《stream》专题
-
Spark Streaming中的微批合并
那么我需要按照以下方式处理这些消息: 在每个消息上应用一个(couple of)函数,输出 应在消息上应用一个函数,其中 (稍后有一个传递,需要“转置”消息以跨所有a处理,但这不是这里的问题) 我如何实现这样的消息合并,从步骤1到步骤2? 它看起来像是子键上的groupby,但据我所知,方法groupby将在每个微批处理中应用。我需要的是,对于每个,等待接收到所有(假设一个简单的计数系统可以工作)
-
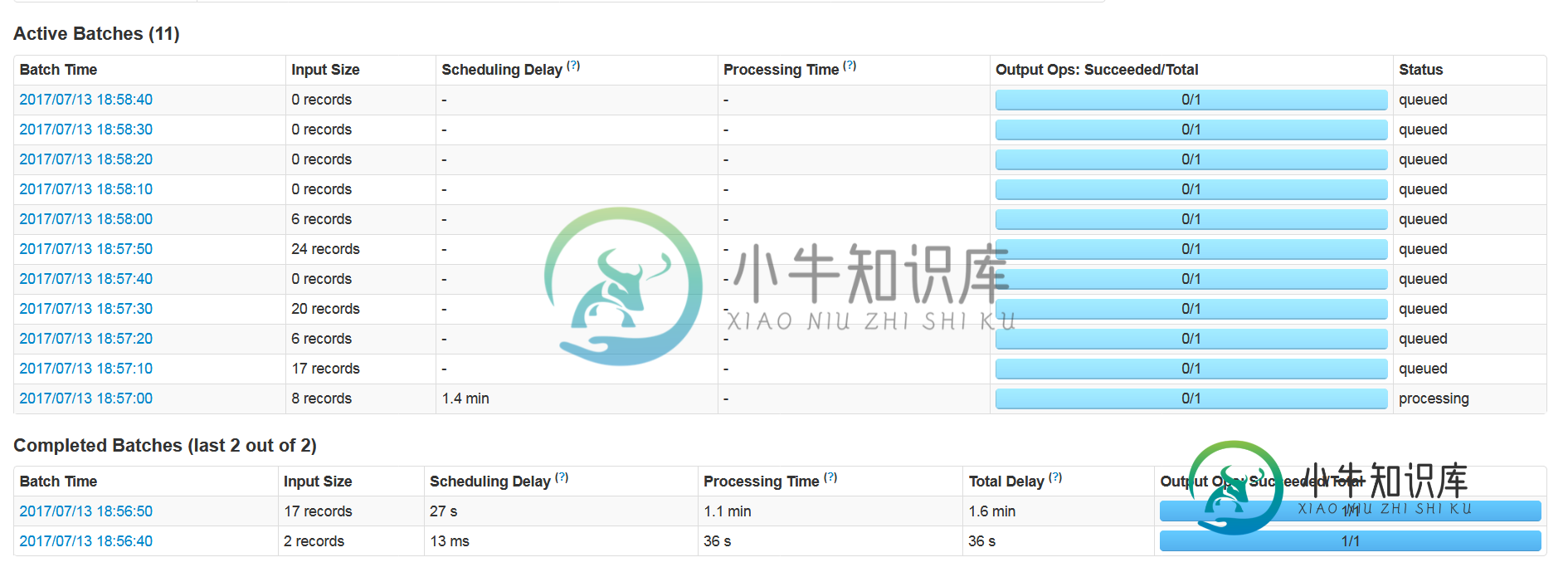 Spark Streaming:微批并行执行
Spark Streaming:微批并行执行我们正在接收来自Kafka的星火流数据。一旦在Spark Streaming中开始执行,它只执行一个批处理,其余的批处理开始在Kafka中排队。 我们的数据是独立的,可以并行处理。 我们尝试了多个配置,有多个执行器,核心,背压和其他配置,但到目前为止没有任何工作。排队的消息很多,每次只处理一个微批处理,其余的都留在队列中。 我们从差异实验中得到的统计数据: 实验1 100个文件处理时间48分钟 1
-
kafka Max.Poll.Records在spark streaming中不起作用
我的spark streaming版本是2.0,kafka版本是0.10.0.1,Spark-Streaming-Kafka-0-102.11。我使用直接的方式来获取Kafka记录,我现在想限制我在一个批处理中获取的消息的最大数量。所以我设置了max.poll.records值,但它不起作用。spark中的消费者数就是Kafka中的分区数?所以spark流中的最大记录数是max.poll.reco
-
如何在java中处理Apache spark Streaming中的Json数据
嗨,我是阿帕奇星火新用户。我正在学习的路上。我已经从kafka主题为json数据编写了spark streaming。下面是json数据的连续流。但现在我不知道如何使用这个json数据。我使用DataSet和DataFrame来处理Json数据,但遇到了一些错误。请用几个例子来帮助我,如何使用流式传输的数据流。 注意:我使用的是Apache Spark1.6.3版本。 代码:
-
Spark Streaming-离线模型是否可以用于数据流
在这个Link-Link中,提到了一个已经离线构建的机器学习模型,可以对着流数据进行测试。 “你还可以轻松地使用MLlib提供的机器学习算法。首先,有流式机器学习算法(例如流式线性回归、流式KMeans等),它们可以同时从流式数据中学习,也可以在流式数据上应用模型。除此之外,对于更大类的机器学习算法,你可以离线学习一个学习模型(即使用历史数据),然后在流式数据上在线应用模型。更多细节请参见MLli
-
Spark Streaming应用程序在连续批处理失败后应停止
我有一个带有Spark2.3.1的DStream流应用程序。 其中我正在从Kafka读取数据并写入Kerberized HDFS,但在写入HDFS时,我的批处理随机开始失败,异常显示与kerberos相关的错误,但我的spark应用程序仍在运行,因此除非检查日志,否则我不知道批处理正在失败。 我的问题是,有没有什么方法让我可以限制连续批处理故障转移的数量?建议是否存在某些属性,在这些属性中,我们可
-
使用stream laravel时,在获取新follows的通知提要时遇到问题
我正在使用Getstream Laravel包构建一个小项目。但是,我在尝试显示新关注者的通知时遇到问题。调用FeedManager::getNotificationFeed($请求)时,我得到一个空结果集- 然后,用于获取新通知的控制器操作如下所示: 在用户模型中,我定义了一个关系,一个用户有许多遵循。最后,FollowController中的follow和unfollow操作如下所示: 不确定
