《兰亭集势》专题
-
龙目岛智能集成
我在使用Lombok在IntelliJ中构建我的项目时遇到了麻烦。Lombok似乎可以正常工作,直到我去构建工件,在任何使用Lombok getter的地方都会出现这个错误。 但是,此处显示的代码没有错误: 我启用了注释处理,而lombok是一个依赖项。我似乎不明白为什么会这样,
-
集合的Solrj API/示例
我们正在使用Solrj在Solr上构建一个包装器。 此包装器将允许客户端指定集合名称,然后使用SolrJ包装器与该集合交互以进行插入/更新/查询。 有人能给我指一下SolrJ集合示例/API吗?
-
payUmoney集成出现错误
登录后,它生成了一个哈希值,但仍然给出错误“Some problem currened!try tain”。
-
记录富集用NiFi流
我正在使用NIFI1.11.4构建一个数据管道,其中IoT设备以JSON格式发送数据。每次从IoT设备接收数据时,都会收到两个JSONS; JSON_Initial 和JSON_FINAL
-
Firestore子集合与阵列
首先,我知道Firestore是如何工作的,并且花了很多时间评估不同的方法以获得良好的结构。但我仍在考虑以下情况: 有一个已知食谱的数据库。用户可以添加菜谱,但必须确认它们是真正的菜谱,而不仅仅是一些变体。因此,每个用户都可以从用户生成的食谱列表中选择receipes,说明他们知道如何烹饪(或添加新的)。 现在,我希望用户与其他人分享他们的receipes列表,但我不确定如何最好地使用Firest
-
同步集合中的ConcurrentModificationException
我正在使用面临的问题是,当我运行下面的代码时,我得到了。 据我所知,代码应该毫无例外地终止。 有人能帮我理解为什么我会得到这个例外吗。
-
初始化惰性集合
我正在开发一个Struts2 Spring Hibernate webapp,我需要在检索一个对象或该对象的集合后初始化一个惰性集合。 用例 我有一个团队模型,其关系被热切地加载为员工(我认为这显然是一个集合)。反过来,员工模型有一个懒惰的关系注册表,我只需要一些特定的操作,所以我根本不需要急切地加载它。 现在。我调用我的(用Spring注入到我的Struts2控制器中),以便检索一个特定的已经加
-
MySQL群集复制配置
我正在尝试在两个MySQL集群之间使用单个复制通道设置复制。我已经看了mysql.com的文档几次了,但似乎不能让它正常工作。 我遇到的问题是,对未配置为主服务器的SQL节点进行的查询不会复制NDBCLUSTER表的任何INSERT、UPDATE或DELETE查询,然而,当我在作为主服务器的SQL节点上插入、更新或删除一行时,它会很好地复制到其他集群。 我知道复制是设置的,因为如果我在主集群中的任
-
 Mandelbrot集缩放和平移
Mandelbrot集缩放和平移我在Java中编码了一个Mandelbrot集分形,并包含了平移和放大分形的能力。唯一的问题是,当我平移图像并试图放大时,它看起来好像试图放大中心并平移一点。平移和缩放不是真正的平移或缩放,而是对分形的重新计算,看起来像是平移或缩放。 这是我的代码。 我能告诉用户在哪里可以让相机更精确地缩放吗? 先谢谢你。 编辑:图片对于任何想知道这个程序将呈现什么。
