《map》专题
-
Orika:java.lang.ClassCastException:java.lang.Object不能强制转换为Mapper.Name
我在这里的一节中做示例orika映射器文档,映射数组和列表的元素。 PersonDto类定义- 当我运行这段代码时,我得到以下错误- java.lang.Object不能强制转换为mapper.name java.lang.ClassCastException:java.lang.Object不能强制转换为ma.glasnost.orika.generated.orika_persondto_pe
-
Mapstruct 1.4.2。最终:NullValuePropertyMappingStrategy。将_设置为_默认值未按预期工作
我最近更新了我的Spring启动版本从2.3.0。发布到2.4.4,还更新了地图结构版本从1.3.1到最新版本。最终版本是1.4.2。最终版本。使用的lombok版本-1.18.18 但是其中一个在1.3.1上运行良好的映射器在1.4.2上不再工作,场景如下。 POM: 实体: 域名: 制图员: 使用MapStruct 1.3.1生成的代码 用Map结构1.4.2生成代码 正如您在1.4.2版本中
-
Mapreduce字数Hadoop最高频率词
因此,从Hadoop教程网站(http://Hadoop.apache.org/docs/current/hadoop-mapreduce-client/hadoop-mapreduce-client-core/mapreducetutorial.html#source_code)上,我了解了如何使用map reduce方法实现单词计数,并且输出的单词都是出现频率的。 我想做的是只有输出是最高频率
-
hadoop mapreduce作业不运行reducer
我试图运行WordCount示例的一个变体,这个变体是,映射器输出文本作为键和文本作为值,而还原器输出文本作为键和NullWritable作为值。 除了地图,减少签名,我把主要的方法是这样的:
-
mapToDouble()对于用Java8流求和列表真的有必要吗?
当然,我们可以这样做: 但是要比长得多。 我知道这与流需要围绕Java的非对象原语进行修改的方式有关,但是,我在这里是否遗漏了什么?有没有什么方法可以把自动装箱压缩到更短的地方?还是这只是目前的技术水平?
-
MyBatis-Mapped Statements集合已包含
在服务器启动时注册映射器类时抛出了以下错误消息, 下面是我的UserMapper接口,
-
如何提取从Avro中的GenericRecord中键入的Map?
我有一个通用记录,如下所示,其中是一个值为字符串的映射。 下面是holder map的数据: 我想提取字符串和字符串映射中的holder数据。我不知道该怎么做?我尝试了两个选项,如下所示: 此返回对象: 这返回一个Map,但我看不出它是一个键和值的Map。 当我打印时,我看到这样的情况,这显然不是键/值的映射。我做错了什么?以及如何从GenericRecord中提取键入的映射?
-
Java中HashMap和Map对象之间有什么区别?
我创建的以下地图之间有什么不同(在另一个问题中,人们似乎可以互换地使用它们来回答,我想知道它们是否/如何不同):
-
google mapview中的错误
我目前正在做一个应用程序,其中包含googlemap。下面给出了该xml文件的代码,但在图形布局中显示了一个错误 “缺少样式。为此布局选择的主题正确吗?使用布局上方的主题组合框选择其他布局,或修复主题样式引用。 xml和清单文件如下所示 manifest.xml
-
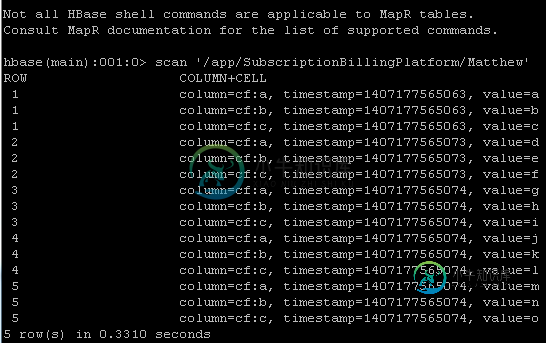 Talend MapR的tHBASEConnection和tHBaseInput
Talend MapR的tHBASEConnection和tHBaseInput我可以访问MapR Hadoop集群的边缘节点。我有一个名为/app/subscriptionbillingplatform/matthew的HBase表,里面有一些假数据。在hbase shell中扫描它的结果如下: 我有一个非常简单的Talend作业,它应该扫描表并记录每一行: 下面是ThBaseConnection的配置。我从/opt/mapr/hbase/hbase-0.94.13/con
-
如何使用Mapstruct从具有对象列表和一个或多个对象的模型实体映射到单个域实体
如何使用MapSTRt创建映射器,从模型实体,包括一个对象列表和另一个对象到域实体,只包括嵌套对象的列表。 我的模型实体列表对象=SourceObject-A; 我的模型实体第二个对象=SourceObject-B; 我的Doamin实体列表对象=目标对象AB; 我的源代码类如下所示: SourceObject-A: SourceObject-B: 所以我需要将其转换为这个(TargetObjec
-
如何启用google maps android api以实现平滑的双指缩放?
