《clickhouse》专题
-
在Windows上通过Powershell将数据加载到Clickhouse中时,为什么会出现换行错误?
问题内容: 我正在尝试将数据加载到Windowsdocker桌面内置的docker容器中的clickhouse中。我在R中准备了模拟数据,用csv编写,并在Clickhouse中创建了表(我省略了连接): 我试图加载的数据非常庞大,所以这只是一个示例,以显示 设置以及为什么我在第一行出现错误。我想像这样在 Powershell中使用Clickhouse客户端访问Docker容器来加载数据: 我还添
-
如何在ClickHouse中按时间段分组并用null / 0s填充丢失的数据
问题内容: 假设我有一个给定的时间范围。为了进行说明,让我们考虑一些简单的事情,例如2018年全年。我想从ClickHouse查询数据作为每个季度的总和,因此结果应为4行。 问题是我只有两个季度的数据,因此使用时,仅返回两行。 2018-01-011546210800 这将返回: 我需要: 这是简化的示例,但是在实际使用情况下,聚合将是例如。5分钟而不是四分之一,GROUP BY将至少具有一个以上
-
 使用不正确的输入数据格式将数据从csv文件导入ClickHouse数据库表
使用不正确的输入数据格式将数据从csv文件导入ClickHouse数据库表我已经完成了连接Clickhouse服务器/客户端和创建表的任务。然后,我想将数据从csv导入到该表中。问题是ClickHouse中的DateTime类型需要这样的格式:YYYY-MM-DD hh:mm:ss,但是我下载的数据集只有这个时间格式:2016-01-13 6:15:00am(YYYY-MM-DD h:MM:ss)小时在我的数据集中只有h,应该是hh。请告诉我如何将csv文件中的所有数据
-
如何通过Docker容器clickhouse客户端将CSV数据导入表
我正在使用适用于Windows的Docker: < li>Docker版本18.03.1-ce-win64 < li>Docker引擎18.03.1-ce < li>ClickHouse客户端版本1.1.54380 < li>ClickHouse服务器版本1.1.54380 为了将数据从表导出为CSV格式,我正在使用以下命令: > 现在运行容器进行导出 注意:上面的命令可以很好地工作。 现在运行<
-
在准备好的语句中将负Java长转换为clickhouse Uint64
在插入之前,有没有办法将负长转换为Uint64(clickhouse数据类型)。暂时的 引发以下异常 我明白为什么clickhouse会抱怨。你能给我提出解决这个问题的办法吗?是否可以将这个负长转换为其他类型的对象?提前谢谢你。
-
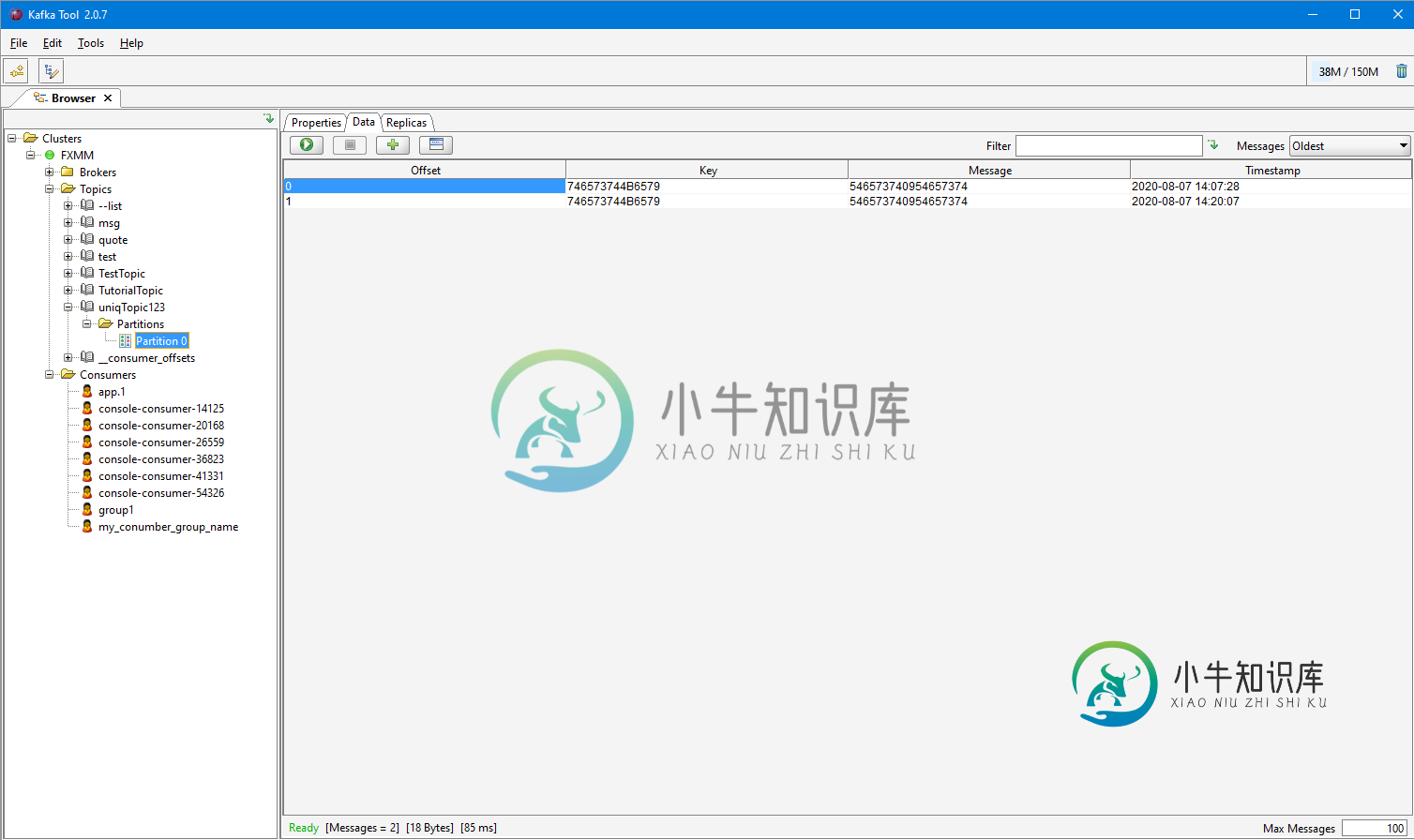 Clickhouse无法从Kafka获取格式为TabSeparated的消息
