《性能测试》专题
-
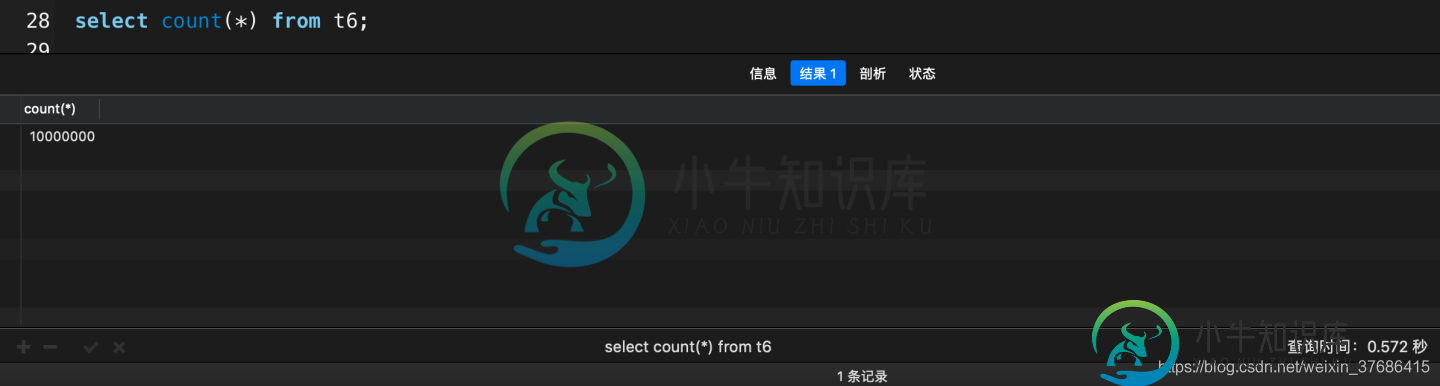 聊聊MySQL的COUNT(*)的性能
聊聊MySQL的COUNT(*)的性能本文向大家介绍聊聊MySQL的COUNT(*)的性能,包括了聊聊MySQL的COUNT(*)的性能的使用技巧和注意事项,需要的朋友参考一下 前言 基本职场上的程序员用来统计数据库表的行数都会使用count(*),count(1)或者count(主键),那么它们之间的区别和性能你又是否了解呢? 其实程序员在开发的过程中,在一张大表上统计总行数是非常耗时的一个操作,那么我们应该用哪个方法统计会更快呢?
-
php字符串串联,性能
问题内容: 在Java和C#之类的语言中,字符串是不可变的,并且一次建立一个字符的字符串在计算上是昂贵的。在上述语言中,有一些库类可以降低这种成本,例如C#和Java 。 php(4或5;我对两者都感兴趣)是否都共享此限制?如果是这样,是否有类似的解决方案? 问题答案: 不,在PHP中没有stringbuilder类的类型,因为字符串是可变的。 话虽如此,根据您在做什么,有不同的方式来构建字符串。
-
反应本机性能问题
问题内容: 我正在使用coincap api首先获取大约1500多种加密货币的数据,然后通过网络套接字更新加密货币的更新值。 我正在使用redux在这里管理我的状态 在My内部,我正在调用 redux动作 来获取硬币的价值 然后在我做这样的事情 然后我有一个网络套接字,它像这样更新了加密货币的价值 现在,尽管这项工作有效,但问题在于,这使我的应用程序变慢了,因为每当套接字发送新数据时,它都必须渲染
-
括号()和SQL查询性能
问题内容: 在where语句中,添加不必要的括号是否 会影响SQL性能? 例子: 问题答案: 不,没有任何重要意义。 该查询被解析一次,在此阶段,一些额外的括号可能意味着执行时间略有不同,但是您必须要有很多括号才能进行测量。 一旦查询被解析并开始执行,它的行为将与没有多余括号的行为完全相同。仅保留实际操作。
-
 golang json性能分析详解
golang json性能分析详解本文向大家介绍golang json性能分析详解,包括了golang json性能分析详解的使用技巧和注意事项,需要的朋友参考一下 前言 众所周知Json 作为一种重要的数据格式,具有良好的可读性以及自描述性,广泛地应用在各种数据传输场景中。Go 语言里面原生支持了这种数据格式的序列化以及反序列化,内部使用反射机制实现,性能有点差,在高度依赖 json 解析的应用里,往往会成为性能瓶颈,好在已有很
