《规控》专题
-
消息驱动bean是否需要激活规范?
[警告]:由于激活规范不可用,因此无法激活消息驱动bean的消息endpoint。在激活规范可用之前,消息endpoint将不会接收消息。 MDB必须有激活规范吗?我希望它只是被激活,而不需要添加进一步的配置到服务器。
-
口水-如何找出所有规则都匹配?
我有一个。DRL文件,其中包含10条规则。一旦我插入一个事实,一些规则可能会匹配-我如何找出哪些规则是以编程方式匹配的?
-
EC2运行状况检查的CloudWatch事件规则
我正在寻找一个CloudWatch事件规则/事件模式,以便在任何可用服务器的运行状况检查1/2通过时得到通知。当我探索时,得到了CloudWatch警报选项,但如果我有10个实例,那么我需要配置10个警报。我的目标是使用EC2事件或CloudTrail事件构建一个单独的cloudwatch规则,该规则将检测区域中所有服务器的EC2运行状况检查。
-
一种硬币交换变量的动态规划
我对解决硬币交换问题的一种变体感兴趣。回想一下硬币交换问题的正式定义: 给定一个值N,如果我们想改变N分,并且我们有无穷多的S={S1,S2,…,Sm}整值硬币,我们有多少种方法可以改变?硬币的顺序无关紧要。例如,对于N=4和S={1,2,3},有四种解决方案:{1,1,1},{1,1,2},{2,2},{1,3}。所以输出应该是4。对于N=10和S={2,5,3,6},有五个解:{2,2,2,2
-
如何在JPA中使用规范连接多列?
我正在尝试将查询转换为JPA规范,该查询包含带OR条件的连接操作。 以下是查询: 我试图编写一个规范,但在如何将多个列与OR条件连接方面遇到了障碍。 用户实体: 运营实体 我希望有一个规范来取代上面的查询
-
ANTLR4 Lexer错误报告(违规字符的长度)
我正在为使用ANTLR4的某种语言开发一个小型IDE,当lexer无法匹配错误字符时,我需要在错误字符下划线。在这种情况下,内置的实现向stderr输出一条消息,类似于如下所示: 我完全可以理解如何获得关于错误的行和列的信息(作为参数传递给回调),但如何在回调中获得字符串? 当解析器是错误的来源时,它会将违规令牌作为回调的第二个参数传递,因此提取关于错误输入的开始和停止偏移量的信息变得很简单,参考
-
带Hibernate的Optaplanner-一些DRL规则不起作用
我正在使用Optaplanner申请员工排班。没有毅力,一切都很好。现在,我想添加Hibernate集成。我想从MySQL数据库中获取信息,并将其用作时间表输入。 在数据库中,我有位置和技能表。 员工数据、时隙和工作分配现在已在应用程序中硬编码。 我的域类,技能: 和职位: 不起作用的规则: 我认为数据库还可以,因为其中的数据以前是用这个应用程序创建的。此外,我还有另一个DRL规则正在运行。我没有
-
如何在Eclipse中抑制特定的Checkstyle规则?
我试图使用抑制过滤器,但发生意外错误。 以下是一条错误消息。 无法初始化模块SuppressionFilter-无法将模块SuppressionFilter中的属性“file”设置为“checkstyle suppressions.xml”:无法找到checkstyle-suppressions.xml-文档根元素“suppressions”,必须与DOCTYPE root“module”匹配 你
-
造成内容安全策略(CSP)违规错误
我试图在测试站点上使用新的内容安全策略(CSP)HTTP头。当我将CSP与Modernizer结合使用时,会出现CSP冲突错误。这是我正在使用的CSP策略: 内容安全策略:默认src“self”;脚本src'self'ajax.googleapis.com ajax.aspnetcdn.com;样式src‘self’;img src“自我”;字体src“self”;报表uri/WebResourc
-
pyomo中非线性随机规划的求解器?
我正在用pyomo编程求解非线性优化问题(使用ipopt求解器)。稍后,我想在模型中添加随机元素。我知道在Pyomo中,可以使用复数形式来处理随机规划,但复数形式只能处理线性规划、混合整数规划和二次规划。 一般非线性随机规划问题有求解器吗?如果没有,我们如何使用现有的求解器来处理它?
-
买卖股票的最佳时机动态规划
尝试解决这个问题:假设您有一个数组,其中第i个元素是给定股票在第i天的价格。 设计一个算法来寻找最大利润。您最多可以完成两笔交易。 解决方案:我正在做的是分而治之的方法。 dp[i][j]是ith和jth day之间的最大利润。计算如下: dp[i][j]=max(dp[i][j],max(prices[i]-prices[j],dp[k][j],dp[i][k1]),其中k小于i且大于j。 现在
-
最长公共递增子序列动态规划
我正在寻找最长的常见递增子序列问题的解决方案。如果你不熟悉,这里有一个链接。LCIS 这个问题基本上可以归结为两个不同的问题。“最长公共子序列”和“最长递增子序列”。这是最长公共子序列的递归解决方案: 基于此和这里找到的一般递归公式,我一直在尝试实现该算法,以便可以使用动态规划。 显然,这并没有给出正确的解决方案。任何帮助都将不胜感激。 例如,如果我给它两个序列{1,2,4,5}和{12, 1,
-
EsLint说找不到规则“jsdoc/require jsdoc”的定义?
