《stream》专题
-
带有Avro记录的Kafka Streams TopologyTestDriver的架构注册表问题
我正在尝试使用TopologyTestDriver测试kafka流。我分享代码片段和我面临的错误。 Error org.apache.kafka.common.errors.SerializationException: Error serializing Avro message Suppressed: java.lang.IllegalArgumentException: 請總是: 在每次測試
-
Camel:如何使用StreamList从SQL组件流式处理
我正在尝试使用Camels SQL组件,使用outputType=StreamList从数据库中传输数据。我从一个带有ConsumerTemplate的Java类中获取ResultIterator: 当尝试迭代ResultsetIterator时,我得到以下错误: 组织。h2。jdbc。JdbcSQLException:对象已关闭[90007-197] 经检查,我发现连接已关闭。连接={Hikar
-
匹配模式并使用Java8 stream将流写入文件
我试图读取一个巨大的文件,提取“引号”中的文本,将行放入一个集合,并使用Java8将集合的内容写入一个文件。 不,没有多个引用的文本。 我本可以使用简单循环。但是我想使用Java 8 Streams
-
如何忽略Kafka Streams应用程序中从同一主题读写不同事件类型的某些类型的消息
让我们假设Spring Cloud Stream应用程序从创建。它对事件感兴趣。一旦到达,它将对其进行处理并生成一个输出事件到相同的。 我面临的问题是,由于Kafka流应用程序从/向同一个主题读写,所以它试图处理自己的写操作,这是没有意义的。 如何防止此应用程序处理它生成的事件? 更新:正如Artem Bilan和sobychako指出的,我曾考虑过使用,但有些细节让我怀疑如何处理: OrderC
-
在apache spark streaming中使用foreachRDD内部的db连接
在spark streaming中,我希望在处理每个批处理之前查询db,将结果存储在一个可以序列化并通过网络发送给执行者的hashmap中。 在上面的代码中,indexMap应该在驱动程序中初始化,得到的map用于处理RDD。在foreachRDD闭包外部声明indexMap时没有问题,但在内部声明时会出现序列化错误。这是什么原因呢? 我之所以要这样做,是为了确保每个批处理都有数据库中的最新值。我
-
如何在Spark Streaming中使用CombineByKey仅在分区内进行'reduce'?
我已经通过Kafka将数据按键排序到我的Spark流分区中,即在一个节点上找到的键在任何其他节点上都找不到。 我希望使用redis及其(increment by)命令作为状态引擎,并且为了减少发送到redis的请求数,我希望通过在每个工作节点上进行字数计数来部分减少数据。(关键是标签+时间戳,从字数中获取我的功能)。我希望避免洗牌,让redis负责跨工作节点添加数据。 即使我检查了数据在工作节点之
-
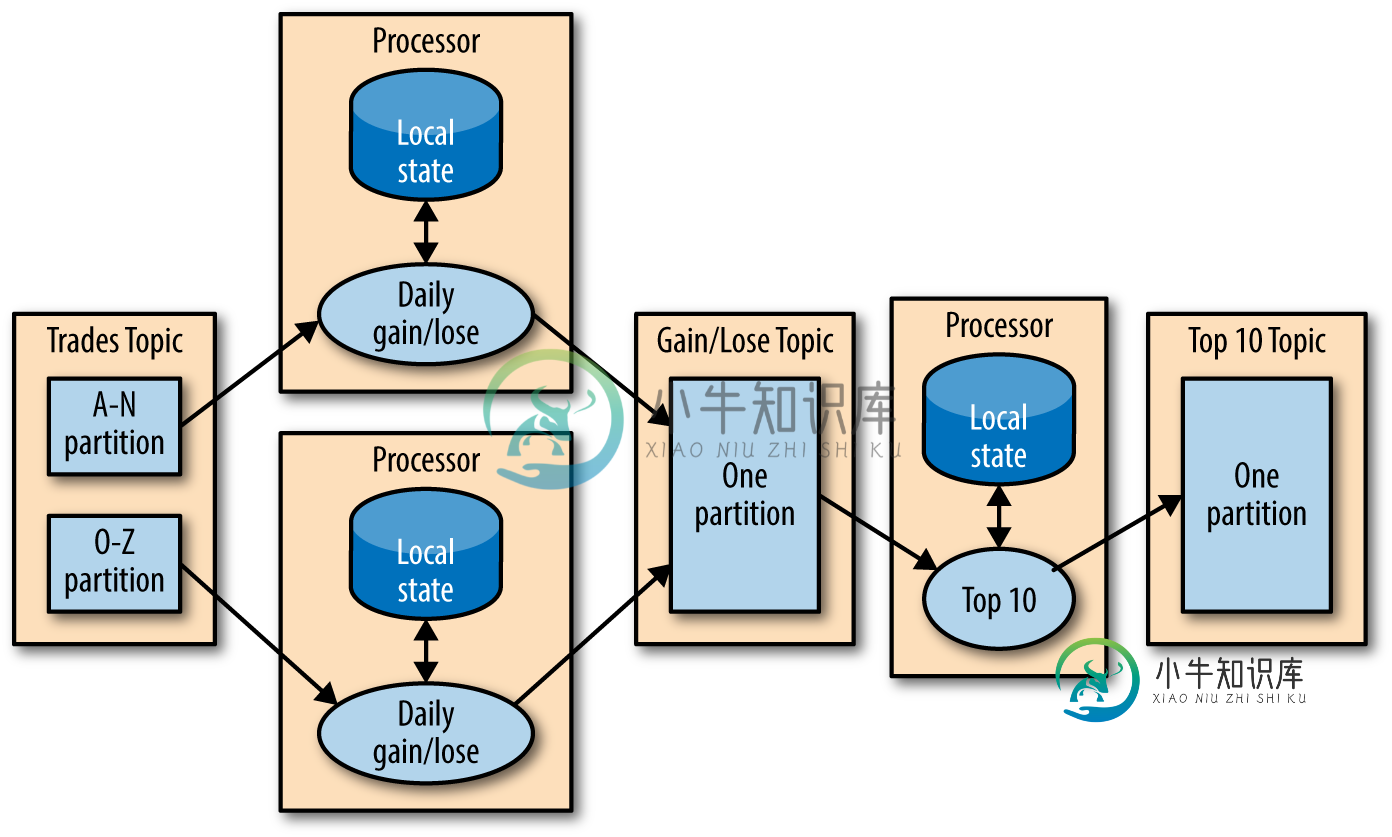 Apache Flink State Store vs Kafka Streams
