
webpack4 SplitChunks实现代码分隔详解

代码均放在 git仓库
Webpack 4给我们带来了一些改变。包括更快的打包速度,引入了SplitChunksPlugin插件来取代(之前版本里的)CommonsChunksPlugin插件。在这篇文章中,你将学习如何分割你的输出代码,从而提升我们应用的性能。
SplitChunks插件( webpack 4.x以前使用CommonsChunkPlugin )允许我们将公共依赖项提取到现有的 entry chunk 或全新的代码块中。
代码分割的理念
首先搞明白: webpack里的代码分割是个什么鬼? 它允许你将一个文件分割成多个文件。如果使用的好,它能大幅提升你的应用的性能。其原因是基于浏览器会缓存你的代码这一事实。每当你对某一文件做点改变,访问你站点的人们就要重新下载它。然而依赖却很少变动。如果你将(这些依赖)分离成单独的文件,访问者就无需多次重复下载它们了。
使用webpack生成一个或多个包含你源代码最终版本的“打包好的文件”(bundles),(概念上我们当作)它们由(一个一个的)chunks组成。
首先 webpack 总共提供了三种办法来实现 Code Splitting,如下:
- 入口配置:entry 入口使用多个入口文件;
- 抽取公有代码:使用 SplitChunks 抽取公有代码;
- 动态加载 :动态加载一些代码。
这里我们姑且只讨论使用 SplitChunks 抽取公有代码。
splitChunks配置
在src目录下创建三个文件pageA.js、pageB.js和pageC.js。代码详情见文章开头git仓库。
// src/pageA.js
var react = require('react');
var reactDom = require('react-dom');
var utility1 = require('../utils/utility1');
var utility2 = require('../utils/utility2');
new Vue();
module.exports = "pageA";
// src/pageB.js
var react = require('react');
var reactDom = require('react-dom');
var utility2 = require('../utils/utility2');
var utility3 = require('../utils/utility3');
module.exports = "pageB";
// src/pageC.js
var react = require('react');
var reactDom = require('react-dom');
var utility2 = require('../utils/utility2');
var utility3 = require('../utils/utility3');
module.exports = "pageC";
入口文件 && 出口文件
entry: {
pageA: "./src/pageA", // 引用utility1.js utility2.js
pageB: "./src/pageB", // 引用utility2.js utility3.js
pageC: "./src/pageC", // 引用utility2.js utility3.js
},
output: {
path: path.join(__dirname, "dist"),
filename: "[name].[hash:8].bundle.js"
},
配置optimization
首先我们配置optimization如下:
optimization: {
splitChunks: {
chunks: "all",
},
执行npm run build打包命令之后,查看dist目录
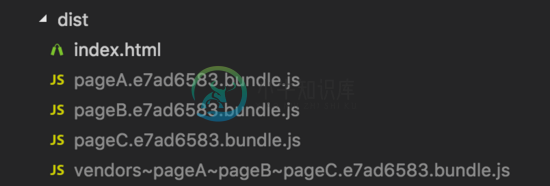
可以发现,打包出来的除了三个page文件,还存在一个vendors~pageA~pageB~pageC.[hash].bundle.js文件( 此文件中保存了pageA、pageB、pageC和node_modules中共有的size大于30KB的文件 )。事实上这全靠了配置中本身默认固有一个cacheGroups的配置项:
splitChunks: {
chunks: "all",
cacheGroups: {
vendors: {
test: /[\\/]node_modules[\\/]/, // 匹配node_modules目录下的文件
priority: -10 // 优先级配置项
},
default: {
minChunks: 2,
priority: -20, // 优先级配置项
reuseExistingChunk: true
}
}
}
在默认设置中,会将 node_mudules 文件夹中的模块打包进一个叫 vendors的bundle中,所有引用超过两次的模块分配到 default bundle 中。更可以通过 priority 来设置优先级。
参数说明如下:
- chunks:表示从哪些chunks里面抽取代码,除了三个可选字符串值 initial、async、all 之外,还可以通过函数来过滤所需的 chunks;
- minSize:表示抽取出来的文件在压缩前的最小大小,默认为 30000;
- maxSize:表示抽取出来的文件在压缩前的最大大小,默认为 0,表示不限制最大大小;
- minChunks:表示被引用次数,默认为1;上述配置commons中minChunks为2,表示将被多次引用的代码抽离成commons。
值得注意的是,如果没有修改minSize属性的话,而且被公用的代码(假设是utilities.js)size小于30KB的话,它就不会分割成一个单独的文件。在真实情形下,这是合理的,因为(如分割)并不能带来性能确实的提升,反而使得浏览器多了一次对utilities.js的请求,而这个utilities.js又是如此之小(不划算)。
- maxAsyncRequests:最大的按需(异步)加载次数,默认为 5;
- maxInitialRequests:最大的初始化加载次数,默认为 3;
- automaticNameDelimiter:抽取出来的文件的自动生成名字的分割符,默认为 ~;
- name:抽取出来文件的名字,默认为 true,表示自动生成文件名;
- cacheGroups: 缓存组。(这才是配置的关键)
缓存组会继承splitChunks的配置,但是 test、priorty和reuseExistingChunk只能用于配置缓存组 。cacheGroups是一个对象,按上述介绍的键值对方式来配置即可,值代表对应的选项。除此之外,所有上面列出的选择都是可以用在缓存组里的:chunks, minSize, minChunks, maxAsyncRequests, maxInitialRequests, name。可以通过optimization.splitChunks.cacheGroups.default: false禁用default缓存组。 默认缓存组的优先级(priotity)是负数,因此所有自定义缓存组都可以有比它更高优先级(译注:更高优先级的缓存组可以优先打包所选择的模块)(默认自定义缓存组优先级为0)
现在我们再重新来看一下pageA、pageB、pageC三个js文件,这三个文件中都引入了utility2.js文件,但是此文件size很明显小于30KB,所以这部分公用代码并没有分割出来。如果想要分割出来很简单,只需要:
optimization: {
splitChunks: {
chunks: "all",
minSize: 0
},
执行npm run build打包命令之后,查看dist目录
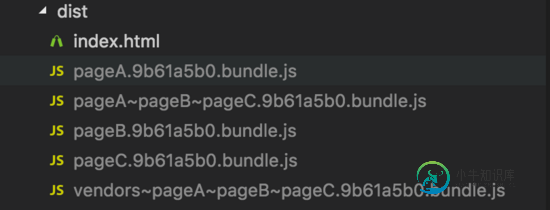
显然多了一个pageA~pageB~pageC.[hash].bundle.js文件。查看文件可得知此文件中存储了utility2.js中的代码。如下图所示(借助于webpack-bundle-analyzer插件,详情文章末尾附录)。

