《性能测试》专题
-
Android性能优化系列
Android 应用性能优化系列 原文链接分别为 : https://www.youtube.com/playlist?list=PLWz5rJ2EKKc9CBxr3BVjPTPoDPLdPIFCE https://www.udacity.com/course/ud825 译者 : 胡凯 Android性能优化典范 Android性能优化之渲染篇 Android性能优化之运算篇 Android性能
-
spark性能调优(官方)
由于大部分Spark计算都是在内存中完成的,所以Spark程序的瓶颈可能由集群中任意一种资源导致,如:CPU、网络带宽、或者内存等。最常见的情况是,数据能装进内存,而瓶颈是网络带宽;当然,有时候我们也需要做一些优化调整来减少内存占用,例如将RDD以序列化格式保存。 本文将主要涵盖两个主题:1.数据序列化(这对于优化网络性能极为重要);2.减少内存占用以及内存调优。同时,我们也会提及其他几个比较小的
-
操作etcd集群 - 性能
注:内容翻译自 Performance 理解性能 etcd 提供稳定的,持续的高性能。两个定义性能的因素:延迟(latency)和吞吐量(throughput)。延迟是完成操作的时间。吞吐量是在某个时间期间之内完成操作的总数量。当 etcd 接收并发客户端请求时,通常平均延迟随着总体吞吐量增加而增加。在通常的云环境,比如 Google Compute Engine (GCE) 标准的 n-4 或者
-
保证渲染的性能
为了保障组件的性能, 我们有的时候会从组件渲染的角度出发. 更干净的render函数? 这个概念可能会有点让人疑惑. 其实在这里干净是指我们在shouldComponentUpdate这个生命周期函数里面去做浅比较, 从而避免不必要的渲染. 关于上面的干净渲染, 现有的一些实现包括React.PureComponent, PureRenderMixin, recompose/pure 等等. 第一
-
多线程性能开销
问题内容: 所以基本上我创建了这个程序,为redis添加了值。到目前为止,我得到了这个时机: 但是,当我尝试运行多个线程时: 我用set ot得到这个: 为什么我的程序在有 更多 线程的情况下运行 速度较慢 ? __ 我正在运行Linux Ubuntu 11.04和Python 2.7.1。 问题答案: 结果取决于Python的实现,cpython的GIL阻止了并行计算比顺序计算更快。 考虑使用该
-
sql计数性能问题
