《深度学习》专题
-
深度克隆PDPAGE的正确方法是什么?
我正在使用PDFBoxV2,我正在尝试克隆PDDocument的第一个PDPage,以保留它作为新PDPages的模板。第一页,有一些顶形字段,我需要填充。 我尝试了一些方法,但任何人都让我想要实现。 谢谢!
-
深度信念网络vs卷积神经网络
我是神经网络领域的新手,我想知道深度信念网络和卷积网络之间的区别。还有,有没有深度信念和卷积神经网络相结合的深度卷积网络? 这就是我目前所收集到的。如果我错了请纠正我。 对于图像分类问题,深度信念网络有许多层,每个层都使用贪婪的分层策略进行训练。例如,如果我的图像大小是50x50,我想要一个有4层的深度网络,即 输入层 隐藏层1(HL1) 隐藏层2(HL2) 输出层 如果使用卷积神经网络解决了同样
-
react-使用react-table超过最大更新深度
尝试在基本应用程序中包含 react-table,该应用程序在字段中接受输入,在字段内容更改时将其存储在组件状态中,然后在按下按钮时从 Github 获取数据。 在我加上线之前一切正常 该页面可以正常加载,但是当输入字段改变时(即你在其中输入),应用程序崩溃并显示错误: 错误:超过了最大更新深度。当组件重复调用componentWillUpdate或componentDidUpdate内部的set
-
反应性:超出最大更新深度错误
我目前收到Maxiumum更新深度错误,不知道为什么。在我的代码中看不到无限循环。 "超过了最大更新深度。当组件在useEffect内部调用setState时,可能会发生这种情况,但useEffect要么没有依赖关系数组,要么其中一个依赖关系在每次渲染时都会发生变化。 此处显示错误 ReactJS组件代码: 下面的代码似乎有错误:超过了最大更新深度。当组件在useEffect中调用setState
-
RESOLVE:反应错误:超过最大更新深度
我有这个错误:错误:超过最大更新深度。当组件重复调用componentWillUpdate或componentDidUpdate内部的setState时,会发生这种情况。React限制嵌套更新的数量,以防止无限循环。 但是我不明白怎么解决!我只是在发布我的代码,对不起… 我的代码:
-
最大更新深度超过新状态React-Native
const[number, setNum]=useState(0);当我想添加和更改它时,我收到了这个错误(setNum(number 1))。我的错误:超过了最大更新深度。当组件在组件WillUpdate或组件DiUpdate中重复调用setState时,可能会发生这种情况。React限制嵌套更新的数量以防止无限循环。我能做些什么来解决这个问题?
-
图文解析图论DFS(深度优先搜索)
DFS 全称是 Depth First Search,中文名是深度优先搜索,是一种用于遍历或搜索树或图的算法。所谓深度优先,就是说每次都尝试向更深的节点走。 一、图搜索Graph Search的分类 (1)BFS广度优先(宽搜) (2)DFS深度优先(深搜) 二、深度优先搜索DFS (1)深度优先遍历DFS, 这个策略其实是非常stupid or simple的,比BSF要简单的多 (2)同样,我
-
 学习Java模拟实现百度文档在线浏览
学习Java模拟实现百度文档在线浏览本文向大家介绍学习Java模拟实现百度文档在线浏览,包括了学习Java模拟实现百度文档在线浏览的使用技巧和注意事项,需要的朋友参考一下 这个思路是我参考网上而来,代码是我实现。 采用Apache下面的OpenOffice将资源文件转化为pdf文件,然后将pdf文件转化为swf文件,用FlexPaper浏览。 ok, A、下载OpenOffice (转换资源文件) B、下载JodConverter(
-
无论学习速度如何,损失都不会改变
