《内推投递》专题
-
在一次投票中增加Kafka消费者阅读的消息数量
Kafka consumer有一个配置< code>max.poll.records,它控制对poll()的单次调用中返回的最大记录数,其默认值为500。我将它设置为一个很高的数字,这样我就可以在一次轮询中获得所有的消息。然而,即使这个主题有更多的信息,在一次呼叫中,民意调查只返回几千条信息(大约6000条)。< br> 如何进一步增加单个消费者阅读的邮件数量?
-
如何在Spring数据Jpa中使用投影返回自定义对象?
我试图从spring数据jpa-native查询返回自定义对象 以下是我到目前为止根据这个如何从Spring Data JPA GROUP BY查询返回自定义对象所做的工作 我应该能够创建如下查询: 我声明投影接口 那就叫它吧 不过我有个例外 javax。坚持不懈PersistenceException:org。冬眠MappingException:未知实体:javax。坚持不懈元组 知道我做错了
-
具有可比接口和通用列表的未检定投放警告
当我使用带有通用或参数化列表的可比接口时,我会收到一个未选中的强制转换警告。我可以使用ObjectList进行比较,但不能使用通用列表。这是我的开发,首先使用ObjectList,然后使用通用列表。 下面是我的ListNode类定义的一个片段: 和我的ObjectList类定义的片段: 我的可比界面: 我的ObjectList类中有一个方法,可以将对象参数与ListNode中的对象进行比较,没有问
-
前端 - 使用shapefile-js读取zip包出现投影坐标系问题?
无法解析shapefile zip code: error: PROJCS["CGCS2000_3_Degree_GK_CM_123E",GEOGCS["GCS_China_Geodetic_Coordinate_System_2000",DATUM["D_China_2000",SPHEROID["CGCS2000",6378137.0,298.257222101]],PRIMEM["Green
-
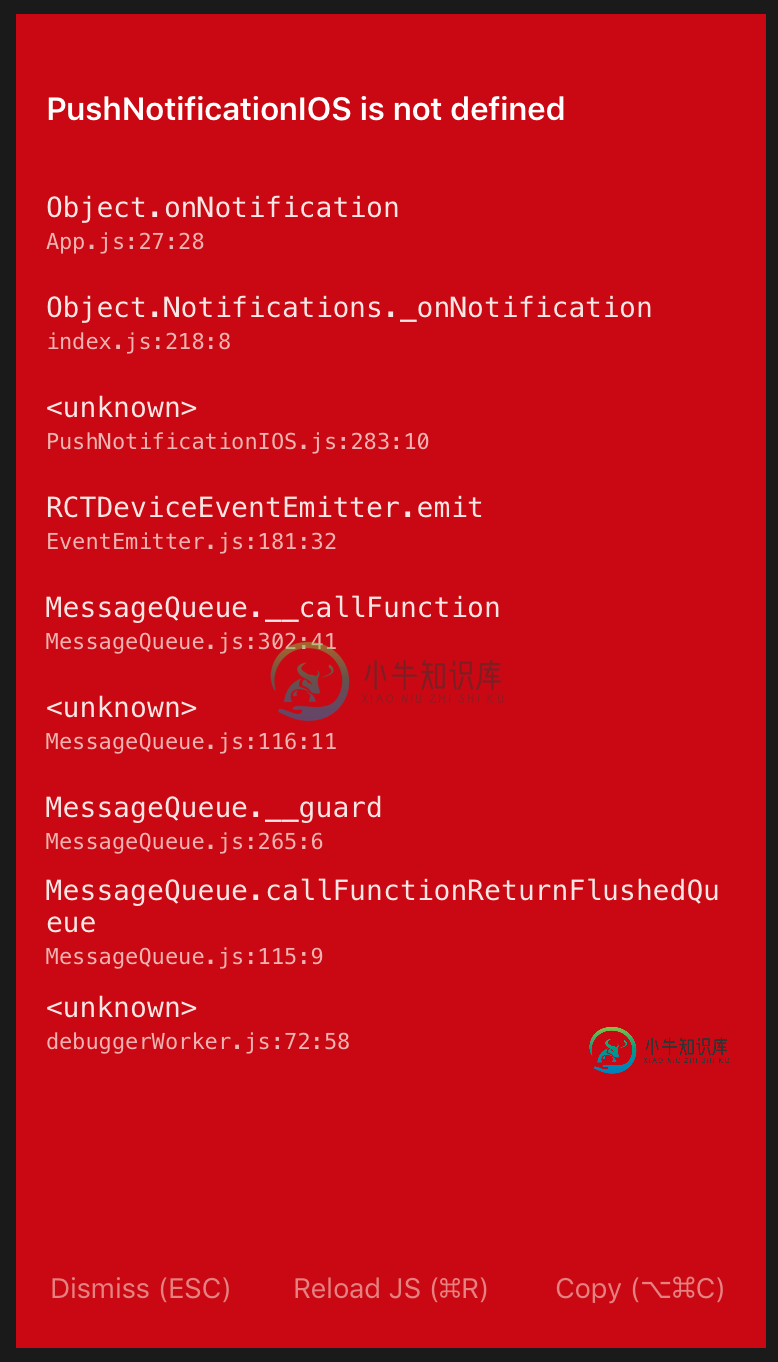 如何使用react native将数据传递到推送通知
如何使用react native将数据传递到推送通知即时消息使用本机推送通知https://github.com/zo0r/react-native-push-notification 如何将推送消息(聊天)传递到通知中? 我应该做哪一部分? ps:我不明白这是怎么回事-
-
Firebase云消息传递Android项目不发送推送通知
我正在尝试开发一个应用程序,其中服务器必须每5秒向运行该应用程序的所有android设备发送通知。我决定使用(谷歌)Firebse云消息发送通知,所以我首先尝试了指南的示例项目 https://firebase.google.com/docs/notifications/android/console-audience 但我不能让它工作。我遵守了所有的指示。我已经发布了我使用的代码。我也做了档案-
-
编码为模块递归的多态递归类型推断
标准 ML 没有多态递归。在模块语言中添加递归允许我们使用内函子的固定点将多态递归恢复为一种特殊情况。例如: 众所周知,多态递归使得类型推理不可判定。然而,函子定义已经包含部分类型信息,即其参数的签名。这些信息足以使类型推理再次可判定吗?