-
MongoDB性能优化及监控
本文向大家介绍MongoDB性能优化及监控,包括了MongoDB性能优化及监控的使用技巧和注意事项,需要的朋友参考一下 MongoDB 是一个基于分布式文件存储的数据库。由 C++ 语言编写。旨在为 WEB 应用提供可扩展的高性能数据存储解决方案。 MongoDB 是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。 一、索引 MongoDB 提供了多样性
-
在PHP中try-catch的性能
问题内容: 在PHP 5中使用try-catch语句时,要考虑什么样的性能影响? 以前,我已经在网上阅读了一些有关该主题的古老的,看似矛盾的信息。我目前必须使用的许多框架都是在php 4上创建的,并且缺少php 5的许多优点。因此,我在使用try-catchs与php方面经验不足。 问题答案: 要考虑的一件事是,没有引发异常的try块的开销与实际引发和捕获异常的开销是一个不同的问题。 如果仅在失败
-
python和sqlite3的插入性能
问题内容: 我正在向SQLite3数据库中进行大批量插入,并且试图了解我应该期望的性能与实际看到的性能之间的关系。 我的桌子看起来像这样: 和我的插入看起来像这样: 元组列表在哪里。 目前,在一台2008年的Macbook上运行,在数据库中大约有1200万行的情况下,插入行花了我大约16分钟的时间。 这听起来合理吗,还是发生了什么大事? 问题答案: 据我了解,性能不佳的主要原因是浪费时间来执行许多
-
表与临时表的性能
问题内容: 数百万条记录的哪个更快:永久表 还是 临时表? 我只需要将其用于1500万条记录。处理完成后,我们将删除这些记录。 问题答案: 在您的情况下,我们使用称为临时表的永久表。这是大量进口的常用方法。实际上,我们通常使用两个登台表,一个带有原始数据,另一个带有清理后的数据,这使得研究提要中的问题变得更加容易(它们几乎总是我们客户发现向我们发送垃圾数据的新方式和多种方式的结果,但是我们必须
-
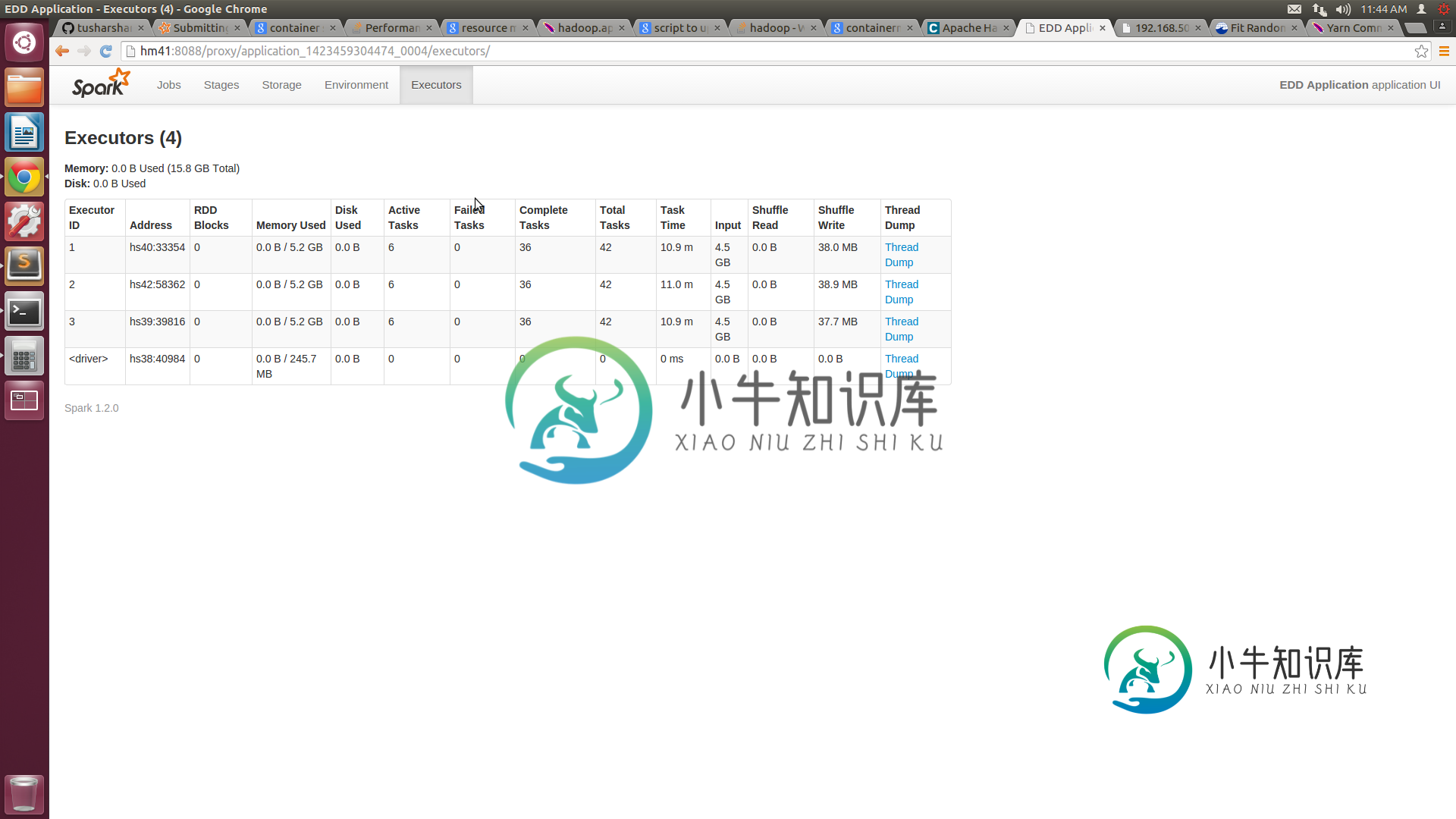 火花线的性能问题
火花线的性能问题我们正在尝试在纱线上运行我们的火花集群。我们有一些性能问题,尤其是与独立模式相比。 我们有一个由5个节点组成的集群,每个节点都有16GB的RAM和8个核心。我们已将纱线站点中的最小容器大小配置为3GB,最大为14GB。xml。向纱线集群提交作业时,我们提供的执行器数量=10,执行器内存=14 GB。根据我的理解,我们的工作应该分配4个14GB的容器。但spark UI仅显示3个容器,每个容器的容量