我有两个表用于存储员工出勤信息。 一个表存储emp Id以及相应的时间和日期时间信息。第二个表存储其他员工详细信息,如员工Id、员工姓名等。。。我需要生成一份报告,显示emp每天工作的总小时数,一个状态列存储详细信息,如Present if total hours 我写了查询来获取每一个细节,但性能是不可接受的,需要大约30-35分钟来获取所有细节 如果排除天数计算逻辑,大约需要1-2分钟 表的结
-
意外的#temp表性能
问题内容: 开放赏金:好吧,老板需要答案,我需要加薪。这似乎不是一个冷缓存问题。 更新: 我没有遵循以下建议。客户统计数据如何得出一组有趣的数字。 #temp 与 @temp INSERT,DELETE和UPDATE语句的数量0对1 受INSERT,DELETE或UPDATE语句影响的行0 vs 7647 SELECT语句数0 vs 0 SELECT语句返回的行0 vs 0 交易数量0对1 最有趣
-
火花流口水-性能
我在Scala/Spark中有一个批处理作业,它根据一些输入动态创建Drools规则,然后评估规则。我还有一个与要插入到规则引擎的事实相对应的输入。 到目前为止,我正在一个接一个地插入事实,然后触发关于这个事实的所有规则。我正在使用执行此操作。 seqOp运算符的定义如下: 以下是生成的规则的示例: 对于同一RDD,该批次花了20分钟来评估3K规则,但花了10小时来评估10K规则! 我想知道根据事
-
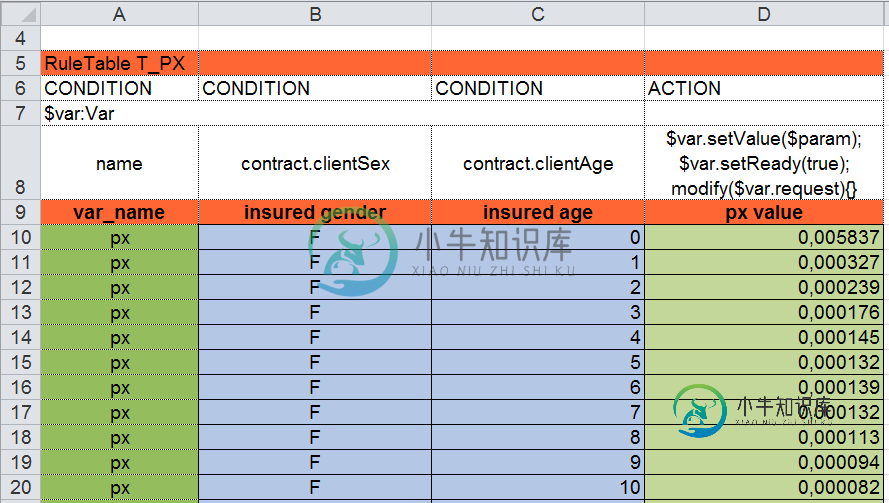 决策表的Drools性能
决策表的Drools性能当我尝试使用Drools引擎计算保险费时,我有一个潜在的性能/内存瓶颈。 我在我的项目中使用Drools将业务逻辑与java代码分开,我决定也将其用于溢价计算。 我是不是用错了口水 如何以更高性能的方式满足要求 详情如下: 我必须为给定的合同计算保险费。 合约配置有 productCode(来自字典的代码) 合同代码(来自字典的代码) 客户的个人资料(例如年龄、地址) 保险金额(SI) 等等 目前
-
Project Euler p14增强性能
我已经用以下代码完成了项目欧拉问题14: 将最长的Collatz数字序列从1000000降到2大约需要39秒。我想知道我是否可以缓存任何值来加速我的代码,以及如何在不获得无限循环的情况下从代码中删除if longestSequence[-1]==2,以及任何其他可以改进代码的方法。 为正整数集定义以下迭代序列: n→n/2(n为偶数)n→3n 1(n为奇数) 使用上述规则,从13开始,我们生成以下
-
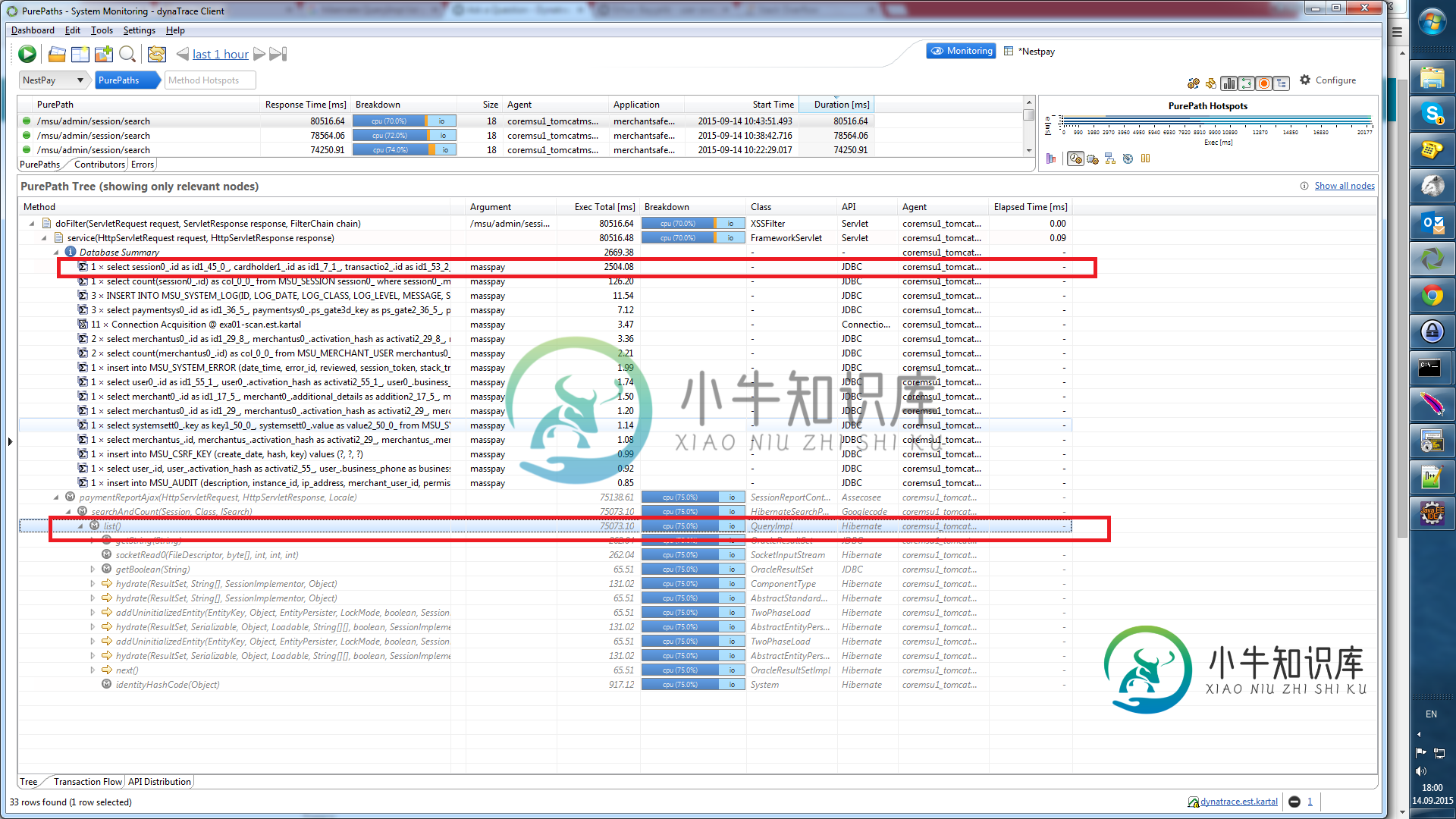 Hibernate:QueryImpl列表方法性能
