《算法求职》专题
-
无法从请求中提取JSESSIONID
我有登录请求,在请求中我获得了JSESSIONID和XSRF-TOKEN作为Cookie数据,如下所示 如果需要,如何从响应中提取JSESSIONID,以便在注册Cookie中传递该变量 在此处输入图像描述
-
要算是不算算?
问题内容: 我正在开发一个新的网站,我想尽可能多地使用AJAX。基本上,我希望用户几乎永远不要离开主页,并在弹出窗口,滑块,部分等中显示所有内容。 现在我们现有的网站已经排名很高,所以我也想让Google开心。我一直在阅读Google提供的使AJAX应用程序可抓取的方法,并且了解到我必须通过 escaped_fragment 为抓取工具提供相同的内容。 我想使用 已经提供了SEO友好URL的 Um
-
无法与不可重复的请求实体重试请求
问题内容: 我在客户端使用Java-http-client库和Apache Transport,在服务器端使用Rails。有时会出现如下所示的获取错误: 我应该怎么做才能避免这种情况? 问题答案: 我有一个类似的错误,因为我使用了CountingInputStreamEntity这是一个不可重复的http客户端。解决方案是使用BufferedHttpEntity,它将不可重复的HTTP客户端转换为
-
如何在请求前在Swagger中计算AWS签名V4
对于我们的AWS APIendpoint,我们使用AWS_IAM授权,并希望从Swagger UI进行调用。要成功调用,必须有两个标题“Authorization”和“x-amz-date”。为了形成“授权”,我们使用aws文档中的以下步骤。我们必须在每次通话中更改“x-amz-date”才能通过授权。问题是:如何在Swagger中编写脚本来签署请求,该脚本在每次请求发送到aws之前都会运行?(我
-
共识算法有哪些类型?
本文向大家介绍共识算法有哪些类型?相关面试题,主要包含被问及共识算法有哪些类型?时的应答技巧和注意事项,需要的朋友参考一下 回答:** 可用的最受欢迎的共识算法如下: 工作量证明(PoW) 容量证明(PoC) 活动证明(PoA) 委托权益证明(DPoS) 股权证明(PoS) 权威证明 燃烧证明 唯一节点列表 重量证明 证明时间 筛 拜占庭容错
-
算法题,trim二叉搜索树
本文向大家介绍算法题,trim二叉搜索树相关面试题,主要包含被问及算法题,trim二叉搜索树时的应答技巧和注意事项,需要的朋友参考一下 参考回答: C++版本
-
Python猜数字算法题详解
本文向大家介绍Python猜数字算法题详解,包括了Python猜数字算法题详解的使用技巧和注意事项,需要的朋友参考一下 今天刷的第一道算法题,先拿一道简单点的试试手,这道题目的要求是: 两个人甲乙在猜数字,甲先从1,2,3三个数字中随机抽3次,结果是guess。乙随后也随机抽三次,结果是answer。然后对比甲乙两个人的结果。示例如下: guess:[1,2,3], answer: [1, 2,
-
获得最佳组合的算法
问题内容: 我有ID为的商品。现在我有如下数据。每行都有一个offerId。由数组中的组合组成。是那个的价值 现在,我必须选择所有给我提供最佳ID组合(即最大总折扣)的offerId。 例如,在上述情况下:可能的结果可能是: [o2,o4,o5]最大折扣为。 注意。结果offerId应该不会重复ID。id的示例为[1,3,4],[5],[6]都是不同的。 其他组合可以是: 其id为[1],[3,5
-
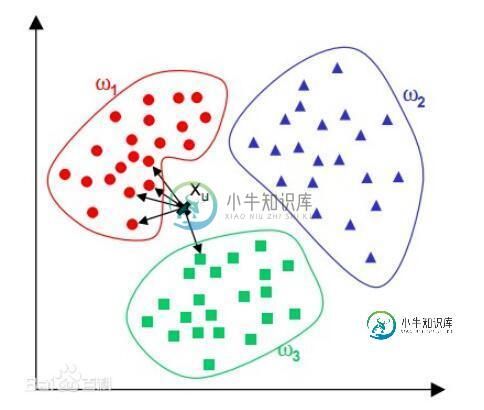 用Python实现KNN分类算法