-
推土机将类字段嵌套到平面地图。使用推土机API进行类映射
我想让推土机地图成为我的职业: 到生成的,如下所示: . 也就是说,我正在尝试将嵌套类的字段映射到平面键目标。我使用的是JavaAPI的Dozer,而不是xml。我无法找到适当的构建器配置来管理它。基本代码类似于:
-
问题:SVM使用对偶计算的目的是什么,如何推出来的,手写推导;
本文向大家介绍问题:SVM使用对偶计算的目的是什么,如何推出来的,手写推导;相关面试题,主要包含被问及问题:SVM使用对偶计算的目的是什么,如何推出来的,手写推导;时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 目的有两个:一是方便核函数的引入;二是原问题的求解复杂度与特征的维数相关,而转成对偶问题后只与问题的变量个数有关。由于SVM的变量个数为支持向量的个数,相较于特征位数较少,因此转对
-
类型推断失败:没有足够的信息来推断Kotlin Paypal支付中的参数T
当用户确认付款时,我尝试在Paypal Sdk上获取交易详细信息。但是,下面的代码遇到了问题 遇到的问题: 类型推断失败:信息不足,无法推断中的参数T 享乐 对于此行:val confirm=data。getParcelableExtra(PaymentActivity.EXTRA_结果_确认) 不确定这对字符串(4)意味着什么: val paymentDetails=confirm。toJSON
-
内容控件绑定丢失内容控件内文本的格式
当我试图将XML与包含带有格式的文本的内容控件的docx绑定时,文本格式(字体类型、字体大小、颜色等)就会丢失。 我正在使用最新的docx4j-3.0.0.jar 有关示例和详细说明,请参见http://www.docx4java.org/forums/data-binding-java-f16/binding-loses-formatting-on-text-inside-content-con
-
如何使用GDB修改内存内容?
问题内容: 我知道我们可以使用几个命令来访问和读取内存:例如,print,p,x … 但是,如何在任何特定位置更改内存的内容(在GDB中调试时)? 问题答案: 最简单的方法是设置程序变量(请参见GDB:Assignment): 或者,您也可以按地址更新任意(可写)位置: 还有更多。阅读手册。
-
显示内联*内容*的属性差异
问题内容: 我注意到人们在1:1的比较中涵盖了某些显示属性的细节,但是在说明差异时还没有涉及很多。可能有人解释各种inline-之间的差异 的东西 显示标签? 对w3schools之类的地方进行更详细的定义会产生奇迹。 问题答案: 对于任何具有块和内联变体的显示类型,唯一的区别是,该显示类型具有以内联方式放置的框(即,[以内联格式设置的上下文),而另一种具有格式化为块级框的框,这取决于大多数情况。
-
java 中堆内存和栈内存理解
本文向大家介绍java 中堆内存和栈内存理解,包括了java 中堆内存和栈内存理解的使用技巧和注意事项,需要的朋友参考一下 Java把内存分成两种,一种叫做栈内存,一种叫做堆内存 在函数中定义的一些基本类型的变量和对象的引用变量都是在函数的栈内存中分配。当在一段代码块中定义一个变量时,java就在栈中为这个变量分配内存空间,当超过变量的作用域后,java会自动释放掉为该变量分配的内存空间,该内存
-
 内存紧缩(内存碎片化处理)
内存紧缩(内存碎片化处理)主要内容:分配内存空间,回收算法,总结前边介绍的有关动态内存管理的方法,无论是边界标识法还是伙伴系统,但是以将空闲的存储空间链接成一个 链表,即可利用空间表,对存储空间进行分配和回收。 本节介绍另外一种动态内存管理的方法,使用这种方式在整个内存管理过程中,不管哪个时间段,所有未被占用的空间都是地址连续的存储区。 这些地址连续的未被占用的存储区在编译程序中称为堆。 图 1 存储区状态 假设存储区的初始状态如图 1 所示,若采用本节介绍的