-
PHP中的FOR循环性能
问题内容: 当我的研究使我相信循环是PHP中最快的迭代构造…为了使它更清晰时,您认为以下哪个会更快? 示例一 示例二 我的逻辑是,在示例中的每次迭代中,在每次迭代中访问myLargeArray的长度比在示例二中访问简单的整数值要昂贵。那是对的吗? 问题答案: 第一种方法较慢,因为必须在循环的每次迭代中都调用该函数。该方法本身非常快,但是调用该函数仍然有一些开销。通过将其移动到循环之外,您正在执行所
-
Java拆分字符串性能
问题内容: 这是我的应用程序中的当前代码: 在对应用程序进行性能分析时,我注意到用于拆分字符串的时间不可忽略。 我还了解到,实际上需要一个正则表达式,这对我来说毫无用处。 所以我的问题是, 我可以使用哪种替代方法来优化字符串拆分? 我见过,但是速度更快吗? (我会尝试并测试自己,但是对我的应用程序进行性能分析需要花费很多时间,因此,如果有人已经知道答案,那么可以节省一些时间) 问题答案: 如果您的
-
Scala vs Java,性能和内存?
问题内容: 我热衷于研究Scala,并提出了一个似乎无法找到答案的基本问题:一般来说,Scala和Java在性能和内存使用方面是否有所不同? 问题答案: Scala使得无需意识到即可轻松使用大量内存。这通常非常强大,但有时可能很烦人。例如,假设您有一个字符串数组(称为),以及从这些字符串到文件的映射(称为)。假设您要获取地图中所有来自长度大于两个的字符串的文件。在Java中,您可能 ew!辛苦了
-
性能:子查询或联接
问题内容: 我对子查询的性能/连接另一个表有一些疑问 这是我的SQL,现在这个东西可以运行大约一百万次或更多。我的问题是什么会更快? 如果我更改为() 或者 如果我将’HelpTable’添加到中并在中进行联接? edit1 好吧,此脚本仅运行与r个人一样多的人。 我的程序有2个模块,一个模块填充,另一个模块传输数据。该程序确实将2个数据库合并在一起,因此有时会使用相同的Key。 现在,我正在研究
-
多键映射-性能比较
我们的应用程序将大量数据存储在内存中,存储在多种不同类型的地图中,以便快速查找。为了保持简单(不考虑原始贴图),它始终是一个带有一个或多个键的贴图。性能对我们来说是一个很大的要求。 我想找到性能最好的地图实现,正如这里建议的那样,我比较了这些实现: > java中的包装键(元组作为键)。util。哈希图 元组作为网络中的键。openhft。科洛博克。收集地图搞砸HashObjObjMap,根据这一