Clickhouse无法从Kafka获取格式为TabSeparated的消息我从Spring Boot应用程序向Kafka发送消息 application.properties 配置 在日志中,我可以看到如下消息: SUCCESS: SendResult[producerRecords=产品记录(主题=uniqTopic123,分区=null,标头=RecordHeaders(标头 = [], isReadOnly=true),key=testKey,value=Test
-
如何在没有抛出错误的情况下为Clickhouse配置Kafka?
我有两个Kafka集群,第一个--使用“SASL SCRAM-SHA-256”机制进行身份验证,另一个--没有为其设置配置。 为了能够连接到Clickhouse中的< code>Kafka-A,我配置了一个< code>config.xml文件,如下所示: 在这一点上,我发现我无法使用Kafka引擎表连接到Kafka-B。当我尝试发生打印以下消息的错误时: storage Kafka(XXX):[
-
Clickhouse 镜像使用帮助
Debian/Ubuntu 用户 新建 /etc/apt/sources.list.d/clickhouse.list,内容为 deb https://mirrors.tuna.tsinghua.edu.cn/clickhouse/deb/stable/ main/ RHEL/CentOS 用户 新建 /etc/yum.repos.d/clickhouse.repo,内容为 [repo.yand
-
ClickHouse与Hive的区别
主要内容:1.Hive的数据文件,2.Hive的存储系统,3.Hive计算引擎与ClickHouse计算引擎的差异,4.ClickHouse比Hive快的原因Hive是Hadoop生态系统中事实上的数据仓库标准。Hive是建立在Hadoop生态中的数据仓库中间件,其本身并不提供存储与计算能力。Hive的存储引擎使用HDFS,计算引擎使用MapReduce或Spark。 Hive本质上是一个元数据管理平台,通过对存储于HDFS上的数据文件附加元数据,赋予HDFS上的文件以数据库表的语义。并对外提供
-
 ClickHouse和StarRocks的介绍
ClickHouse和StarRocks的介绍主要内容:1.ClickHouse介绍,2.StarRocks介绍1.ClickHouse介绍 ClickHouse是面向联机分析处理(OLAP)的开源分析引擎。最初由俄罗斯第一搜索引擎Yandex开发,于2016年开源,开发语言为C++。由于其优良的查询性能,PB级的数据规模,简单的架构,在国内外公司被广泛采用。 它是列存数据库,具有完备的DBMS功能,备份列式存储和数据压缩。它的MPP架构易于扩展,易于维护。除此之外,它支持向量化的查询,完善的SQL以及实时
-
 ClickHouse-2-安装
