《map》专题
-
无法运行mapreduce wordcount
我正在尝试自学一些hadoop基础知识,因此已经构建了一个简单的hadoop集群。这样可以工作,并且我可以从hdfs文件系统中put,ls,cat而没有任何问题。所以我采取了下一步,尝试对我放入hadoop的文件进行单词计数,但我得到了以下错误 我可以ls Hadoop: hadoop版本: hadoop类路径: 很明显我错过了什么,所以谁能给我指出正确的方向。
-
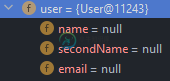 如何使mapstruct映射器返回null而不是所有字段都设置为null的新对象
如何使mapstruct映射器返回null而不是所有字段都设置为null的新对象大家好! 我正在Spring应用程序中实现Mapstruct映射器。 有两个相关实体:和。只是为了简化->用户可以有许多订单。 OrderMapper类: 好吧,我的问题是: 如果我使用以下命令传递OrderDTO: 前面描述的情况在我的应用程序中造成了巨大的问题。如果有任何帮助,我将不胜感激。
-
当从MapStruct收到错误“目标属性的几个可能源属性”时,如何避免显式映射?
我有mapstruct映射器的实现如下 没有注释的行,我收到以下错误: 错误:(20,14)Java:目标属性“status”的几个可能的源属性。 我是否可以通过添加一些注释来避免上面的样板(显式映射),说明Pojo1具有更高的优先级?我研究了Java文档和mapstruct的源代码,但没有任何示例或线索对我的情况有帮助。我试图用InheritanceStrategy找到一些东西,但它看起来很像M
-
Mapstrtuct:嵌套对象。仅当源元素不为空时才创建目标对象
我想映射嵌套的java对象。改为。 期望:当且仅当不为null,则在下创建对象。否则,不要创建任何目标对象。 问题:我在映射器中使用了。但是mapstruct正在检查是否为null,然后创建。在中,为空。我希望在(leaf/last level object)之前进行空检查,然后创建目标对象。 请告诉我该如何做到这一点 下面是我正在使用的映射。 生成的代码位于https://github.com/
-
Mapstruct映射:如果所有源参数属性都为null,则返回null对象
如果(tagrecord.gettagid()==null&&tagrecord.gettaglabel()==null),我实际上希望生成的方法返回一个null标记对象。有没有可能,我该如何实现这一点?
-
当我试图运行mapreduce应用程序时,它没有运行或占用更多时间
我是hadoop的新手,尝试在hadoop 2.6.0中设置两个数据节点的hadoop多节点集群,但是当我尝试运行mapreduce应用程序时,它没有运行或者占用更多的时间,但是所有的恶魔都在每两个节点上运行得很好。 [hadoop@slave~]$jps 13406 MRAppMaster 9225 NodeManager 9072 DataNode 13591 jps[hadoop@maste
-
Hadoop MapReduce作业无法在本地加载库,并导致OS X上的连接失败
我正在尝试在OS X Yosemite上运行hadoop。当我按照http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/singlecluster.html中的说明进行操作时,我配置了hadoop,并启动$sbin/start-dfs.sh,然后使用jps检查得到了输出: 但是,当我尝试“bin/hdfs d
-
使用Mapstruct作为JOOQ的记录映射器
我想实现我自己的并使用Mapstruct将记录映射到POJO。我不太明白如何完成这一点。我遵循了这部分文档:https://www.jooq.org/doc/3.13/manual/sql-execution/fetching/pojos-with-recordmapper-provider/ 我的映射器看起来像这样: 问题是,作为我实际上并没有得到,而是我的语言表中的,因此无法将转换为。知道我需
-
按值长度对Map进行排序
我想按值长度对Map进行排序。例如,我有这样的代码: 结果是: 所以我想做的是按值长度对这个Map进行排序,所以它返回:
-
使用angularjs google maps在标记点击上自定义infowindow
我正在使用angularjs谷歌地图,我想自定义风格的信息,这是显示在一个标记点击。ui-gmap-window标记确实有自定义选项,它单独工作也很好。然而,当我试图在标记标记(ui-gmap-markers)中使用它时,它不会在标记点击上显示自定义样式的infoWindow。plunkr清楚地解释了这个问题。
-
如何使Google Maps API2上的Android交互式信息透明
我实现了chose007的完美答案,使谷歌地图API2上的InfoWindow可以在我的应用程序中点击。唯一的问题是,我想让InfoWindow透明(使其泡泡状)。我可以使用样式包装器在非交互式InfoWindow中完成: InfoWindow显示为透明的,但是不能在以下内容中设置窗口的内容: 而且交互性并不强,因为交互性也设置在中,而且在我看来,如果返回非结果,则根本不调用此方法。 有人知道,如
-
Maps V2 InfoWindow中的动态内容
正如我们所知,是绘制的,并且以后对它的更改(在我的例子中,上的新)不会显示/不会更新。当完成时,如何“通知”InfoWindow重新加载它自己?当我把 在中,它创建了一个无限循环,在这个循环中,标记将弹出、开始加载图像、弹出自身等。 我的第二个问题是,在慢速网络连接上(用代码中的5000ms延迟进行模拟),中的将始终显示最后加载的图像,无论该图像是否属于该/。 对如何有效实施这一点有什么建议吗?
-
为提到的gremlin查询在gremlin中的map中存储节点的值而不是节点的Id
我使用了下面给出的查询g.V().as('out').out().as('in')。select('out','in')。groupCount()。unfold()。filter(select(values)。is(gt(1))。select(keys) 它显示出:v[1234],在:v[3456]...... 但我不想显示节点的ID,而是想显示节点的值,比如out:ICIC1234,in:HDF
-
HazelCast MapStore能否在客户端实现?
我将在我的项目中使用HazelCast MapStore。我有一个HazelCast服务器和一些其他客户端项目。我可以像这样实现MapStore类吗http://docs.hazelcast.org/docs/3.5/manual/html/map-persistence.html在客户项目中? 我关心的是配置。我发现我无法在客户端设置或更改HazelCast配置。MapStore的配置如何?
-
Hazelcast文件持久性(MapStore实现)
我正在使用Hazelcast进行集群数据分发。我阅读了有关使用MapStore和MapLoader接口的数据持久性的文档。我需要实现这些接口,并在hazelcast中编写类名。xml文件。 有没有使用hazelcast实现这些文件持久性接口的示例?有人知道我可以下载和使用的任何源代码或jar文件吗? 谢谢