(Inverse Document Frequency,缩写为IDF),它的大小与一个词的常见程度成反比。
知道了"词频"(TF)和"逆文档频率"(IDF)以后,将这两个值相乘,就得到了一个词的TF-IDF值。某个词对文章的重要性越高,它的TF-IDF值就越大。所以,排在最前面的几个词,就是这篇文章的关键词。
下面就是这个算法的细节。
第一步,计算词频。

考虑到文章有长短之分,为了便于不同文章的比较,进行"词频"标准化。

或者

第二步,计算逆文档频率。
这时,需要一个语料库(corpus),用来模拟语言的使用环境。

如果一个词越常见,那么分母就越大,逆文档频率就越小越接近0。分母之所以要加1,是为了避免分母为0(即所有文档都不包含该词)。log表示对得到的值取对数。
第三步,计算TF-IDF。

可以看到,TF-IDF与一个词在文档中的出现次数成正比,与该词在整个语言中的出现次数成反比。所以,自动提取关键词的算法就很清楚了,就是计算出文档的每个词的TF-IDF值,然后按降序排列,取排在最前面的几个词。
还是以《中国的蜜蜂养殖》为例,假定该文长度为1000个词,"中国"、"蜜蜂"、"养殖"各出现20次,则这三个词的"词频"(TF)都为0.02。然后,搜索Google发现,包含"的"字的网页共有250亿张,假定这就是中文网页总数。包含"中国"的网页共有62.3亿张,包含"蜜蜂"的网页为0.484亿张,包含"养殖"的网页为0.973亿张。则它们的逆文档频率(IDF)和TF-IDF如下:
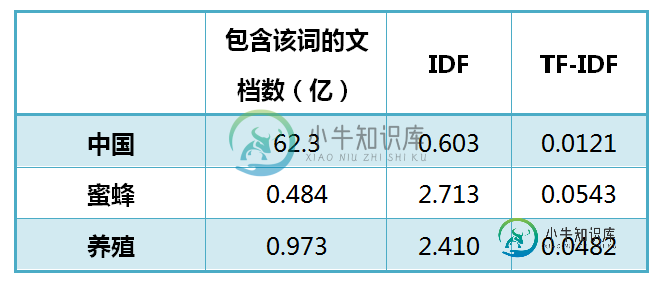
从上表可见,"蜜蜂"的TF-IDF值最高,"养殖"其次,"中国"最低。(如果还计算"的"字的TF-IDF,那将是一个极其接近0的值。)所以,如果只选择一个词,"蜜蜂"就是这篇文章的关键词。
除了自动提取关键词,TF-IDF算法还可以用于许多别的地方。比如,信息检索时,对于每个文档,都可以分别计算一组搜索词("中国"、"蜜蜂"、"养殖")的TF-IDF,将它们相加,就可以得到整个文档的TF-IDF。这个值最高的文档就是与搜索词最相关的文档。
TF-IDF算法的优点是简单快速,结果比较符合实际情况。缺点是,单纯以"词频"衡量一个词的重要性,不够全面,有时重要的词可能出现次数并不多。而且,这种算法无法体现词的位置信息,出现位置靠前的词与出现位置靠后的词,都被视为重要性相同,这是不正确的。(一种解决方法是,对全文的第一段和每一段的第一句话,给予较大的权重。)
下一次,我将用TF-IDF结合余弦相似性,衡量文档之间的相似程度。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持小牛知识库。
-
本文向大家介绍TF-IDF与余弦相似性的应用(二) 找出相似文章,包括了TF-IDF与余弦相似性的应用(二) 找出相似文章的使用技巧和注意事项,需要的朋友参考一下 上一次,我用TF-IDF算法自动提取关键词。 今天,我们再来研究另一个相关的问题。有些时候,除了找到关键词,我们还希望找到与原文章相似的其他文章。比如,"Google新闻"在主新闻下方,还提供多条相似的新闻。 为了找出相似的文章,需要用
-
问题内容: 我需要比较存储在数据库中的文档,并得出0到1之间的相似度分数。 我需要使用的方法必须非常简单。实现n-gram的原始版本(可以定义要使用的克数),以及tf-idf和Cosine相似度的简单实现。 是否有任何程序可以做到这一点?还是应该从头开始编写? 问题答案: 查看NLTK软件包:http://www.nltk.org,它具有您需要的一切 对于cosine_similarity: 对于
-
问题内容: 我计算了两个文档的tf / idf值。以下是tf / idf值: 这些文件就像: 如何使用这些值来计算余弦相似度? 我知道我应该计算点积,然后找到距离并除以点积。如何使用我的值来计算? 还有一个问题: 两个文档的字数相同是否重要? 问题答案: a * b是点积 一些细节: 是。在某种程度上,a和b必须具有相同的长度。但是a和b通常具有稀疏表示,您只需要存储非零条目,就可以更快地计算范数
-
本文向大家介绍python TF-IDF算法实现文本关键词提取,包括了python TF-IDF算法实现文本关键词提取的使用技巧和注意事项,需要的朋友参考一下 TF(Term Frequency)词频,在文章中出现次数最多的词,然而文章中出现次数较多的词并不一定就是关键词,比如常见的对文章本身并没有多大意义的停用词。所以我们需要一个重要性调整系数来衡量一个词是不是常见词。该权重为IDF(Inver
-
Lucene是一个反向索引系统,据我所知,它的强大之处在于它只会将查询与至少匹配令牌的文档进行比较。 与将查询与每个文档进行比较的简单方法相比(即使是那些没有提到查询中存在的任何标记的文档),这是一个很大的好处。 例如,如果我有索引文档: 在我看来,搜索查询:“你好世界”,只会查看索引文档D1和D2,并跳过D3,这节省了时间。 这样做正确吗? 现在,我试图计算文档之间的余弦相似度。输入查询将是一个
-
我有一个PySpark数据帧,df1,看起来像: 我有第二个PySpark数据帧,df2 我想得到两个数据帧的余弦相似性。并有类似的东西