上图可以看出,React相关代码均放在了vendors~pageA~pageB~pageC.[hash].bundle.js文件中,如果我们想要抽离出React代码,应该怎么做呐?
splitChunks: {
chunks: "all",
cacheGroups: {
commons: {
chunks: "initial",
minChunks: 2,
name: "commons",
maxInitialRequests: 5,
minSize: 0, // 默认是30kb,minSize设置为0之后
// 多次引用的utility1.js和utility2.js会被压缩到commons中
},
reactBase: {
test: (module) => {
return /react|redux|prop-types/.test(module.context);
}, // 直接使用 test 来做路径匹配,抽离react相关代码
chunks: "initial",
name: "reactBase",
priority: 10,
}
}
},
run build之后如下图所示。

看似非常完美,但是reactBase文件中竟然包含了node_modules,神奇的问题?室友都睡觉了,这键盘声影响不好,明天接着看。
附录
我们再安装一个 webpack-bundle-analyzer,这个插件会清晰的展示出打包后的各个bundle所依赖的模块:
npm i webpack-bundle-analyzer -D
引入:
const BundleAnalyzerPlugin = require('webpack-bundle-analyzer').BundleAnalyzerPlugin
使用,在plugins数组中添加即可:
new BundleAnalyzerPlugin()
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持小牛知识库。
-
本文向大家介绍Django分页功能的实现代码详解,包括了Django分页功能的实现代码详解的使用技巧和注意事项,需要的朋友参考一下 Django分页功能的实现 打开命令行窗口,创建Django工程,使用以下命令: django-admin startproject djpage cd djpage python manage.py startapp demo 使用PyCharm打开工程,在工程的同
-
本文向大家介绍java 实现 stack详解及实例代码,包括了java 实现 stack详解及实例代码的使用技巧和注意事项,需要的朋友参考一下 栈是限制插入和删除只能在一个位置上进行的 List,该位置是 List 的末端,叫做栈的顶(top),对于栈的基本操作有 push 和 pop,前者是插入,后者是删除。 栈也是 FIFO 表。 栈的实现有两种,一种是使用数组,一种是使用链表。 栈的应用 平
-
本文向大家介绍详解JS实现简单的时分秒倒计时代码,包括了详解JS实现简单的时分秒倒计时代码的使用技巧和注意事项,需要的朋友参考一下 本文实例为大家分享了JS时分秒倒计时的实现的具体代码,供大家参考,具体内容如下 代码总结: Math.floor:返回小于等于参数的最大整数 setTimeout() 方法用于在指定的毫秒数后调用函数或计算表达式 以上所述是小编给大家介绍的JS时分秒倒计时的实现详解整
-
本文向大家介绍详解spring封装hbase的代码实现,包括了详解spring封装hbase的代码实现的使用技巧和注意事项,需要的朋友参考一下 前面我们讲了spring封装MongoDB的代码实现,这里我们讲一下spring封装Hbase的代码实现。 hbase的简介: 此处大概说一下,不是我们要讨论的重点。 HBase是一个分布式的、面向列的开源数据库,HBase在Hadoop之上提供了类似于B
-
本文向大家介绍Java实现搜索功能代码详解,包括了Java实现搜索功能代码详解的使用技巧和注意事项,需要的朋友参考一下 首先,我们要清楚搜索框中根据关键字进行条件搜索发送的是Get请求,并且是向当前页面发送Get请求 当我们要实现多条件搜索功能时,可以将搜索条件封装为一个Map集合,再根据Map集合进行搜索 Controller层代码: 业务层代码: MyBatis中的mapper.xml: 这样
-
本文向大家介绍Django权限机制实现代码详解,包括了Django权限机制实现代码详解的使用技巧和注意事项,需要的朋友参考一下 本文研究的主要是Django权限机制的相关内容,具体如下。 1. Django权限机制概述 权限机制能够约束用户行为,控制页面的显示内容,也能使API更加安全和灵活;用好权限机制,能让系统更加强大和健壮。因此,基于Django的开发,理清Django权限机制是非常必要的。