《算法求职》专题
-
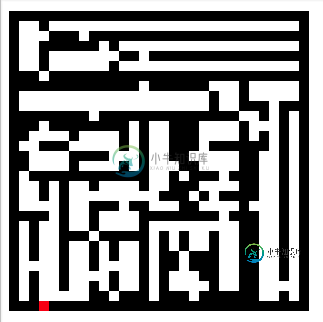 迷宫(递归除法)算法设计
迷宫(递归除法)算法设计我目前正在开发一个随机迷宫生成器,它将迷宫存储在一个名为< code>grid的二维数组中。这将随后用于生成一个真实的3D迷宫,用户可以在其中穿行。 在做了一些研究之后,我试图使用递归除法算法创建这个迷宫生成器,但是由于迷宫格式的性质,这对我来说并不是真的有效。 据我所知,递归分裂方法并不将壁视为细胞。 例如,我的网格如下所示: 我想在这里说的是,我试图创建的网格将像这样表示: 其中“w”是墙,“
-
 小米多模态算法python解法
小米多模态算法python解法本人python写的 1.四数之和的变形题,复杂度O(n^2) 2.编辑距离变形题 下面附上代码,可以参考一下,但具体的细节有问题的话可能是记不清了
-
Go中的指针算法
问题内容: 考虑到您可以(无法想到一种放置它的好方法,但是)在Go中操作指针,是否有可能像在C中那样执行指针算术,例如遍历数组?我知道循环对于这些事情来说现在很好,但是我很好奇是否可能。 问题答案: 否。来自“常见问题解答”: 为什么没有指针算术? 安全。如果没有指针算术,就有可能创建一种永远不会派生出不正确地址的语言。编译器和硬件技术已经发展到可以使用数组索引的循环与使用指针算术的循环一样高效的
-
JSchException:算法协商失败
问题内容: 我正在尝试使用JSch(0.1.44-1)通过ssh连接到远程sftp服务器,但是在“ session.connect();”期间 我收到此异常: 来自JSch的日志: 我可以使用linux sftp命令登录到远程服务器。我试图在互联网上找到任何线索,但是失败了。 linux sftp命令的调试输出: 问题答案: SSH客户端和服务器在几个地方尝试并同意一个通用实现。我知道的两个是加密
-
什么是高/低算法?
问题内容: 什么是高/低算法? 我已经在NHibernate文档中找到了这一点(这是生成唯一密钥的一种方法,第5.1.4.2节),但是我没有找到有关其工作原理的很好的解释。 我知道Nhibernate可以处理它,并且我不需要了解内部,但是我很好奇。 问题答案: 基本思想是,您有两个数字组成主键-“高”数字和“低”数字。客户端可以从本质上增加“高”序列,知道它随后可以安全地从先前的“高”值的整个范围
-
KMP 算法实例详解
本文向大家介绍KMP 算法实例详解,包括了KMP 算法实例详解的使用技巧和注意事项,需要的朋友参考一下 KMP 算法实例详解 KMP算法,是由Knuth,Morris,Pratt共同提出的模式匹配算法,其对于任何模式和目标序列,都可以在线性时间内完成匹配查找,而不会发生退化,是一个非常优秀的模式匹配算法。 分析:KMP模板题、KMP的关键是求出next的值、先预处理出next的值、然后一遍扫过、复
-
SQL中的匹配算法
问题内容: 我的数据库中有下表。 每个人在工作中均按不同的属性/标准(称为“ prop”)进行排名,而绩效则称为“等级”。如示例所示,该表包含(name,prop)的多个值。我想从某些要求中获得最佳人选。例如,我需要具有和的候选人。然后,我们必须能够按候选人的排名对他们进行排序,以获得最佳候选人。 编辑:每个人都必须满足所有要求 如何在SQL中执行此操作? 问题答案:
-
Java抽奖抢购算法