在最初的谷歌地图上,如果我用两个手指放大或缩小,缩放动画不会在释放屏幕后立即停止。它继续缓慢地放大或缩小。这很好,但在我的谷歌地图api上,当我用两个手指放大或缩小时,一旦我从屏幕上松开手指,缩放动画就会停止。有没有办法启用此功能?可能有。。我只是不知道这个效果的名字。。。也许是zoom echo?:)
-
使用MapReduce计算数字的平均值
我一直在尝试编写一些代码来使用MapReduce查找数字的平均值。 我尝试使用全局计数器来实现我的目标,但是我无法在映射器的< code>map方法中设置计数器值,也无法在缩减器的< code>reduce方法中检索计数器值。 我是否必须在< code>map中使用全局计数器(例如,通过使用所提供的< code>Reporter的< code>incrCounter(key,amount))?或者
-
在Hadoop MapReduce中,有可能有多个不同映射器的多个输入吗?
在Hadoop MapReduce中是否有可能使用多个不同的映射器有多个输入?每个映射器类都在一组不同的输入上工作,但它们都会发出由同一个减速器使用的键值对。请注意,我不是在这里谈论链接映射器,我是在谈论并行运行不同的映射器,而不是顺序运行。
-
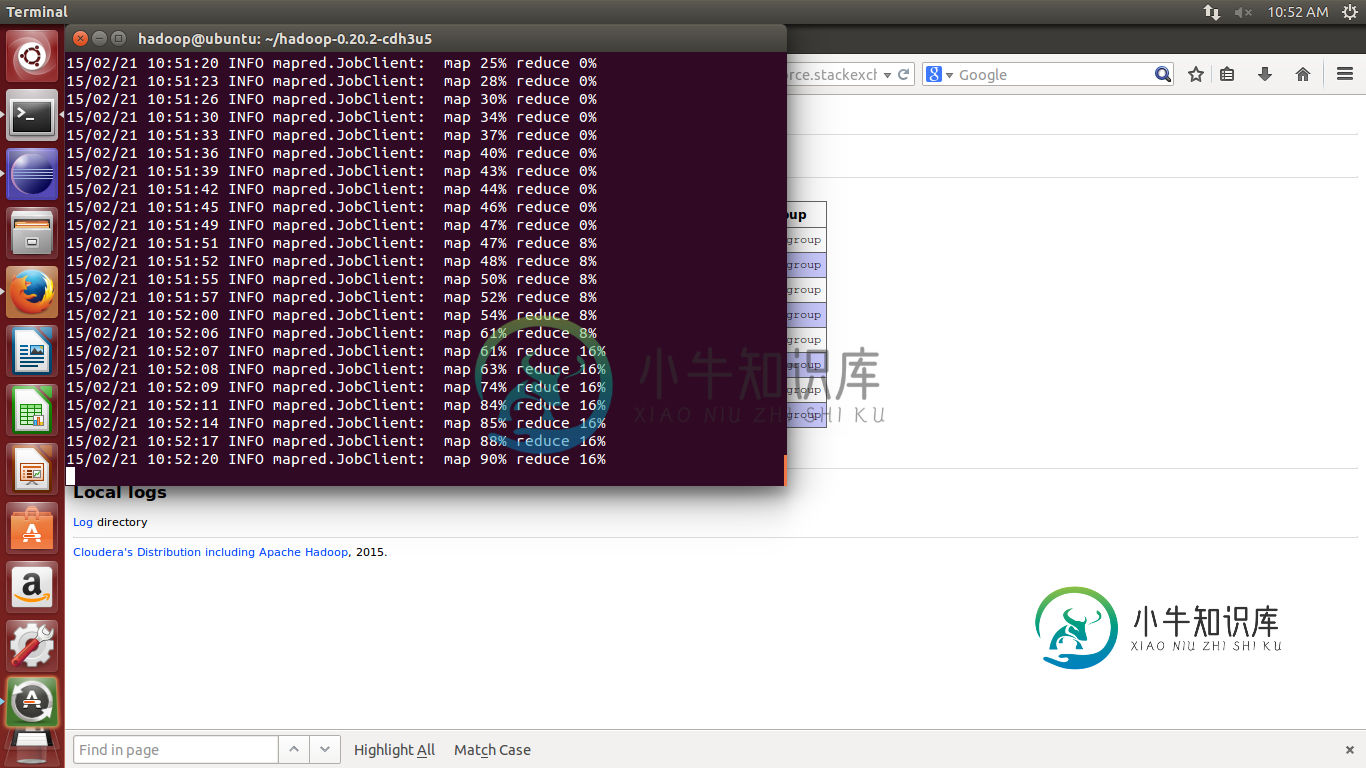 单个节点上的MapReduce执行序列
单个节点上的MapReduce执行序列我正在学习Hadoop。 我在单节点上运行Hadoop。 据我所知,Reducer在Mapper完成后运行(这也是有道理的)。 但是当我在200MB文件上运行MapReduce作业时,Reducer在Mapper完成之前就启动了。我没有使用任何组合器。 谁能解释一下为什么?