
Python 抓取微信公众号账号信息的方法


搜狗微信搜索提供两种类型的关键词搜索,一种是搜索公众号文章内容,另一种是直接搜索微信公众号。通过微信公众号搜索可以获取公众号的基本信息及最近发布的10条文章,今天来抓取一下微信公众号的账号信息
爬虫
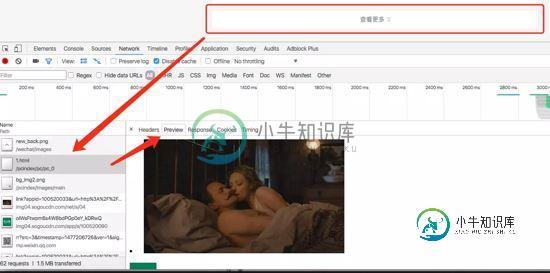
首先通过首页进入,可以按照类别抓取,通过“查看更多”可以找出页面链接规则:
import requests as req
import re
reTypes = r'id="pc_\d*" uigs="(pc_\d*)">([\s\S]*?)</a>'
Entry = "http://weixin.sogou.com/"
entryPage = req.get(Entry)
allTypes = re.findall(reTypes, getUTF8(entryPage))
for (pcid, category) in allTypes:
for page in range(1, 100):
url = 'http://weixin.sogou.com/pcindex/pc/{}/{}.html'.format(pcid, page)
print(url)
categoryList = req.get(url)
if categoryList.status_code != 200:
break
上面代码通过加载更多页面获取加载列表,进而从其中抓取微信公众号详情页面:
reProfile = r'<li id[\s\S]*?<a href="([\s\S]*?)" rel="external nofollow" '
allProfiles = re.findall(reOAProfile, getUTF8(categoryList))
for profile in allProfiles:
profilePage = req.get(profile)
if profilePage.status_code != 200:
continue
进入详情页面可以获取公众号的 名称/ID/功能介绍/账号主体/头像/二维码/最近10篇文章 等信息:
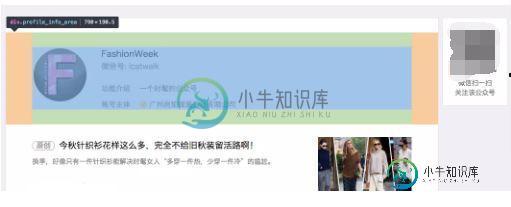
注意事项
详情页面链接: http://mp.weixin.qq.com/profile?src=3×tamp=1477208282&ver=1&signature=8rYJ4QV2w5FXSOy6vGn37sUdcSLa8uoyHv3Ft7CrhZhB4wO-bbWG94aUCNexyB7lqRNSazua-2MROwkV835ilg==
1. 验证码
访问详情页面时有可能需要验证码,自动识别验证码还是很有难度的,因此要做好爬虫的伪装工作。
2. 未保存详情页面链接
详情页面的链接中有两个重要参数: timestamp & signature ,这说明页面链接是有时效性的,所以保存下来应该也没用;
3. 二维码
二维码图片链接同样具有时效性,因此如需要最好将图片下载下来。
用 Flask 展示结果
最近 Python 社区出现了一款异步增强版的 Flask 框架: Sanic ,基于 uvloop 和 httptools ,可以达到异步、更快的效果,但保持了与 Flask 一致的简洁语法。虽然项目刚起步,还有很多基本功能为实现,但已经获得了很多关注( 2,222 Star )。这次本打算用抓取的微信公众号信息基于 Sanic 做一个简单的交互应用,但无奈目前还没有加入模板功能,异步的 redis 驱动也还有 BUG 没解决,所以简单尝试了一下之后还是切换回 Flask + SQLite,先把抓取结果呈现出来,后续有机会再做更新。
安装 Sanic

Debug Sanic
Flask + SQLite App
from flask import g, Flask, render_template
import sqlite3
app = Flask(__name__)
DATABASE = "./db/wx.db"
def get_db():
db = getattr(g, '_database', None)
if db is None:
db = g._database = sqlite3.connect(DATABASE)
return db
@app.teardown_appcontext
def close_connection(exception):
db = getattr(g, '_database', None)
if db is not None:
db.close()
@app.route("/<int:page>")
@app.route("/")
def hello(page=0):
cur = get_db().cursor()
cur.execute("SELECT * FROM wxoa LIMIT 30 OFFSET ?", (page*30, ))
rows = []
for row in cur.fetchall():
rows.append(row)
return render_template("app.html", wx=rows, cp=page)
if __name__ == "__main__":
app.run(debug=True, port=8000)
总结
以上所述是小编给大家介绍的Python 抓取微信公众号账号信息,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对小牛知识库网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!