-
如何将数据从Kafka传递到Spark Streaming?
我正试图将数据从Kafka传递到火花流。 这就是我到现在所做的: null
-
Kafka Streams对未订阅主题的警告
在我的应用程序中(它正在使用Topic1、Topic2和Topic3),我还不断看到与其他主题相关的警告。 该消息通过以下Kafka代码打印:https://github.com/apache/kafka/blob/trunk/clients/src/main/java/org/apache/kafka/clients/networkclient.java 这是意料之中的吗?为什么这些警告消息会发
-
spark streaming应该使用多少个执行器
我必须编写spark streaming(createDirectStream API)代码。我将接收大约90K消息每秒,所以虽然使用100个分区为Kafka主题,以提高性能。 能不能请你告诉我,我该用多少个遗嘱执行人?我可以使用50个执行器和每个执行器2个核心吗? 另外,考虑如果批处理间隔为10秒,并且kafka主题的分区数为100,我会从每个kafka分区接收100个RDD,即1个RDD吗?在
-
为什么我的Kafka Streams应用程序的消费者组(app-id)的偏移量在应用程序重启后会被重置?
我有一个Kafka Streams应用程序,每当我重新启动它时,它所消耗的主题的偏移量就会被重置。因此,对于所有分区,延迟增加,应用程序需要重新处理所有数据。 更新:输出主题接收到一系列事件,这些事件在应用程序重新启动后已经被处理,而不是像我在上一段中所说的那样,输入主题的偏移量被重置。但是,内部主题(KTABLE-SUPPRESS-STATE-STORE)偏移量正在重置,请参见下面的注释。 在重
-
为什么我可以对没有stream()方法的类的对象调用stream()方法?
我是大学里的一个新手Java程序员。今天我发现了一些东西,打破了我关于Java语法如何工作的一个概念。 在ArrayList类中找不到方法stream(),但它可能看起来好像在那里。当我将鼠标移到Eclipse中的-方法上时,它表示这是集合的一部分,但我在其在线文档中的任何地方都找不到方法。 如果方法不是我调用它的类的一部分,为什么它可以调用它?
-
java 8中. stream()的默认实现是什么?
它只是说: 返回以此集合为源的顺序流。 当spliterator()方法无法返回不可变、并发或后期绑定的spliterator时,应重写此方法。(有关详细信息,请参见拆分器() 但我找不到任何显示它如何创建和返回新流的代码。 是一个
-
使用x86/x64 Streaming SIMD扩展进行块匹配优化
这将是我发布的第一个问题! 我正在尝试使用Intel的SSE4优化立体视觉应用程序的“块匹配”实现。2和/或AVX内部函数。我用“绝对差之和”来寻找最佳匹配块。在我的情况下,blockSize将是一个奇数,例如3或5。这是我的C代码片段: 我知道,数据流单指令多数据扩展指令集包含许多指令,以便于使用SAD进行块匹配,例如mm\u mpsadbw\u epu8和mm\u SAD\u epu8,但它们
-
使用spark streaming从http创建分析
嗨,我的要求是从创建分析,即从中提取数据,并将该数据放入HDFS位置中,然后从HDFS中使用Tableau或HUE UI创建分析报告。我在CDH5.5的spark-shell的scala控制台尝试了以下代码,但无法从http链接获取数据 我在scala控制台遇到以下错误: java.io.ioException:方案没有文件系统:http在org.apache.hadoop.fs.FileSyst