《消息》专题
-
将SMS消息标记为已读/未读或删除在KitKat中不起作用的消息
-
 在没有慢速消费者的情况下,什么会导致大量挂起的消息?
在没有慢速消费者的情况下,什么会导致大量挂起的消息?我将ActiveMQ与Apache Camel一起使用。现在我遇到了这个问题,在ActiveMQ中有大量挂起的消息。消息处于挂起状态,出列过程非常缓慢。 我的理解正确吗?通常情况下,为了有那么多待处理的消息,每个消费者的调度队列的大小应该已经接近默认的预取限制(即1000)?但每个消费者只有20-80美元? 我对ActiveMq了解不多。那么我应该从哪里了解如何解决这个问题呢? 连接配置01是活动
-
在满足条件之前,如何处理一条消息而不让消息离开队列?
这是关于一个特定的用例,我计划通过flink流来解决这个用例。 一个消息被发送到flink流处理,流被键控,从而得到预期的分区。然而,每个密钥的每个消息都需要评估,直到满足一个条件为止,例如,假设有一个银行系统,其中一个帐户的帐户交易(消息)需要按顺序处理,并且不可能处理不按顺序处理的消息,因为它将导致不一致的系统状态。系统需要等待一条消息被处理(甚至可能超过2-3天),然后再按顺序处理下一条消息
-
仅当重复消息仍与ActiveMQ Artemis和JBoss EAP 7.1排队时,才丢弃重复消息
我们在JBoss EAP7.1上使用ActiveMQ Artemis。 我们注意到,一旦具有特定值的消息通过队列传递,如果消息生成器试图再次将具有相同值的消息发送到同一队列,则代理将丢弃该消息。然而,我们的需要是仅当重复消息仍在队列中时才丢弃它们。 有没有办法达到这个目的? 为了解决这个问题,我们认为像Artemis这样的重复消息检测会有所帮助。然而,当外部应用程序挂起我们的消费者时,我们需要定时
-
MQTT消息在取消订阅后仍然存在,并在再次订阅时重复使用
-
在JMS异步消息处理中,只要调用onMessage(),消息就会从队列中删除
MessageProducer.java public void sendMessage(最终字符串responseStream){ SampleJMSConsumer.java
-
骆驼分割和聚合失败,因为消息将发送到多个并发消费者
我有一个简单的驼峰路由,它接受一个项目列表,将它们拆分,将每个元素发送到mq节点进行处理,然后通过聚合器将它们连接在一起。 非常接近合成消息处理器:http://camel.apache.org/composed-message-processor.html 但是我们注意到拆分后,camel会创建多个并发消费者?或者交换?因为消息被发送给多个消费者,他们永远不会完成。 列表:1,2,3,4 拆分:
-
为什么当消息被消费者拿走时,Kafka主题队列不会为空?[重复]
我正在学习Kafka,如果有人能帮助我理解一件事。“制作人”向Kafka主题发送消息。它会在那里停留一段时间(默认为7天,对吗?)。 但是“消费者”收到这样的信息,永远保持它在那里没有多大意义。我预计当消费者收到它们时,这些信息会消失。否则,当我再次连接到Kafka时,我将再次下载相同的消息。所以我必须管理重复的避免。 它背后的逻辑是什么? 问候
-
如何从Apache Nifi中最后提交的偏移量读取消费者中的Kafka消息?
我已经开始让我的制作人向Kafka发送数据,也让我的消费者提取相同的数据。当我在ApacheNIFI中使用ConsumerKafka处理器(kafka版本1.0)时,我脑海中很少有与kafka consumer相关的查询。 Q.1)当我第一次启动ConsumeKafka处理器时,我如何从开始和当前消息中读取消息? 问题2)以及在Kafka消费者关闭的情况下,如何在最后一条消费信息之后阅读信息? 在
-
呼叫被消息筛选器 (0x80010002) 取消,Windows 服务器 2008年的任务计划程序
我已经在 Windows 服务器 2008年的任务计划程序中计划了我的批处理文件。任务在执行之间自动终止。我检查了任务的历史记录并找到消息: 任务计划程序终止了任务的“{69903b02-c15a-4c67-97b8-3e7d15a125f6}”实例。 使用事件 ID 111。 上次运行结果显示以下消息: 呼叫被消息过滤器取消 (0x80010002) 请建议其原因以及如何在将来避免这种情况?
