《数据区》专题
-
 【2023校招】巨杉数据库 数据库开发
【2023校招】巨杉数据库 数据库开发1101 - 技术面 自我介绍 实习经历 K8S: K8S 和 Spring Cloud 了解 如何基于 K8S 部署服务 K8S 部署服务的流程 基于 Spring 开发过的个人项目,是课程吗 对巨杉了解 算法 1103 - HR 面 自我介绍 校园经历 实习经历 Offer: 手头 Offer 及薪资待遇,偏向程度 期望薪资 相同薪资的 Offer 如何选择 个人优势 反问 #面经##校招##
-
第六章 海量数据处理 - 6.10 数据库
方法介绍 当遇到大数据量的增删改查时,一般把数据装进数据库中,从而利用数据的设计实现方法,对海量数据的增删改查进行处理。
-
E 数据透视表的数据汇总方式
数据透视表的优势在于,我们可以很方便的从不同的角度,对数据进行不同方式的汇总统计。前面我们创建的数据透视表都是以求和的方式计算金额合计。那么当我们希望汇总的信息不是求和,而是计算平均值或者计数那么该如何处理呢? E.1 改变数据汇总方式 比如,我们希望统计每种产品被销售的次数。这时候就需要对产品进行计数统计。我们可以将“产品名称”字段分别拖拽到“行标签”区域和“数值”区域,由于“产品名称”字段的内
-
A 数据透视表和数据透视图表
A 数据透视表介绍 B.1 什么是数据透视表? 数据透视表是一种可以快速汇总、分析大量数据表格的交互式工具。使用数据透视表可以按照数据表格的不同字段从多个角度进行透视,并建立交叉表格,用以查看数据表格不同层面的汇总信息、分析结果以及摘要数据。使用数据透视表可以深入分析数值数据,以帮助用户发现关键数据,并做出有关企业中关键数据的决策。 数据透视表是针对以下用途特别设计的:以友好的方式,查看大量的数据
-
1.6.5 数据开发案例-电梯数据开发
数据开发-电梯数据开发举例 离线数据开发 实时数据开发 数据开发-电梯数据开发举例 更新时间:2018-02-01 21:17:58 假设电梯设备,每天都会定时上传数据,每台电梯每隔1分钟会上传一次数据,包括电梯id,运行状态(上行,下行,停止),门状态(打开,关闭),数据会进入离线表和实时的METAQ。 离线数据开发 业务需求:电梯利用率情况(某个单位的电梯在某个小时段内利用率,可以减少这个单位
-
jQuery EasyUI 数据网格 – 取得选中行数据
pre { white-space: pre-wrap; } 本实例演示如何取得选中行数据。 数据网格(datagrid)组件包含两种方法来检索选中行数据: getSelected:取得第一个选中行数据,如果没有选中行,则返回 null,否则返回记录。 getSelections:取得所有选中行数据,返回元素记录的数组数据。 创建数据网格(DataGrid) <table id="tt"
-
 3.1腾讯游戏数据,数据开发一面
3.1腾讯游戏数据,数据开发一面先自我介绍 我看你是Java ,c和c++了解吗?(只在本科学过c基础,没有实际开发过 平时用windows 还是Linux开发?(win写代码,部署需要用Linux Linux 关于网络和查询命令用过哪些?(ps Grep 查看运行程序,docker 的命令,还有nohup 这种,网络防火墙的firewall 有用过查看网络状态,网络接口之类的命令吗?没有 那你说一下哪个命令?忘了,我都没记
-
mysql源码解读——数据到文件之数据
主要内容:一、数据,二、数据写入,三、源码分析,四、总结一、数据 数据库落盘前面讲了日志,今天分析一下数据的落盘,麻烦的很。但是原理都差不多。在前面的分析已经可以明确知道,在MySql中,不管哪种数据,都是先进入缓存,然后再落盘保存。而在数据库,最重要的是什么?当然是数据,不管你是什么2PC,什么缓存,什么线程等等。最终的目的都是保证数据的安全应用。说的直白一些,就是满足各种SQL语句的操作,支持数据的各种恢复备份以及数据库的迁移。马Sir不是说过,以
-
 求中证数据数据技术岗面经😭
求中证数据数据技术岗面经😭#面经# #中证数据#
-
数据库 - dolphindb 批量数据写入去重复?
