《长鑫存储面试》专题
-
如何加载和存储nvarchar
堆栈:使用Ambari 2.1安装HDP-2.3.2.0-2950我正在执行以下步骤: 使用SQOOP将SQL server表加载到HDFS 在配置单元中创建外部表 在Sqoop导入中找不到相关的charset/nvarchar等选项 在配置单元中,是否可以盲目使用varchar/string代替nvarchar
-
Laravel-使用存储库模式
我正在尝试学习存储库模式,似乎有点困惑,当我急于加载关系并将db逻辑排除在控制器之外时,如何使用此存储库模式。 快速概述我的存储库/应用程序结构。 示例ProductInterface。php 示例类别接口。php 好的,最简单的部分是使用DI向控制器注入模型依赖关系。 列出与相关产品的所有类别更加困难,因为我不再使用雄辩的模型。我正在使用一个界面,它没有暴露所有雄辩的方法。 如果我没有在我的El
-
Hibernate存储类内的字段
我有两个类,有两个单独的表,“员工”和“公司”。我想在Company类中保留一个员工列表。这很容易,但我不知道如何在数据库端表示此列表。 “公司”类别: 类“员工”: 如果没有hibernate,我会选择创建另一个包含两列“employeeId”和“companyId”的表的设计,并尝试让所有员工的“employeeId”与“companyId”匹配。我不知道是否有可能在冬眠时做同样的事情。如果是
-
如何编辑存储过程?
我的数据库中有几个存储过程,结构如下: 我被要求在每个有它的过程中用另一个子句替换中的表。 我经过了很多研究,但我应该创建一个自己工作的脚本,我还没有找到合适的东西。例如,我找到了显示存储过程源代码的,但是有没有办法将其放入变量中以便编辑它?
-
为Maven使用Nexus存储库
我正在尝试将我的maven配置为使用Nexus存储库。我试图实现的应该是非常常见的:我希望有一个Nexus存储库作为中心依赖项的代理,还有两个用于快照和发布的存储库。那里有很多文档,但我无法让它运行。我编辑了my settings.xml,使其如下所示: 但我总是收到以下错误消息: 有人能帮帮我吗?我错过了什么?
-
Firebase存储通配符规则
我目前正在使用NodeJS、HTML和Firebase编写一个web站点,用于数据库服务、身份验证和存储。我目前遇到的问题是Firebase存储规则不能按照我对文档的解释工作。 我的Firebase存储实例的目录结构如下所示(明显有假的UID):
-
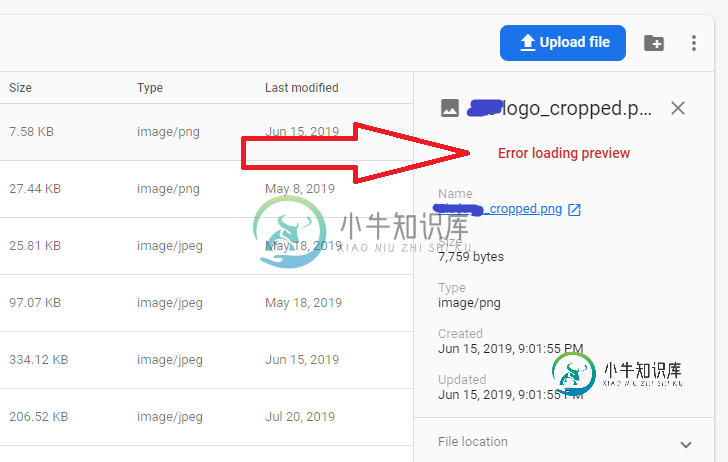 Firebase存储映像未显示
Firebase存储映像未显示Firebase存储图像三分之二天未显示。我有一些发布的应用程序,在这些应用程序里面有一些图片显示从Firebase存储,现在突然它不显示/查看。我还从浏览器>Firebase Console>Storage检查了那些图像,但它没有显示图像预览,并且显示:“错误加载预览”。但我的Firebase Firestore数据显示没有任何错误。我查了储存配额,没有问题。我的火力点计划是“燃烧”,随走随付。
-
装饰Spring启动存储库
我正在开发一个Spring BootAPI,该API应该在本月晚些时候部署。我们为存储库创建了自己的界面,并扩展了CrudRepository。Spring开机自动连线一切。 我想做的是添加更多日志记录功能,例如。 目前,我们的代码如下所示: 由于Spring配置了所有功能,所以并没有真正看到装饰这些功能以添加日志功能的方法。有人能帮我指出留档,展示一个很好的例子,或者解释日志装饰器背后的概念吗?
-
ExtJS:创建动态存储\grid
你好,伙计们,我在一个动态存储中学习,我从数组中获得一个数据,并创建一个存储,但如果我试图将列和数据加载到我的网格中,我会得到"未捕获的类型错误:无法读取未定义的属性'getProxy'" 控制器: window.js: });
-
Firebase存储图像被旋转
在我的应用中,我提示用户捕获图像。用户相机活动在按钮单击时开始,用户可以选择使用相机捕获图像。 此图像保存在用户手机上。然后将图像上传到firebase Storage,一切正常。来自一位使用三星Note 8的用户的反馈是,当图像以肖像模式拍摄时,他稍后会在应用程序中以风景模式显示。 我查看了firebase存储,发现图像以横向模式保存在存储中,即使用户以纵向模式捕获图像。 我想我必须将元数据传递
-
位图解码的存储器
我有一些关于位图解码的问题。 > 当我尝试使用BitMapFactory.DecodeByteArray从Byte[]数组解码位图时,结果位图中的param Byte[]和mBuffer Byte[]有什么不同。当函数返回时,位图仍然保留对Byte[]参数的引用吗? 当我使用以下代码从sdcard的jpg文件解码位图时: 该jpg文件分辨率为10800*5400,大小为13.82M,结果位图不为空
-
如何申请存储权限?
我正在尝试调用我的类来检查存储权限 但问题是,它不让我在一个类中实现它,我得到了以下错误- "类型权限的方法onRequest estPermissionsResult(int, String[], int[])必须覆盖或实现超类型方法" 类型权限的方法requestPermissions(字符串[],int)未定义 这是我的密码- }
-
Maven查找特定存储库
我目前集成了maven、jenkins、Nexus和git,我正在学习这些工具。 我的要求是告诉maven只从pom中提到的存储库下载依赖项。xml,而不是来自我的Nexus存储库,但它的作用恰恰相反。 我已经在my settings.xml的repository下声明了我的Nexus版本和快照存储库。我如何告诉maven从特定的存储库而不是Nexus repo下载依赖项。 下面是我的pom。xm
-
存储库ID中的GraphDB点?
我注意到,与RDF4J相比,GraphDB不允许在存储库ID中使用点。我们有包含一些分类法的版本化存储库。版本号用于存储库ID,例如:。 虽然这在RDF4J中运行良好,但我必须在GraphDB中以不同的方式调用这样的存储库,例如。我希望能够在RDF4J和GraphDB上使用相同的查询集和联邦(调用引用分类库),以便根据用例在两者之间切换。在RDF4J中,我可以通过让一个无版本ID的联邦存储指向特定
-
没有HDFS存储的Hadoop Namenode
我已经安装了一个总共有3台机器的hadoop集群,其中2个节点充当Datanode,1个节点充当Namenode,还有一个Datanode。我想澄清一些关于hadoop集群安装和体系结构的疑问。下面是我正在寻找答案的问题列表--- 我在集群中上传了一个大约500MB大小的数据文件,然后检查hdfs报告。我注意到我制作的namenode在hdfs中也占用了500MB大小,还有复制因子为2的datan