-
Kafka高级消费者使用Java API从主题获取所有消息(相当于--from-begind)
我正在使用来自Kafka站点的ConsumerGroupExample代码测试Kafka高级消费者。我想检索我在Kafka服务器配置中拥有的关于名为“测试”的主题的所有现有消息。看看其他博客,Auto.offset.reset应该设置为“最小”,才能获取所有消息:
-
消费者/生产者AWS SQS akka scala与synchrone消费者
我的应用程序有一个生产者和一个消费者。我的生产者不定期地生成消息。有时我的队列会是空的,有时我会有一些消息。我想让我的消费者监听队列,当有消息在其中时,接受它并处理这条消息。这个过程可能需要几个小时,如果我的消费者没有完成处理当前消息,我不希望他接受队列中的另一条消息。 我认为AKKA和AWS SQS可以满足我的需求。通过阅读文档和示例,akka-camel似乎可以简化我的工作。 我在github
-
利用PHP实现开心消消乐的算法示例
本文向大家介绍利用PHP实现开心消消乐的算法示例,包括了利用PHP实现开心消消乐的算法示例的使用技巧和注意事项,需要的朋友参考一下 前言 本文主要介绍了关于PHP如何实现我们大家都知道的开心消消乐的算法,分享出来供大家参考学习,下面话不多说了,来一起看看详细的介绍吧。 一、需求描述: 1、在一个8*8的矩阵方格中随机出现5种颜色的色块。 2、当有三个或以上色块在横向或纵向上
-
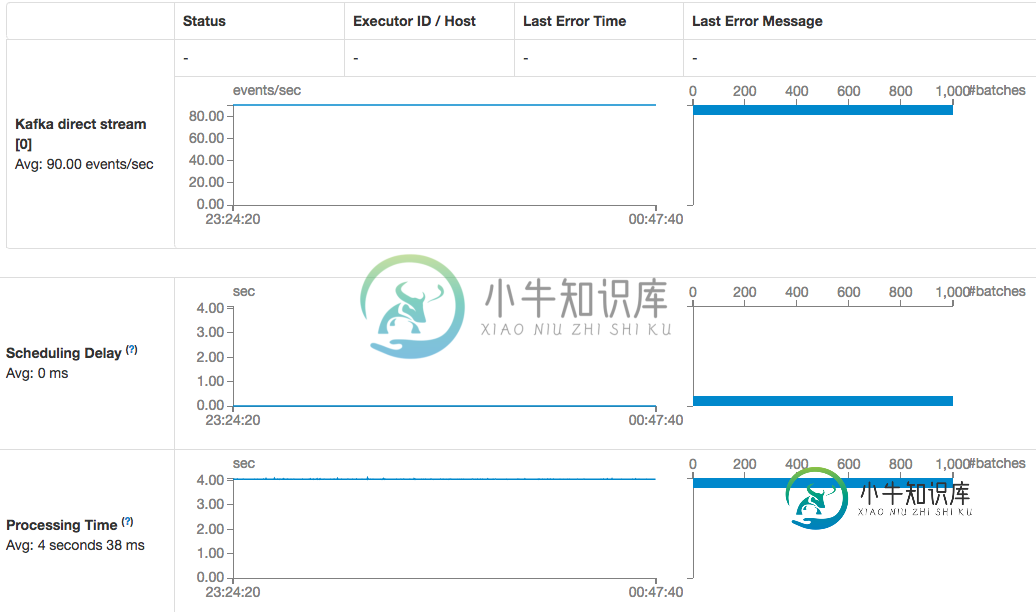 火花流Kafka直接消费者消费速度下降
火花流Kafka直接消费者消费速度下降我使用的是运行在AWS中的spark独立集群(spark and spark-streaming-kafka version 1.6.1),并对检查点目录使用S3桶,每个工作节点上没有调度延迟和足够的磁盘空间。 没有更改任何Kafka客户端初始化参数,非常肯定Kafka的结构没有更改: 也不明白为什么当直接使用者描述说时,我仍然需要在创建流上下文时使用检查点目录?
-
未调用Kafka侦听器方法。消费者不消费。
这是创建ListenerContainerFactory的类 这是我用@KafKalistener注释的Listener类 这是KafkaListenerConfig类,它接受引导服务器、主题名称等。