Hibernate:QueryImpl列表方法性能对于我们的报告UI,我们查询sessions对象并在屏幕中列出它。为了查询数据,我们使用Hibernate和通用Dao实现。在使用Dynatrace之前,我们总是将此查询归咎于数据库,但在开始使用Dynatrace之后,它告诉我们,瓶颈在QueryImpl的代码中。列表方法。我们的Prod和Dev性能都很差,Prod中的总计数记录约为200万条,需要75秒(是的,超过1分钟:()下面的屏幕截图显示
-
HashSet vs ArrayList包含性能
问题内容: 在处理大量数据时,我经常发现自己在做以下事情: 类似于“倾销”列表中的集合内容。我通常这样做是因为添加的元素通常包含要删除的重复项,这似乎是删除它们的一种简便方法。 考虑到这个目标(避免重复),我也可以这样写: 因此,无需将集“转储”到列表中。但是,在插入每个元素之前,我会做一个小检查(我假设HashSet也是如此) 这两种可能性中的任何一种是否明显更有效? 问题答案: 集合将提供更好
-
react性能优化方案
本文向大家介绍react性能优化方案相关面试题,主要包含被问及react性能优化方案时的应答技巧和注意事项,需要的朋友参考一下 重写shouldComponentUpdate来避免不必要的dom操作0 使用 production 版本的react.js0 使用key来帮助React识别列表中所有子组件的最小变化。 参考链接: https://segmentfault.com/a/119000000
-
Spark性能如何调优?
本文向大家介绍Spark性能如何调优?相关面试题,主要包含被问及Spark性能如何调优?时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 避免创建重复的RDD,尽量复用同一RDD,尽量避免使用shuffle类算子,优化数据结构,使用Hive ETL预处理数据,过滤少数导致倾斜的key,提高shuffle操作的并行度,两阶段聚合,将reduce join转为map join。
-
Java方法调用性能
问题内容: 我有这段代码在做Range Minimum Query 。当t = 100000时,i和j始终在每条输入行中更改,因此在Java 8u60中其执行时间约为12秒。 当我提取一个新方法以找到最小值时,执行时间快了4倍(约2.5秒)。 我一直认为方法调用很慢。但是这个例子却相反。Java 6也演示了这一点,但是在两种情况下(17秒和10秒)执行时间都慢得多。有人可以对此提供一些见识吗? 问