《深度学习》专题
-
 学习敏捷数据科学
学习敏捷数据科学Agile是一种软件开发方法,通过使用1至4周的短迭代,通过增量会话帮助构建软件,从而使开发与不断变化的业务需求保持一致。 敏捷数据科学包括敏捷方法和数据科学的组合。
-
科学知识:时间复杂度计算方法
本文向大家介绍科学知识:时间复杂度计算方法,包括了科学知识:时间复杂度计算方法的使用技巧和注意事项,需要的朋友参考一下 一、定义 (1)如果一个问题的规模是n,解这一问题的某一算法所需要的时间为T(n),它是n的某一函数 T(n)称为这一算法的“时间复杂性”。我们常用大O表示法表示时间复杂性,称之为大O记法。 (2)一个问题本身也有它的复杂性,如果某个算法的复杂性到达了这个问题复杂性的下界,那就称
-
为什么深度优先搜索的空间复杂度不表示为O(n)?
算法相对较新,所以如果我遗漏了一些显而易见的东西,请原谅! 我知道深度优先搜索的空间复杂度通常表示为O(h),其中h是树的高度,而广度优先搜索的复杂度是O(n),其中n是树中节点的数量。 我理解解释(例如在这个答案中https://stackoverflow.com/a/9844323/10083571)也就是说,在BFS中最坏的情况下,所有节点都在一个级别上,这意味着我们必须在遍历它们之前将所有
-
深度优先搜索(DFS)与广度优先搜索(BFS)伪码和复杂性
我必须为一个算法开发伪代码,该算法计算给定顶点V和边E的图G=(V,E)中连通分量的数量。 我知道我可以使用深度优先搜索或广度优先搜索来计算连接组件的数量。 但是,我想用最高效的算法来解决这个问题,但是我不确定每个算法的复杂度。 下面是一个用伪代码形式写DFS的尝试。 下面尝试以伪代码形式编写 BFS。 我的讲师说BFS与DFS具有相同的复杂性。 然而,当我搜索深度优先搜索的复杂度时,它是O(V^
-
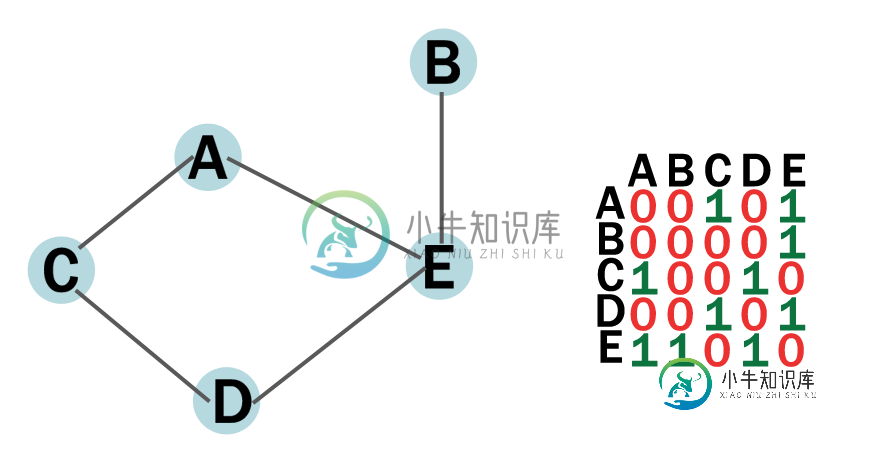 图中两节点之间的深度优先搜索和广度优先搜索
图中两节点之间的深度优先搜索和广度优先搜索我有一个无向连通图。我使用邻接矩阵实现了它,它是一个2维数组。 据我所知,DFS在兄弟节点之前访问子节点。BFS先于孩子探望兄弟姐妹。 这两个我是这样实现的: 如果让我执行一个从D到E的DFS,是D、C、a、E还是D、E。我以为DFS和BFS必须访问每个节点,在这种情况下B不能访问。我不知道我应该如何改变我目前的方法来满足这些要求。
-
机器学习中有哪些不同的梯度下降算法?
