《算法求职》专题
-
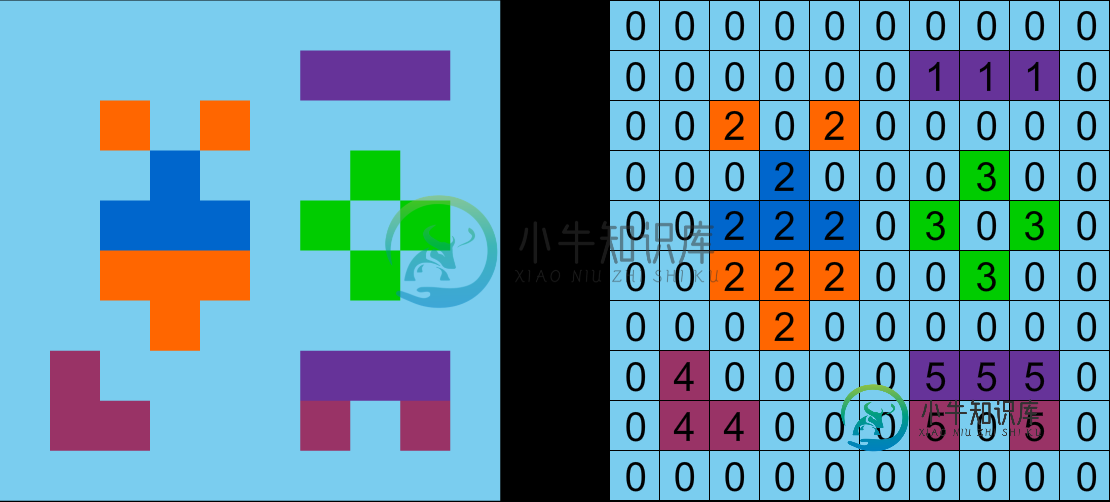 MATLAB中的图像分割算法
MATLAB中的图像分割算法我需要在MATLAB中实现一个基于连通分量算法原理的图像分割函数,但需要做一些修改。这是为了非常简单的2D图像,有一个背景颜色和一些不同颜色的对象。 其思想是,将图像作为一个矩阵,我提供了一个选择背景颜色的工具(它将对每个图像变化)。然后,当图像的背景颜色的值被选中时,我要对图像中的所有对象进行分割,结果应该是一个带标签的矩阵,图像大小相同,背景为0,每个对象有不同的数字。 这是我的意思的一个生动
-
泛洪填充算法导致StackOverFlowError
我正在编程一个简单的绘画应用程序使用Java。我试图使用洪水填充算法的递归实现作为我的“桶填充”工具。 我想知道是否有一种方法仍然使用递归与这个算法,而不得到这个错误。 如果没有,这个算法有哪些可能的非递归实现,我可以在我的程序中使用?
-
Dijkstra算法的优先级队列
我正在为Dikjstra算法做一个优先级队列。我目前在插入方法上有麻烦。我包含了整个类的代码,以防你需要更好地了解我想完成的事情。我将堆索引放在一个数组列表(heapIndex)中,堆放在另一个数组列表中。 那是我运行程序后的输出(值,优先级,堆索引)。*(-1)表示heapIndex中的空单元格。
-
背包算法,怪异行为(python3)
我一直在研究递归,并试图解决背包问题[https://en.wikipedia.org/wiki/Knapsack_problem]。我想出了下面的算法,它工作得很好: 这里奇怪的是,只有当调用初始函数的重量为,并且时,才会出现这种行为。 谢谢, D_Darric
-
ECIES是公开加密算法吗?
-
寻找相似面孔的算法?