我构建了一个深度学习模型,与VGG网略有相似。我正在使用带有Tensorflow后端的Keras。模型摘要如下: 我尝试了优化器(SGD,Adam等),损失(MSE,MAE等),批大小(32和64)的不同组合。我甚至尝试过从0.001到10000的学习率。但是,即使在 20 个 epoch 之后,无论我使用哪种损失函数,验证损失仍然完全相同。训练损失变化不大。我做错了什么? 我的网络应该训练做什么
-
 百度 机器学习算法工程师 共享求捞
百度 机器学习算法工程师 共享求捞[toc] 百度 机器学习算法工程师 凉经 投递 2022.07.25 牛客投递,后面牛客上内推了,发了一个内推确认链接,就等于是官网内推投递吧应该 一面通知 2022.07.29 通知面试,直接发的2022.08.02 晚上 20 : 00一面 一面 2022.08.02 面试时长:60 min 面试平台: 如流(百度自家的) 面试过程,分为3部分 项目 介绍项目,问了两个项目 在问项目过程中,
-
 百度机器学习算法提前批一面凉经
百度机器学习算法提前批一面凉经约的8点开始, 8点面试官进来后说要上卫生间,等到8点10分开始,一共60分钟。 1、开始先聊了会儿在字节实习的内容,主要聊场景; 2、聊完后开始问xgboost(简历有写),很细,都是答完后继续往下深挖,答的不好: 和GBDT的区别 什么场景用lr,什么场景用xgboost,什么场景用nn 构造树的过程 怎么来做多分类的 。。。 3、auc指标的含义 4、分类问题为什么用交叉熵不用mse,从公式
-
 百度提前批机器学习岗位一面凉经
百度提前批机器学习岗位一面凉经不用自我介绍,就是聊项目,面试官人特别好,我特别菜 大概讲了讲项目后做算法题, 第一题self-attention,用pytorch,继承pytorch.nn.Module写forward函数,没写出来,如果写出来了应该会继续写mask self-attention 第二题求前K个高频数 第三题二叉树 前序遍历中序遍历后序遍历 然后根据后序和中序结果写前序遍历 机器学习问了过拟合 决策树,xgb和
-
 百度地图机器学习算法工程师二面
百度地图机器学习算法工程师二面这次面试官没有迟到,没有机会水了。。。 不过是个女面试官,非常亲和的感觉 开局自我介绍,讲了一下学的课程内容和做的课设项目,了解了一下大概情况 重点分析讲了一下数据竞赛的内容 八股: 1.讲一下集成学习的一些算法 2.GBDT,XGBoost,LightGBM各自有什么优势劣势,适用情况 3.独热编码和embedding的用途,各自优势,为什么用 4.为什么在项目中用了GBDT而不是RF 5.讲一
-
 百度地图机器学习算法工程师一面
百度地图机器学习算法工程师一面开局面试官迟到6分钟。。。 自我介绍了一下就10分钟了 问了一下自我介绍说的开源经历和项目,问了个项目地址 问了大模型SFT和LORA的区别和应用 然后八股和项目就一点不问了?????? 我早起背了这么多机器学习的八股有啥用? 然后手撕了一道快速排序,写了个测试用例就快速下班了 反问: 1.部门业务:百度地图数据分析处理,机器学习做预测,自动化 2.岗位竞争:说小于10个人在面,应该不止一个1个h
-
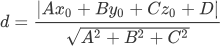 从数学角度理解SVM分类算法
从数学角度理解SVM分类算法主要内容:再谈间隔最大化,再谈核函数本节将从数学角度讲解支持向量机(SVM)相关知识,掌握这些有利用加深对 SVM 算法原理的理解,对于学习任何一款机器学习算法都是非常有帮助的,虽然各种数学公式很难懂,但本人会尽最大努力去讲明白。尽管如此由于每位读者的数学基础不一样,如有表达不到位的地方,还请海涵。 再谈间隔最大化 我们知道,支持向量机是以“间隔”作为损失函数的,支持向量机的学习过程就是使得间隔最大化的过程,若想要了解支持向量机的运