dolphindb 目前使用的 是 pool = ddb.DBConnectionPool("0.0.0.0", 8903, 20, "admin", "123456") appender = ddb.PartitionedTableAppender("dfs://dd", "dd", "instrument_id", pool) 多线程 线程池写入 问题是: 批量写入有重复 怎么去除重复呢 写入
-
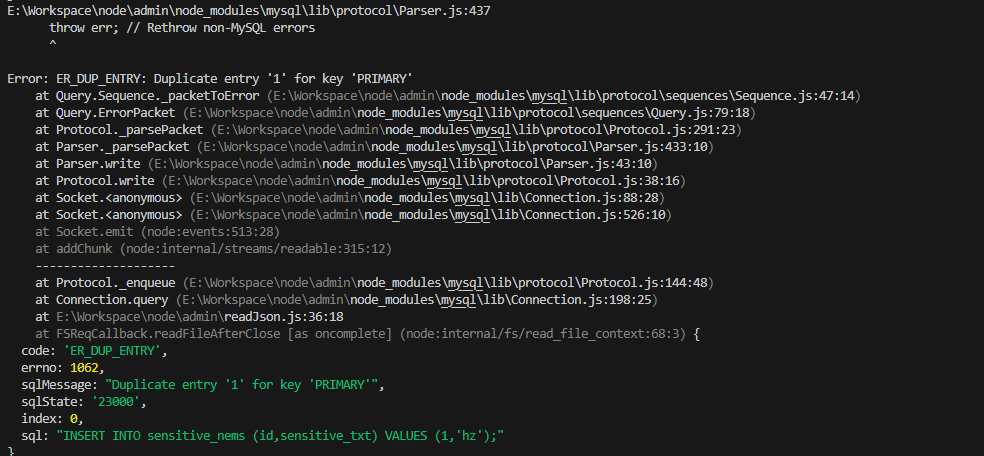 node.js - nodejs往数据库插入数据的问题?
node.js - nodejs往数据库插入数据的问题?拿到了一份敏感词的json文件,想通过nodejs循环插入数据库中 但是每次都会报错,不知道是怎么回事,有大佬帮忙看看呗 报错 设计的表
-
 一面数据-数据分析实习生面经
一面数据-数据分析实习生面经写在前面:这个岗位重视可视化的能力,在去年一战失败后也投过这个岗位的正职,面试前和面试中都在问有没有相应的可视化作品,对于实习生希望熟悉sql和tableau,一来就可以干活 1.自我介绍 2.对于以往实习经历和项目浅挖 3.次日留存sql代码考察 4.询问了不了解窗口函数 5.利用窗口函数计算不同品类前十GMV 6.tableau和power bi知识点考察 -技术问题一直准备的sql,DAX公
-
通过从配置单元表中读取数据创建的spark数据帧的分区数
我对spark数据帧的分区数量有疑问。 如果我有包含列(姓名、年龄、id、位置)的Hive表(雇员)。 如果雇员表有10个不同的位置。因此,在HDFS中将数据划分为10个分区。 如果我通过读取 Hive 表(员工)的整个数据来创建 Spark 数据帧(df)。 Spark 将为数据帧 (df) 创建多少个分区? df.rdd.partitions.size = ??
-
oracle中逻辑备用数据库与物理备用数据库的区别
本文向大家介绍oracle中逻辑备用数据库与物理备用数据库的区别,包括了oracle中逻辑备用数据库与物理备用数据库的区别的使用技巧和注意事项,需要的朋友参考一下 逻辑备用数据库和物理备用数据库中有两种不同类型的备用数据库。如果主数据库发生故障,Oracle将数据从主数据库传输到备用数据库。这种方法可帮助我们在发生任何故障时从备用数据库恢复数据。 逻辑备用数据库不是主数据库的确切副本。逻辑备用数据
-
C ++中基本数据类型与派生数据类型之间的区别
本文向大家介绍C ++中基本数据类型与派生数据类型之间的区别,包括了C ++中基本数据类型与派生数据类型之间的区别的使用技巧和注意事项,需要的朋友参考一下 在编程中,数据类型表示打算由用户使用的数据的类型和性质。它是编译器或解释器要处理的数据类型,并在主存储器中提供相应的存储位置。 现在根据数据的性质,数据类型主要有两种类型,一种是基本数据类型,另一种是派生数据类型。这两种数据类型都在编程中使用,