用Python实现KNN分类算法本文向大家介绍用Python实现KNN分类算法,包括了用Python实现KNN分类算法的使用技巧和注意事项,需要的朋友参考一下 本文实例为大家分享了Python KNN分类算法的具体代码,供大家参考,具体内容如下 KNN分类算法应该算得上是机器学习中最简单的分类算法了,所谓KNN即为K-NearestNeighbor(K个最邻近样本节点)。在进行分类之前KNN分类器会读取较多数量带有分类标签的样本
-
Python排序算法实例代码
本文向大家介绍Python排序算法实例代码,包括了Python排序算法实例代码的使用技巧和注意事项,需要的朋友参考一下 排序算法,下面算法均是使用Python实现: 插入排序 原理:循环一次就移动一次元素到数组中正确的位置,通常使用在长度较小的数组的情况以及作为其它复杂排序算法的一部分,比如mergesort或quicksort。时间复杂度为 O(n2) 。 选择排序 原理:每一趟都选择最小的值和
-
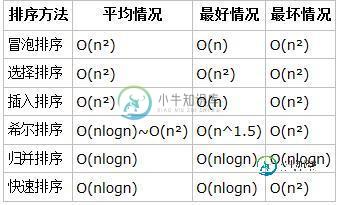 js实现常用排序算法
js实现常用排序算法本文向大家介绍js实现常用排序算法,包括了js实现常用排序算法的使用技巧和注意事项,需要的朋友参考一下 本文为大家分享了js实现常用排序算法,具体内容如下 1.冒泡排序 2.选择排序 3.插入排序 4.希尔排序 5.归并排序 6.快速排序 总结:算法效率比较: 以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持呐喊教程。
-
 python实现C4.5决策树算法
python实现C4.5决策树算法本文向大家介绍python实现C4.5决策树算法,包括了python实现C4.5决策树算法的使用技巧和注意事项,需要的朋友参考一下 C4.5算法使用信息增益率来代替ID3的信息增益进行特征的选择,克服了信息增益选择特征时偏向于特征值个数较多的不足。信息增益率的定义如下: 调用代码 以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持呐喊教程。
-
Java中的基本方向算法
问题内容: 这个周末,我花了几分钟时间讨论一种算法,该算法将采用一个标题(以度为单位)并返回一个基数方向的String(我正在我使用的android指南针应用程序中使用它)。我最终得到的是: 我的问题是,这是最好的方法吗?尽管我还没有在网上搜索示例,但它必须做过很多次。是否有其他人尝试过此方法并找到了更整洁的解决方案? 编辑The Reverand’s Thilo’s,shinjin’s和Chrs
-
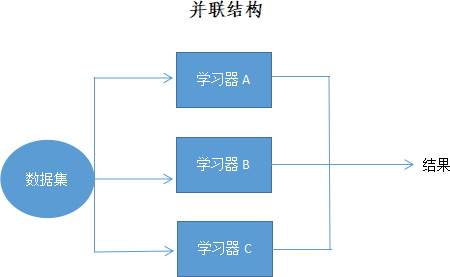 什么是集成学习算法
什么是集成学习算法主要内容:集成学习发展史,集成学习组织方式,预测结果的方式,集成学习实现方法经过前面的学习,我们认识了机器学习中的常用回归算法、分类算法和聚类算法,在众多的算法中,除神经网络算法之外,没有一款算法模型预测准确率达到 100%,因此如何提高预测模型的准确率成为业界研究的重点。通过前面内容的学习,你可能会迅速想到一些方法,比如选择一款适合的算法,然后反复调整各种参数,其实这并不是最佳的方法,有以下三点原因: 一是任何算法模型都有自身的局限性; 二是反复调参会浪费许多不必要的时
-
什么是K-means聚类算法
主要内容:聚类和分类的区别,找相似,簇是什么,理解K的含义,如何量化“相似”,总结机器学习算法主要分为两大类:有监督学习和无监督学习,它们在算法思想上存在本质的区别。 有监督学习,主要对有标签的数据集(即有“参考答案”)去构建机器学习模型,但在实际的生产环境中,其实大量数据是处于没有被标注的状态,这时因为“贴标签”的工作需要耗费大量的人力,如果数据量巨大,或者调研难度大的话,生产出一份有标签的数据集是非常困难的。再者就算是使用人工来标注,标注的速度也会比数据生产的速度慢的多。因