Apache Flink State Store vs Kafka Streams据我所知,处理Kafka流会在内存、光盘或Kafka主题中本地显示其状态,因为所有的输入数据都来自一个分区,其中所有的消息都是由一个定义的值键控的。大多数时候,计算可以在不知道其他处理器状态的情况下完成。如果是,则有另一个Streams实例来计算结果。就像这张图: Flink的状态到底存储在哪里?Flink是否也可以在本地存储状态,还是总是将它们发布到所有实例(任务)?是否可以配置Flink,使其
-
Stream.peek更改状态的可能副作用,为什么不像这样使用它
我想到的另一个Stackoverflow问题的解决方案是使用Stream.peek操作,但似乎仍然不正确,因为它会改变< code>Stream.peek方法中的状态。 同时在<code>流上研究(这里和这里)。查看用法是否可以改变状态我仍然不完全相信<code>流。peek不应改变状态(包括<code>流 下面是Javadoc所说的: 此方法主要用于支持调试,您希望在元素流经管道中的某个点时看到
-
使用Spring Boot 2控制器StreamingResponseBody传输视频文件mp4
我试图用Spring Boot 2流式传输视频文件mp4,我遵循了一些教程,解决方案应该很简单... 我不明白为什么。。当我将url放入浏览器时,默认的视频播放器出现,加载。。。超时后,我在浏览器控制台中收到一个“net::ERR_CONTENT_LENGTH_MISMATCH 200”。。 如果我省略标题。添加(“内容长度”,Long.toString(file.Length());装载速度很快
-
Kafka streams 1.0:以高max.poll.interval.ms和session.timeout.ms处理超时
我使用的是一个使用Kafka Streams1.0和Kafka Broker1.0.1的无状态处理器 //将其设置为1/3会话。超时 //使其更大,因为我正在进行密集的计算操作,处理1条kafka消息(NLP操作)可能需要10分钟 尽管有这样的配置和我对kafka超时配置工作原理的理解,但我看到消费者每隔几秒钟就会重新平衡一次。 我已经阅读了下面的文章和其他stackoverflow问题。关于如何
-
spark streaming中的Kafka限制数据消耗
我正在做星火流媒体项目。从Kafka那里得到数据。我想限制Spark-Streaming消耗的记录。关于Kafka的资料非常多。我已经使用属性来限制Spark中的记录。但在5分钟的批处理中,我收到了13400条消息。我的星火程序每5分钟不能处理超过1000条消息。Kafka主题有三个分区。我的spark驱动程序内存是5GB,有3个执行器,每个3GB。如何限制Kafka在spark Streamin
-
可以跳过Stream.peek()进行优化
我在声纳中发现了一条规则,它说: 与其他中间流操作的一个关键区别是,为了优化目的,流实现可以跳过对< code>peek()的调用。这可能会导致< code>peek()仅针对流中的某些元素或不针对流中的任何元素被意外调用。 另外,Javadoc中提到了它,它说: 此方法主要用于支持调试,您希望在元素流经管道中的某个点时看到这些元素 这种情况下可以跳过吗?和调试有关吗?
-
Streams-parallel()跳过()不显示元素
我有一个关于以下两个代码的问题。 没有平行性: 输出为: 具有并行性: 输出为: 为什么并行流的输出不包括1?
-
Stream.Foreach中的多行代码
-
Java Streams Collectors.toList()with map()vs mapToInt()[duplicate]
我有这样一个目标: 我很难理解为什么会这样: