《长鑫存储面试》专题
-
14.5. 将存储引擎指定给表
可以在创建新表时指定存储引擎,或通过使用ALTER TABLE语句指定存储引擎。 要想在创建表时指定存储引擎,可使用ENGINE参数: CREATE TABLE engineTest( id INT ) ENGINE = MyISAM; 要想更改已有表的存储引擎,可使用ALTER TABLE语句: ALTER TABLE engineTest ENGINE = ARCHIVE;
-
16.3. 创建存储引擎源文件
实施新存储引擎的最简单方法是,通过拷贝和更改EXAMPLE存储引擎开始。在MySQL 5.1源码树的sql/examples/目录下可找到文件ha_example.cc和ha_example.h。关于如何获得5.1源码树的说明,请参见2.8.3节,“从开发源码树安装”。 复制文件时,将名称从ha_example.cc和ha_example.h更改为与存储引擎相适应的名称,如ha_foo.cc和ha
-
第20章:存储程序和函数
目录 20.1. 存储程序和授权表 20.2. 存储程序的语法 20.2.1. CREATE PROCEDURE和CREATE FUNCTION 20.2.2. ALTER PROCEDURE和ALTER FUNCTION 20.2.3. DROP PROCEDURE和和DROP FUNCTION 20.2.4. SHOW CREATE PROCEDURE和SHOW CREATE FUNCTION
-
第 9 章 : 导入、导出和存储
您无需在 Adobe Illustrator 中从头开始创建图稿,而是可以从使用其他应用程序创建的文件中导入矢量绘图和位图图像。 Illustrator 可以识别所有通用的图形文件格式。Adobe 产品之间的紧密集成和对多种文件格式的支持,使您能够通过导入、导出或复制和粘贴操作轻松地将图稿从一个应用程序移动到另一个应用程序。
-
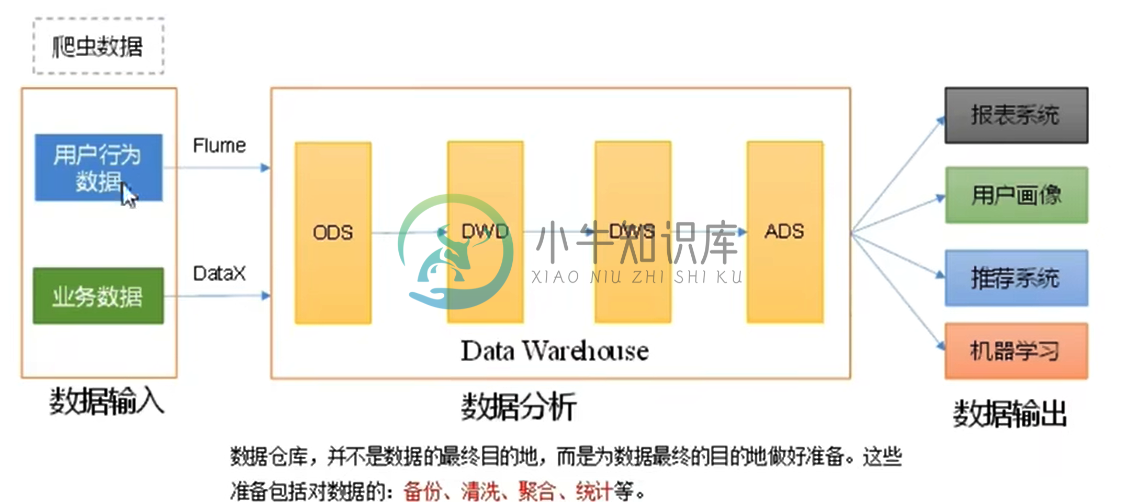 大数据平台之数据存储
大数据平台之数据存储主要内容:1.大数据生态技术,2.数据存储,3.数据存储的发展,4.数据存储的方式1.大数据生态技术 数据存储处理: 清洗, 关联, 规范化, 组织建模, 通过数据质量的检测, 数据分析然后提供相应的数据服务 离线数仓: 实时数仓: 以Kafka, cancal/Maxwell/FlinkCdc为区分, 离线数仓为Hive, Sqoop 实时数仓:分层: Ods, Dwd, Dim, Dwm, Dws, Ads 离线数仓分层: Ods. Dwd, Dws, Dwt, Ads 实
-
GIS云存储,数据安全上云
如果您需要在线使用空间数据,您可以使用SuperMap GIS云存储服务,几分钟就可以把您的数据安全上云。 具体来说,您只需在Web页面或SuperMap iDesktop中登录SuperMap Online账户,即可将GIS数据——工作空间/UDB/Shapefile/Excel/CSV/GEOJson等空间数据,上传、存储在云平台中。 将GIS数据在线存储后,您就可以通过Web/PC/移动端A
-
G1GC会导致内存逐渐增长,而全GC会降低内存
我正在centos 6上运行java应用程序,使用G1GC运行openjdk版本“1.8.0_232”。我看到堆的总使用量逐渐增加,导致应用程序崩溃。当我对活动对象进行堆转储时,转储大小仅为1.6GB,但我使用的总堆容量为32GB。 用于获取dump:jmap-dump:live、format=b、file=/tmp/dump的命令。hprof 从某个地方读到,jmap dump命令会触发一个完整
-
存储8M sha256哈希的最节省内存的方法
我一直在使用来存储键值对,其中键和值都是sha256哈希摘要。我需要能够找出列表中是否存在一个键,并且能够检索该dict的值。 目前,根据我的一些测试,我估计需要大约10Gb的内存来存储8000000个哈希,因为实际存储的数据只有512MB(每个哈希32字节,所以每个记录64字节) 有人有什么建议吗? 更新,基于我认为应该更新的一些评论。我将散列存储为字节,而不是十六进制字符串。我使用sqlite
-
将位图保存到Android存储而不丢失质量
现在我有一个打开手机摄像头应用程序的意图,允许用户拍照,然后带着新图像回到我的应用程序。有了这个,它返回一个位图。为了获得图片的Uri,以便我可以将ImageView设置为它,我相信我必须先将其保存到存储。唯一的问题是当我的应用程序打开它时,图像质量非常差。在我必须压缩的部分,我保持了100的质量,所以我不确定我做错了什么。 以下是我如何启动照相机的意图: 以下是我如何处理它: 对于switchT
-
Git克隆/拉取在“将密钥存储在缓存中?”