ClickHouse-2-安装主要内容:1.1 打开相关端口或关闭防火墙,1.2 关闭SELinux,1.3 取消打开文件限制,1.4 安装依赖,1.5 启动客户端1.1 打开相关端口或关闭防火墙 1.2 关闭SELinux 1.3 取消打开文件限制 1.4 安装依赖 在软件安装位置创建目录: 将上面4个文件上传到创建的目录下 在创建的目录下执行安装命令: 运行完成后,查看安装情况: 接下来修改配置文件 将<listen_host>::</listen_host>的注释打开(该项配置表示可以在任意IP访问服务) 保存配置,接
-
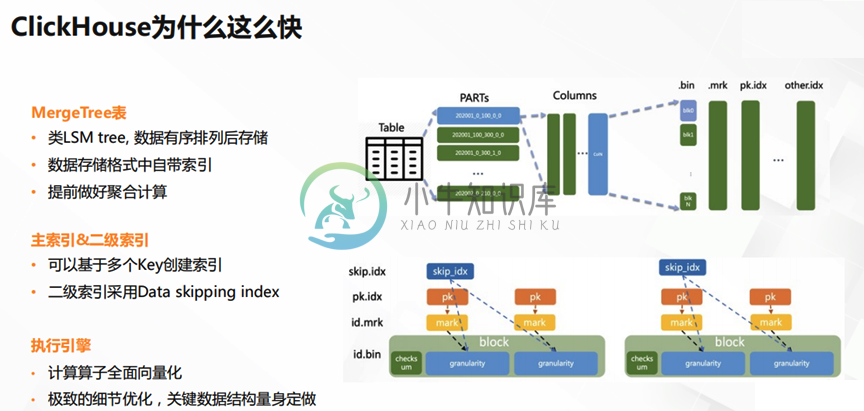
 ClickHouse-1-概述
ClickHouse-1-概述主要内容:1.ClickHouse是什么,2.ClickHouse的特点,3.ClickHouse的适用场景,4.ClickHouse为何那么快,5.EMR ClickHouse架构1.ClickHouse是什么 ClickHouse是俄罗斯Yandex开发的一款基于列式存储的开源查询数据库,基于语言开发的。ClickHouse在 2016 年开源,在计算引擎里算是一个后起之秀,在内存数据库领域号称是最快的。 另外需要注意的是,ClickHouse并不是基于Hadoop生态的,而是采用 Loca
-
ClickHouse
ClickHouse是俄罗斯第一大搜索引擎Yandex开发的列式储存数据库.令人惊喜的是,这个列式储存数据库的性能大幅超越了很多商业MPP数据库软件,比如Vertica,InfiniDB. 相比传统的数据库软件,ClickHouse要快100-1000X: 100Million 数据集: ClickHouse比Vertica约快5倍,比Hive快279倍,比My SQL快801倍 1Billion
-
clickhouse-go
ClickHouse Golang SQL database driver for Yandex ClickHouse Key features Uses native ClickHouse TCP client-server protocol Compatibility with database/sql Round Robin load-balancing Bulk write support
-
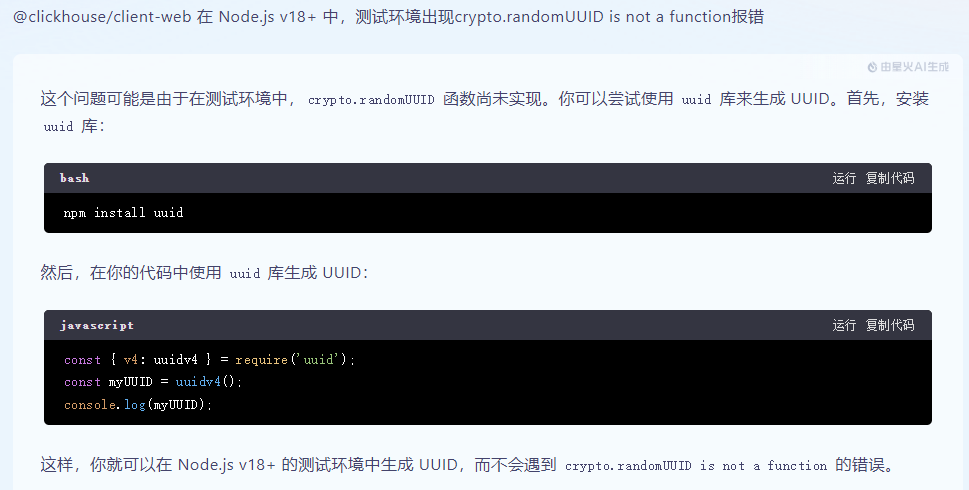 前端 - @clickhouse/client-web 在 Node.js v18+ 中出现的报错?
前端 - @clickhouse/client-web 在 Node.js v18+ 中出现的报错?使用@clickhouse/client-web本地是正常的, 到测试环境就报错crypto.randomUUID is not a function node版本18.多,依赖已安装上,搜索的方法也已经试过,没有效果,这是什么原因呢?