-
 Matlab中Mandelbrot集的着色
Matlab中Mandelbrot集的着色我制作了一个程序来计算mandelbrot集合中的点。对于不属于mandelbrot集的点,我会记录起点发散到震级大于2的地方所需的迭代次数。基本上,对于mandelbrot集合之外的每一点,我都有一个计数器,可以显示它在1到256的范围内发散的速度。我想做的是根据每个点发散的速度给它一个颜色。例如,在255次迭代中发散的点可能是白色的,发散越快,着色越多。我已经做了一个简单的调整,在20步以上的
-
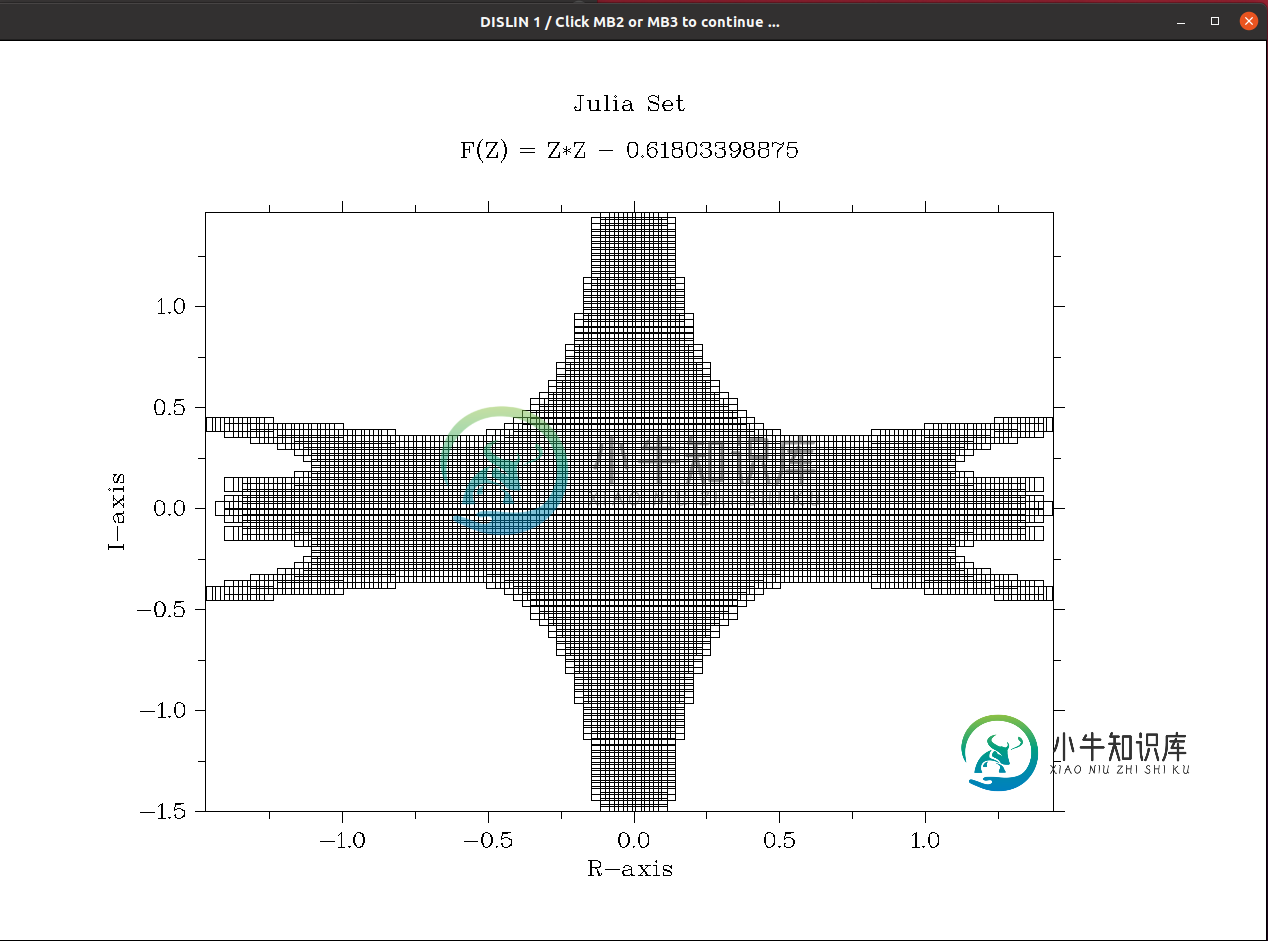 用C(DISLIN)生成Mandlebrot集
用C(DISLIN)生成Mandlebrot集我试图用c生成mandlebrot集,但我得到了一些不正确的输出 . . . 这个代码有什么问题? 这是输出 它只与这里的结果具有对称性: https://en.wikipedia.org/wiki/Julia_set#/media/File:Time_escape_Julia_set_from_coordinate_(phi-2,_0). jpg 能得到一些想法会很棒 K
-
 Mandelbrot集合中的形状
Mandelbrot集合中的形状迷人可爱的Mandelbrot集箍和卷曲是浮点计算不准确的结果吗? 我编写了各种Mandelbrot集实现,例如动态缩放和回放。一些使用定点算法,另一些使用FPU。 我见过这个问题,它表明每一个芽都是数学上光滑的形状,周围有较小的芽。 海马形状等的游行是计算机浮点运算局限性的副作用,而不是实际的曼德布罗特集吗? 海马?由Spektre添加: 我一直想说的是,浮点运算,无论是定点运算还是固定意义运算
-
如何集成rsyslog、AWS ELB
我一直使用php脚本将日志写入rsyslog,然后rsyslog在tcp端口上直接向flume(syslogtcp源)发送消息。 现在,当我迁移到AWS时,我想在rsyslog之间引入一个ELB(弹性负载均衡器)层 这方面的任何帮助都将是巨大的。
-
WebSphere MQ与水槽集成
我正在尝试将 Websphere (IBM) MQ 与 flume 集成。我有几个来自MQ的xml文件 我正在AWS EC2实例上进行此集成,其中也安装了我的Hadoop。以下是我遵循的集成步骤。 创建队列管理器:https://www.ibm.com/support/knowledgecenter/SSFKSJ_7.5.0/com.ibm.mq.con.doc/q015210_.htm ./cr
-
火花流集成水槽
我遵循火花流水槽集成的指导。但我最终无法获得任何事件。(https://spark.apache.org/docs/latest/streaming-flume-integration.html)谁能帮我分析一下?在烟雾中,我创建了“avro_flume.conf”的文件,如下所示: 在文件中,123.57.54.113是本地主机的ip。 最后,根本没有任何事件。 怎么了?谢谢!