我试图克隆一个回购从我的BitBucket帐户到我的Windows 10笔记本电脑(运行GitBash)。我已经完成了连接所需的所有步骤(设置我的SSH密钥,通过成功的SSHinggit@bitbucket.org验证,等等)。然而,每当我试图克隆一个回购,提示不断挂断后,确认我要缓存Bit桶的密钥。 没有克隆任何文件,结果是一个空的repo。尝试从此repo启动git pull源主机时,也会要求
-
Spring(引导)-Redis缓存-它需要创建存储库吗?
我想问一个关于spring缓存注释和存储库创建的问题。 我正在尝试使用Spring Boot在redis中缓存我的值。(我有一个值,如果它不在缓存里,我需要缓存它,如果它在缓存里,我需要从那里获取它) null 我的问题是:如果我使用了上面的注释(@Cacheable、@CachePut和@CacheEvict),我是否应该通过扩展CrudRepository来为我感兴趣存储的类对象创建一个存储库
-
Spring批处理Jpa存储库保存不提交数据
我正在使用Spring Batch和JPA处理一个批处理作业并执行更新。我正在使用默认的存储库实现。 并且我正在使用一个repository.save将修改后的对象保存在处理器中。而且,我没有在处理器或编写器中指定任何@Transactional注释。 下面是我的步骤,读取器和写入器配置:另外,我的config类是用EnableBatchProcessing注释的 在writer中,这就是我使用的
-
指针的地址将存储在内存中的哪里?
我正在学习虚拟内存和自由空间管理。 我知道我们使用malloc分配的指针将请求堆中的一块内存。但是当我们调用malloc()系统调用时,它将返回一个整数作为专用内存块的地址,但是这个地址本身将存储在哪里呢? 假设 返回我的4008地址。它从4008到4022开始。这个块在堆中。但是4008本身在哪里? 它存储在堆栈中吗?
-
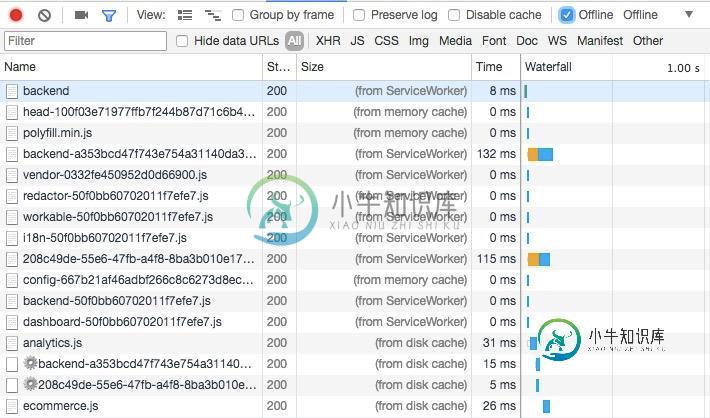 将workbox与CDN一起使用时,缓存存储为空
将workbox与CDN一起使用时,缓存存储为空我正在使用工作箱来缓存我的应用程序外壳。网络选项卡显示请求来自serviceWorker,并且资产在快速检索时肯定会被缓存,即使在离线模式下也是如此: 但是,缓存存储选项卡始终为空: 我试图通过控制台请求相同的资产: 瞧,资产显示: 我担心我错过了一些基本的东西。 顺便说一下,缓存存储在我的本地环境中显示正确,因此我怀疑这是来自CDN的资产的问题。
-
ARM组件中的内存是二进制存储的吗?
假设我执行了MOV R1,#9这样的指令。这会将二进制数字9存储在ARM组件的内存中吗?ARM汇编代码会看到存储在内存中R1位置的数字00001001吗?如果不是什么,它将如何存储十进制数字9的二进制?