
强制SQL Server执行计划使用并行提升在复杂查询语句下的性能

通过观察执行计划,发现之前的执行计划在很多大表连接的部分使用了Hash Join,由于涉及的表中数据众多,因此查询优化器选择使用并行执行,速度较快。而我们优化完的执行计划由于索引的存在,且表内数据非常大,过滤条件的值在一个很宽的统计信息步长范围内,导致估计行数出现较大偏差(过滤条件实际为15000行,步长内估计的平均行数为800行左右),因此查询优化器选择了Loop Join,且没有选择并行执行,因此执行时间不降反升。
由于语句是在存储过程中实现,因此我们直接对该语句使用一个undocument查询提示,使得该查询的并行开销阈值强制降为0,使得该语句强制走并行,语句执行时间由20秒降为5秒(注:使用Hash Join提示是7秒)。
下面通过一个简单的例子展示使用该提示的效果,示例T-SQL如代码清单1所示:
SELECT * FROM [AdventureWorks].[Sales].[SalesOrderDetail] a INNER JOIN [Sales].SalesOrderHeader b ON a.SalesOrderID=b.SalesOrderID
代码清单1.
该语句默认不会走并行,执行计划如图1所示:
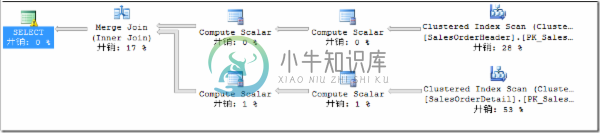
图1.
下面我们对该语句加上提示,如代码清单2所示。
SELECT * FROM [AdventureWorks].[Sales].[SalesOrderDetail] a INNER JOIN [Sales].SalesOrderHeader b ON a.SalesOrderID=b.SalesOrderID OPTION(querytraceon 8649)
代码清单2.
此时执行计划会按照提示走并行,如图2所示:

图2.
在面对一些复杂的DSS或OLAP查询时遇到类似的情况,可以考虑使用该Undocument提示要求SQL Server尽可能的使用并行,从而降低执行时间。
-
本文向大家介绍MySql中如何使用 explain 查询 SQL 的执行计划,包括了MySql中如何使用 explain 查询 SQL 的执行计划的使用技巧和注意事项,需要的朋友参考一下 explain命令是查看查询优化器如何决定执行查询的主要方法。 这个功能有局限性,并不总会说出真相,但它的输出是可以获取的最好信息,值得花时间去了解,因为可以学习到查询是如何执行的。 1、什么是MySQL执行计划
-
问题 您要执行的 SQL 语句如:高级的联接或计数。 方案 webpy 没有尝试在数据库之上建立一层模型,而是以尽可能简单的方式查询数据库, 做复杂的查询也很容易。例如: import web db = web.database(dbn='postgres', db='mydata', user='dbuser', pw='') # Query number of entries in `us
-
问题内容: 我有以下代码: 此功能在专用的go例程中执行,并每秒发送一次心跳消息。取消上下文后,整个过程应立即停止。 现在考虑以下情形: 这将在关闭的上下文中启动心跳例程。在这种情况下,我不希望传输任何心跳。因此,应该立即输入选择中的第一个块。 但是,似乎无法保证对块进行评估的顺序,并且即使上下文已取消,该代码有时也会发送心跳消息。 实施这种行为的正确方法是什么? 我可以在第二个中添加“ isCo
-
问题内容: SQL2008。 我有一个测试表: 我用10k测试行填充它。 我运行以下两个查询: 我不知道为什么这两个查询有不同的执行计划。 查询1确实针对UQ_Sale_RowVersion索引进行索引搜索。 查询2对PK_Sale进行索引扫描。 我想查询2做索引查找。 我将不胜感激。 谢谢你。 [编辑] 尝试使用datetime2而不是rowversion。同样的问题。 我也尝试强制使用索引(查
-
本文向大家介绍深入分析SqlServer查询计划,包括了深入分析SqlServer查询计划的使用技巧和注意事项,需要的朋友参考一下 对于SQL Server的优化来说,优化查询可能是很常见的事情。由于数据库的优化,本身也是一个涉及面比较的广的话题, 因此本文只谈优化查询时如何看懂SQL Server查询计划。毕竟我对SQL Server的认识有限,如有错误,也恳请您在发现后及时批评指正。 首先,打
-
问题内容: 是否可以在postgresql中手动更改执行计划的操作顺序?例如,如果我一直想在过滤之前进行排序操作(尽管在正常使用Postgresql中没有意义),是否可以通过例如更改操作的内部成本来手动执行该操作? 如果实现自己的功能该怎么办?是否有可能总是在sql语句的最后执行这样的功能? 问题答案: 还有更多的方法- 这里显示了一些方法,但是还有第二种方法,如果要在处理结束时移动函数调用,则只