本文向大家介绍机器学习中有哪些不同的梯度下降算法?,包括了机器学习中有哪些不同的梯度下降算法?的使用技巧和注意事项,需要的朋友参考一下 使用梯度下降的背后思想是在各种机器学习算法中将损失降至最低。从数学上讲,可以获得函数的局部最小值。 为了实现这一点,定义了一组参数,并且需要将它们最小化。给参数分配系数后,就可以计算误差或损失。接下来,权重被更新以确保误差最小化。除了参数,弱学习者可以是用户,例如
-
深入
组织模块以提供你想要的API形式保持一致是比较难的。 比如,你可能想要这样一个模块,可以用或不用new来创建不同的类型, 在不同层级上暴露出不同的命名类型, 且模块对象上还带有一些属性。 阅读这篇指定后,你就会了解如果书写复杂的暴露出友好API的声明文件。 这篇指定针对于模块(UMD)库,因为它们的选择具有更高的可变性。 核心概念 如果你理解了一些关于TypeScript是如何工作的核心概念, 那
-
Python中最大递归深度是多少,如何增加?
问题内容: 这个尾部递归函数: 它工作到了,然后它破裂并吐出了。这只是堆栈溢出吗?有办法解决吗? 问题答案: 是的,可以防止堆栈溢出。Python(或更确切地说,CPython实现)不能优化尾部递归,无限制的递归会导致堆栈溢出。你可以使用来检查递归限制,并使用来更改递归限制,但是这样做很危险-标准限制有些保守,但是Python堆栈框架可能会很大。 Python不是一种功能语言,尾部递归并不是一种特
-
如何完全遍历未知深度的复杂字典?
问题内容: 从中导入会得到非常复杂的嵌套结构。例如: 推荐使用哪种方法行走上述复杂结构? 除了少数几个目录外,大多数字典都是这样,结构可能变得更加复杂,因此我需要一个通用的解决方案。 问题答案: 您可以使用递归生成器将字典转换为平面列表。 它返回 更新 :固定键列表从到,如注释中所述。
-
如何获取未知JSON层次结构的总深度?
问题内容: 我一直在努力寻找/构建一个递归函数来解析此JSON文件并获取其子级的总深度。 该文件如下所示: 问题答案: 您可以使用递归函数遍历整个树: 该函数的工作原理如下: 如果对象不是叶子(即对象具有children属性),则: 计算每个孩子的深度,保存最大的一个 返回1 +最深的孩子的深度 否则,返回1 jsFiddle:http : //jsfiddle.net/chrisJamesC/h
-
在二叉搜索树中查找数据点的深度
这是家庭作业。不要只发布代码。 我需要在二进制搜索树中找到给定数据点的深度。我实现了一个<code>depth()</code>方法和一个helper方法<code>countNodes()</code>,它递归地对节点进行计数。 如果我们要搜索的数据不在树中,我需要返回< code>-1。根据我的递归,我看不出这怎么可能。
-
pugiXML:如何在XML树中进行深度优先遍历
我有以下XML文件,希望使用PugiXML库将其解析为C++: 我用C++创建了一个图结构。现在的任务是从XML文件到C++图结构。这是我目前为止最好的尝试: 这段代码的问题在于它只处理XML节点“graph”。并不是所有的孩子都能接受。我发现一个可能的解决方案是使用深度优先遍历XML树。您可以在这里找到相应的文档(查找“Simple Walker”示例)。现在我被困住了,我不知道如何实现“简单的
-
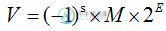 C++中double浮点数精度丢失的深入分析
C++中double浮点数精度丢失的深入分析本文向大家介绍C++中double浮点数精度丢失的深入分析,包括了C++中double浮点数精度丢失的深入分析的使用技巧和注意事项,需要的朋友参考一下 看了一篇关于C/C++浮点数的博文,在Win32下,把int, 指针地址,long等4字节整数赋给一个double后,再用该double数赋给原始类型的数,得到的结果于最初的数值一致,即不存在任何精度丢失。例如下面的结果将总是true: 但是对于l
-
如何删除node_modules-Windows中的深度嵌套文件夹
问题内容: 尝试删除以下 用户 创建的 node_modules 目录时: 源文件名大于文件系统支持的文件名。尝试移动到路径名较短的位置,或尝试重命名为较短的名称,然后再尝试执行此操作 我也尝试过+ ,但仍然遇到相同的问题。 问题答案: 由于这是Google的最佳搜索结果,因此这对我有用: 安装RimRaf: 在项目文件夹中,使用以下命令删除node_modules文件夹: 如果要递归删除: [
-
angular.js链接行为-禁用特定URL的深度链接
问题内容: 我有一个启用HTML5模式的Angular.js应用程序。 我要实现的是获取一些URL或标签来执行正常的浏览行为,而不是使用HTML5历史API更改地址栏中的URL并使用Angular控制器对其进行处理。 我有这个链接: 我希望浏览器将用户重定向到,以便将用户重定向到身份验证服务。 有什么办法可以做到吗? 问题答案: 在Angular 1.0.1中添加作品: 记录了此功能(https: