《推荐算法》专题
-
 java实现最短路径算法之Dijkstra算法
java实现最短路径算法之Dijkstra算法本文向大家介绍java实现最短路径算法之Dijkstra算法,包括了java实现最短路径算法之Dijkstra算法的使用技巧和注意事项,需要的朋友参考一下 前言 Dijkstra算法是最短路径算法中为人熟知的一种,是单起点全路径算法。该算法被称为是“贪心算法”的成功典范。本文接下来将尝试以最通俗的语言来介绍这个伟大的算法,并赋予java实现代码。 一、知识准备: 1、表示图的数据结构 用于存储图的
-
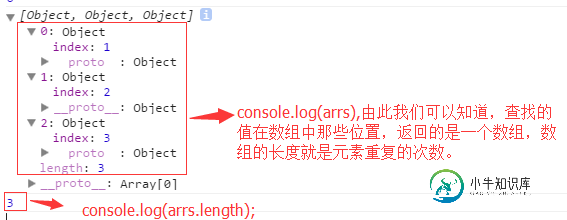 javascript数据结构与算法之检索算法
javascript数据结构与算法之检索算法本文向大家介绍javascript数据结构与算法之检索算法,包括了javascript数据结构与算法之检索算法的使用技巧和注意事项,需要的朋友参考一下 查找数据有2种方式,顺序查找和二分查找。顺序查找适用于元素随机排列的列表。二分查找适用于元素已排序的列表。二分查找效率更高,但是必须是已经排好序的列表元素集合。 一:顺序查找 顺序查找是从列表的第一个元素开始对列表元素逐个进行判断,直到找到了想要的
-
理解Dijkstra算法的时间复杂度计算
每个顶点可以连接到(V-1)个顶点,因此每个顶点的相邻边数是V-1。假设E代表连接到每个顶点的V-1条边。 查找和更新最小堆中每个相邻顶点的权重为O(log(V))+O(1)或 因此,从上面的步骤1和步骤2,更新顶点的所有相邻顶点的时间复杂度是e*(logV)。或. 因此所有V顶点的时间复杂度为V*(E*logv),即。 但Dijkstra算法的时间复杂度为O(ElogV)。为什么?
-
无法计算出此算法的运行时间
我被要求为这个问题编写一个算法:给我们一个数组A,我们想知道数组中是否有两个元素U和L,U和L=K 我是这样写我的算法的: 但问题是,这个算法的运行时间是多少?它是O(nlogn)吗?如果是,为什么?如果不是,我如何在O(nlogn)中实现它?
-
算法计算一个数适合的最小和
给定一组数,找出任意数适合的最小倍数和 < li >集合中的数字可以多次使用(或根本不使用)以获得“总和” < li >这组数字可以是任何正十进制数(即< code>1,4,4.5 ) < li >给定/任意数阈值可以是任意小数(即< code>5 ) > < li> 找出给定数字能与最小余数相适应的倍数组合 找到一个数字可以四舍五入到的最小“总和” 每个组合中使用的实际数字本身对于这个特定的挑战
-
 快手计算机视觉算法一面凉经
快手计算机视觉算法一面凉经先自我介绍,然后主要问项目的区别,yolov5主要改进点在哪,transform为什么能用于cv。你用yolov5跑模型,你的改进点在哪,效果提升多大。 看我用过tensorrt,介绍一下tensorrt优化的流程及常见的tricks。 代码题是二叉树的,不是子父节点的最大和。用dfs没做出来,少考虑了一种情况,然后就寄了。 #快手校招##算法工程师#
-
数据结构与算法 - 最短路径算法
Dijkstra——贪心算法 从一个顶点到其余顶点的最短路径 设G=(V,E)是一个带权有向图,把图中顶点集合V分成两组,第1组为已求出最短路径的顶点(用S表示,初始时S只有一个源点,以后每求得一条最短路径v,...k,就将k加到集合S中,直到全部顶点都加入S)。第2组为其余未确定最短路径的顶点集合(用U表示),按最短路径长度的递增次序把第2组的顶点加入S中。 步骤: 1. 初始时,S只包含源点,
-
 大疆笔试-计算机视觉算法B卷
大疆笔试-计算机视觉算法B卷一、单选: 1、CLIP模型的主要创新点:图像和文本两种不同模态数据之间的深度融合、对比学习、自监督学习 2、一个3*3,stride=1,dilation=1的卷积加上一个步长为2的2*2池化,再加上一个3*3 ,stride=3,dilation=1的卷积对应的等效步长是多少:6(第一步不改变步长,第二步步长为2,第三步步长为2*3) 3、a=np.random.randn(3,3) b=np
-
 第四范式计算机视觉算法面经
第四范式计算机视觉算法面经4.18 技术面 问项目经历,多模态、大模型算法的了解和理解。手撕三个bbox的iou计算。 4.24 hr面 常规hr面。 4.26 发感谢信没过。
-
使用URL发布推特,通过API解析推特(使用tweepy)
我正在尝试使用tweepy(用于twitter的python api)发布推文。我有一个很长的url,使用itty bitty来承载一个降价页面。该链接可以通过twitter网站(此处为tweet)发布,但不能通过api发布。返回的错误表明tweet太长: 我已经确保tweet低于字符限制,减去t.co缩短的URL限制使用的字符(目前每个URL 23个)。不确定下一步要尝试什么?
-
TesorFlow Lite推理给出不同的结果然后规则推理
我有一个模型,可以从图像中提取512个特征(数字介于-1,1之间)。我使用此处的说明将此模型转换为tflite浮点格式https://github.com/tensorflow/tensorflow/tree/master/tensorflow/contrib/lite 我对原始模型和tflite模型的同一个图像进行了推断。 对于向量,我得到了不同的结果,我希望得到非常相似的结果,因为我没有使用量
-
如何修复:AndroidTensorFlow Lite推理比标准TensorFlow推理慢得多
我用TensorFlow和Keras开发并训练了一个卷积神经网络。现在,我想把这个模型部署到Android设备上,在那里我需要它来实现实时应用。 我找到了两种将Keras模型部署到Android的方法: 将图形冻结为.pb文件(例如“model.pb”),然后在Android设备上使用“TensorFlowInferenceInterface” 将冻结的图形转换为.tflite模型(例如“mode
-
Azure推送通知中心是否支持iOSPushKit VoIP推送通知?
我在PushKit VoIP通知上发现了一些与Azure通知中心支持相关的帖子: https://social.msdn.microsoft.com/Forums/ie/en-US/afda14fe-1218-4ca1-a1ee-205ccd241d1a/support-for-apple-voip-pushkit-push-notifications?forum=notificationhubs
-
vue.js - 疑惑:vue3使用props传递数据的时候,该属性是一个对象,实际情况下,到底推不推荐在子组件直接修改对象内部的属性?
假如父组件中是这样一个复杂的对象,传递给多个子组件,不同子组件要处理该修改中不同的属性,我目前的处理是直接在子组件中修改如props.params.approveStatus = 2,当然官方并不推荐这种处理,实际情况如何处理更好一些呢?
-
字段的算术运算
问题内容: 是否可以查询两个字段之间相减的结果? 例如,有两个字段:“开始”,“结束”。我想要带的文件。 可以直接完成此操作吗,还是唯一的方法是在加载具有这种差异的文档时创建一个新字段? 问题答案: 查询中的脚本过滤器可能是解决方法。 http://www.elasticsearch.org/guide/zh- CN/elasticsearch/reference/current/query-ds