我正在做一个个人项目,试图找到一个人的长相,因为数据库中有其他人的照片,所有照片都是以一致的方式拍摄的——人们直视相机,表情中立,不歪头(想想护照照片)。 我有一个系统,用于在人脸上放置二维坐标的标记,我想知道是否有任何已知的方法可以在这种方法下找到一张相似的脸? 我找到了以下面部识别算法:http://www.face-rec.org/algorithms/ 但是,没有一个专门负责寻找相貌相似的
-
四色定理的递归算法
目前的问题是,将一张地图分成邻接矩阵中表示的区域,并使用四种颜色对地图进行着色,以确保没有两个相邻区域共享相同的颜色。我们将使用邻接矩阵来编码哪个区域与哪个其他区域相邻。矩阵的列和行是区域,如果两个区域不相邻,则单元格包含0,如果两个区域相邻,则单元格包含1。创建一个递归回溯解决方案,该方案接受用户的交互输入,即地图中的区域数和表示地图组成的邻接矩阵的文件名。 问题是,我遇到的是,第一个值在国家颜
-
带厚度绘制算法的圆
目前我正在使用Bresenham的圆圈绘制算法,它可以精细地绘制圆圈,但是我想要一种相对快速有效的方法来绘制具有指定厚度的圆圈(因为Bresenham的方法只绘制单个像素厚度)。我意识到我可以简单地绘制多个具有不同半径的圆圈,但我相信这将是非常低效的(并且效率很重要,因为这将在每微秒都很宝贵的Arduino上运行)。我目前使用以下代码: 我如何修改它以允许指定圆的厚度?PS我不想使用任何外部库,请
-
“中位数”算法的Python实现
我已经用python编写了medians算法的median的实现,但是它似乎没有输出正确的结果,而且对我来说它似乎也没有线性复杂度,知道我哪里出错了吗? 这个函数是这样调用的: 乐:不好意思。GetMed是一个简单地对列表排序并返回len(list)处的元素的函数,它应该在那里被选择,我现在修复了它,但我仍然得到错误的输出。至于缩进,代码工作没有错误,我看不出有什么问题:-?? LE2:我期望50
-
Java与Javascript兼容的AES算法
我需要使用AES算法加密Java应用程序中的一些值,并在我的应用程序的Javascript模块中解密相同的值。 我在互联网上看到了一些例子,但在兼容性方面似乎有些不同。 多谢了。
-
Prim算法在Java中的实现
我试图在Java中实现Prim的算法,用于我的图形HashMap LinkedList和一个包含连接顶点和权重的类Edge: 我的想法是,从一个给定的顶点开始:1)将所有顶点保存到一个LinkedList中,这样每次访问它们时我都可以删除它们2)将路径保存到另一个LinkedList中,这样我就可以得到我的最终MST 3)使用PriorityQueue找到最小权重 最后我需要MST,边数和总重量。
-
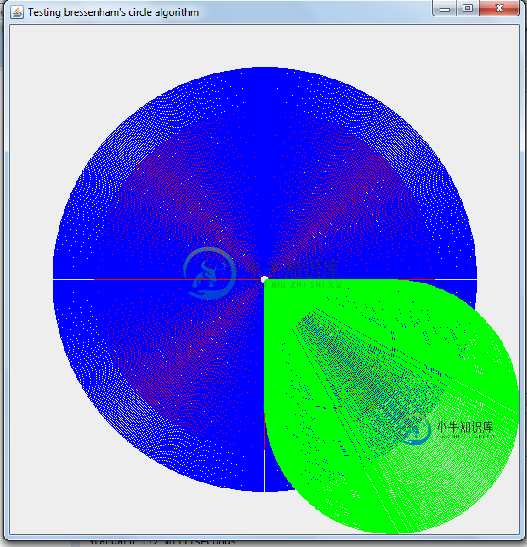 Bresenham圆绘制算法的实现
Bresenham圆绘制算法的实现我已经写了一个Bresenham的圆绘制算法的实现。该算法利用了圆的高度对称特性(它只计算第一个八分之一的点,并利用对称性绘制其他点)。因此,我希望它会非常快。《图形编程黑皮书》第35章的标题是“Bresenham是快的,而且快是好的”,虽然它是关于线条绘制算法的,但我可以合理地预期圆形绘制算法也很快(因为原理是一样的)。 这是我的java,摇摆实现 此方法使用以下方法: getNativeX和g
-
合并排序算法不工作
我正在尝试实现一个不能正常工作的mergesort算法。合并排序的工作方式如下: i、 将未排序的列表划分为n个子列表,每个子列表包含1个元素(1个元素的列表被视为已排序)。 ii.重复合并子列表以产生新排序的子列表,直到只剩下1个子列表。这将是已排序的列表。下面提供了实现。 最初,递归调用此方法,直到只有一个元素。 这是提供的合并方法。 这里的问题是什么? 输入是输出是
-
Ford-Fulkerson算法的一种改进
假设我们重新定义剩余网络,不允许边进入。认为福特-富尔克森的程序仍然正确地计算了最大流量。 我在想,当我们增加一条路径时,反向边缘的剩余容量会增加,如果需要,可以用来减少该边缘的流量(但总体上增加网络流量)。因此,如果我们不允许边进入,这意味着我们不允许边中的流减少(是的相邻节点)。因此,当我们允许边进入时,我们可以有一个类似的循环 但是如果我们再次禁止边进入,我们可以在没有循环的情况下找到相同的
-
Kafka消费者再平衡算法
有人能告诉我Kafka消费者的再平衡算法是什么吗?我想了解分区计数和消费者线程是如何影响这一点的。 非常感谢。