-
本文向大家介绍python抓取搜狗微信公众号文章,包括了python抓取搜狗微信公众号文章的使用技巧和注意事项,需要的朋友参考一下 初学python,抓取搜狗微信公众号文章存入mysql mysql表: 代码: 以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持呐喊教程。
-
方案1:将公众号授权给智齿 接入效果 授权过程 授权微信公众号给智齿需要智齿客服管理员和微信公众号管理员共同参与,具体步骤如下: 第一步:智齿客服管理员进入智齿管理后台「设置-支持渠道-微信」,点击「绑定公众号」进入授权页,可见微信授权二维码 <微信公众号授权扫码页-电脑端> 第二步:由企业微信公众号管理员在微信端扫码、确认勾选授权哪些权限集给智齿并点击确认授权,完成授权后即算部署完成 <
-
微信公众号 微信公众号扫码授权以后,用户发往公众号的消息会转发给机器人,机器人会自动回复消息给公众号用户,同一个微信公众号同时只能绑定一个机器人,如果绑定了新的机器人,之前绑定的机器人会解除绑定。 注:微信公众号渠道接入后,仅支持微信文字,语音两种方式问答,用户在微信聊天框输入语音后,客服系统自动识别语音成文字进行答复。 只需三步接入微信公众号,自动回答公众号上的用户问题 1. 创建机器人 注册登
-
本SDK支持微信公众号以及企业号的上行消息及OAuth接口。本文档及SDK假设使用者已经具备微信公众号开发的基础知识,及有能力通过微信公众号、企业号的文档来查找相关的接口详情。 1. 安装 pip install wechat 源码安装 git clone git@github.com:jeffkit/wechat.gitcd wechatpython setup.py install 对于微信用
-
本文向大家介绍微信公众号消息类型?相关面试题,主要包含被问及微信公众号消息类型?时的应答技巧和注意事项,需要的朋友参考一下 微信目前提供了7种基本消息类型,分别为: (1)文本消息(text); (2)图片消息(image); (3)语音(voice) (4)视频(video) (5)地理位置(location); (6)链接消息(link); (7)事件推送(event) 类型。 掌握不同的消息
-
自动收集我关注的微信公众号文章 我的微信里关注了数十个有关大数据的公众号,每天都会出现那个小红点让我点进去看,但是点多了就会觉得烦了,所以我要做的第一步就是自动把公众号里的新文章都收集到一块,怎么做呢?scrapy! 对!scrapy抓取!但是scrapy顺着超链接抓取web网页容易,抓取微信app里的内容就有难度了,暂时还是做不到模拟一个收集app软件。庆幸的是,腾讯和搜狗搜索结婚啦!生出了一个
-
本章将介绍如何在您认证的微信公众号、订阅号中集成小能在线咨询功能 微信对接准备 微信对接模式介绍 微信授权模式 微信极速模式 微信开发模式-真Token方案 微信开发模式-假Token方案
-
配置微信公众号有什么用? 便于通过微信接收平台的消息,并且可以在用户中心自定义接收事件类型,方便即时接收消息 配置说明 1.登录基本配置" target="_blank">https://mp.weixin.qq.com/,开发->基本配置 2.配置文件 [app.cfg] ; ;[wechat] ; ;app_id: 微信公众号的应用ID ; ;access_token: 微信公众号的应用acc