我安装了,并在我的eslint配置文件中这样设置: 我一直收到这样的错误消息:
-
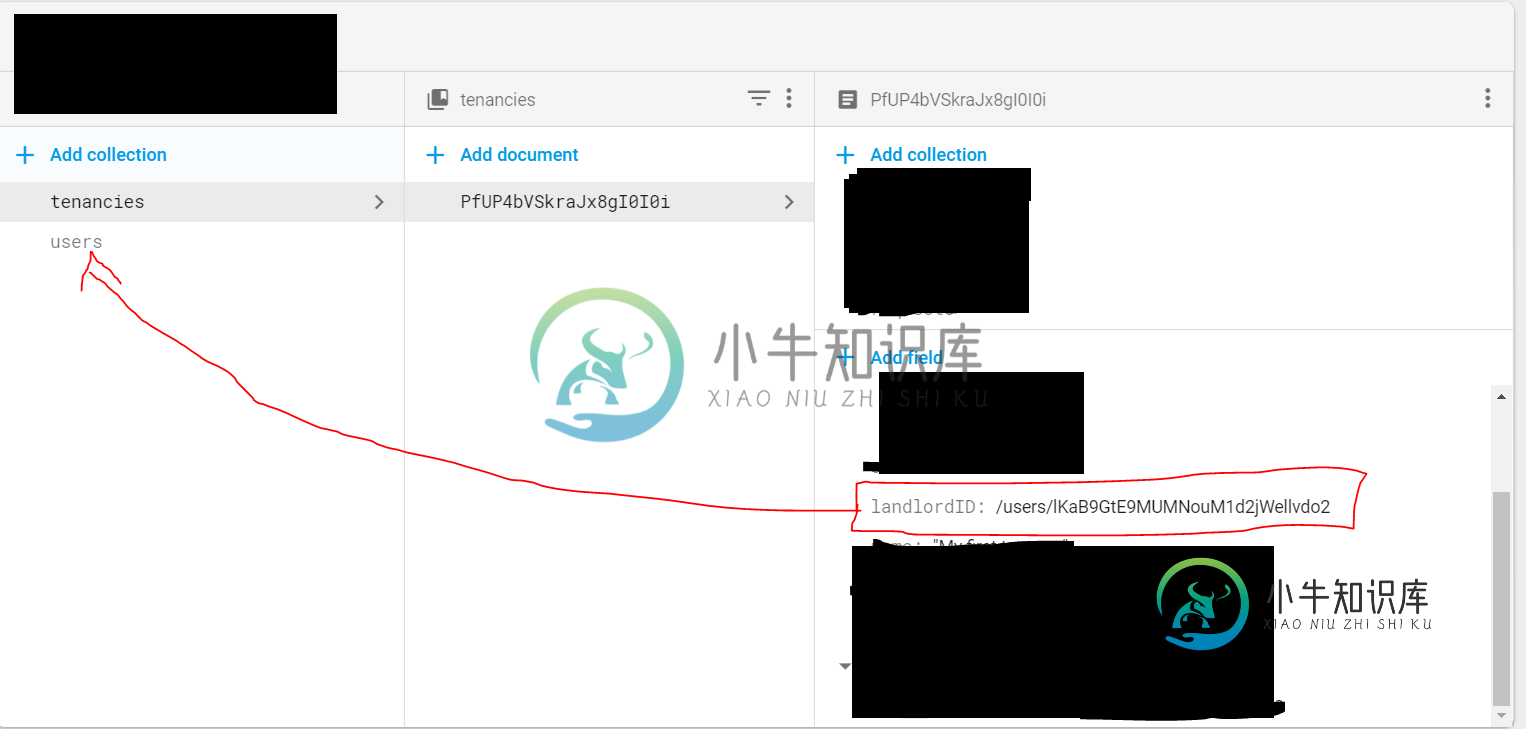 Firestore安全规则获取引用的字段/ID
Firestore安全规则获取引用的字段/ID我有两个收藏-租赁和用户。 租赁单据有一个名为“LandlorDid”的字段,类型为引用(而不是字符串)。 现在,在我的Firestore安全规则中,我希望只有当租用的landlordID字段与发出请求的用户的uid(即匹配时,才允许更新租用。 这应该很简单,但get()根本不起作用。Firebase文档,滚动到“Access other Documents”(访问其他文档)对我的情况没有任何帮助
-
Spark scala基于规则从数组列派生列
我是火花和scala新手。我有一个json数组结构作为输入,类似于下面的模式。 我将数组结构展平到下面的示例数据帧 我的最终目标是为数据质量度量的每一列计算存在/不存在/零计数。但在计算数据质量指标之前,我正在寻找一种方法,为每个数组列元素派生一个新列,如下所示: 如果特定数组元素的所有值都为空,则该元素的派生列为空 如果数组元素至少存在一个值,则将元素存在视为1 如果数组元素的所有值均为零,则我