本文向大家介绍Java抽奖抢购算法,包括了Java抽奖抢购算法的使用技巧和注意事项,需要的朋友参考一下 本文示例为大家分享了Java抽奖抢购算法,供大家参考,具体内容如下 应用场景 单件奖品抢购(可限时) 多件奖品按概率中奖(可限时、可不限量) 代码实现 表结构: 代码: 以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持呐喊教程。
-
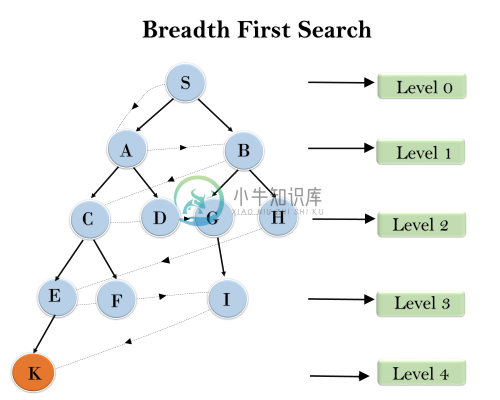 不知情搜索算法
不知情搜索算法主要内容:1. 广度优先搜索,2. 深度优先搜索,3. 深度有限搜索算法,4. 统一成本搜索算法,5. 迭代深化深度搜索,6. 双向搜索算法不知情的搜索是一类通用搜索算法,它以强力方式运行。除了如何遍历树之外,不知情的搜索算法没有关于状态或搜索空间的附加信息,因此它也称为盲搜索。 以下是各种类型的无知搜索算法: 广度优先搜索 深度优先搜索 深度限制搜索 迭代加深深度优先搜索 统一成本搜索 双向搜索 1. 广度优先搜索 广度优先搜索是遍历树或图的最常见搜索策略。此算法在树或图中搜索横向,因此称为广
-
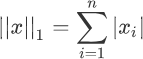 应用Logistic回归算法
应用Logistic回归算法主要内容:什么是范数?,回归类算法,实现Logistic回归在 Scikit-Learn 机器学习库中,有关线性模型的算法族都在 模块下,不同的算法又会分化为很多类,但它们都是经过几种基本算法调整和组合而成,因此基本上都是 大同小异,换汤不换药,下面介绍经常用到回归类算法,其中就包含了 Logistic 回归算法。在这之前我们需要先熟悉几个概念,比如“正则化”。 什么是范数? 范数又称为“正则项”,它是机器学习中会经常遇到的术语,它表示了一种运算方式,“范
-
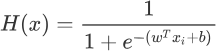 数学解析Logistic算法
数学解析Logistic算法主要内容:分类数据表示形式,Logistic函数数学解析,梯度上升优化方法在 《Logistic回归算法(分类问题)》一节,我们学习了 Logistic 回归算法,并且重点认识了 Logistic 函数。我们知道分类问题的预测结果是离散型数据,那么我们在程序中要如何表述这些数据呢,再者我们要如何从数学角度理解 Logistic 算法,比如它的损失函数、优化方法等。 分类数据表示形式 1) 向量形式 在机器学习中,向量形式是应用最多的形式,使用向量中的元素按顺序代表“类别
-
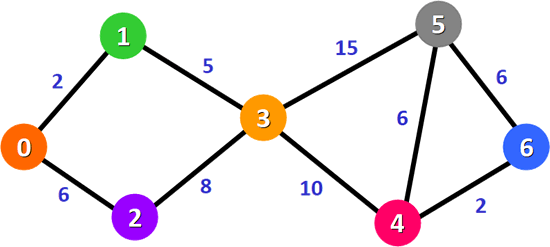 迪杰斯特拉算法
迪杰斯特拉算法主要内容:迪杰斯特拉算法的实现思路,迪杰斯特拉算法的具体实现迪杰斯特拉算法用于查找图中某个顶点到其它所有顶点的最短路径,该算法既适用于无向加权图,也适用于有向加权图。 注意,使用迪杰斯特拉算法查找最短路径时,必须保证图中所有边的权值为非负数,否则查找过程很容易出错。 迪杰斯特拉算法的实现思路 图 1 是一个无向加权图,我们就以此图为例,给大家讲解迪杰斯特拉算法的实现思路。 图 1 无向加权图 假设用迪杰斯特拉算法查找从顶点 0 到其它顶点的最短路径,具体过
-
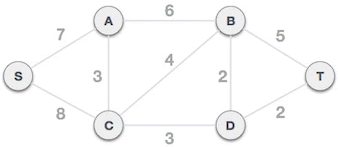 克鲁斯卡尔算法
克鲁斯卡尔算法主要内容:克鲁斯卡尔算法的具体实现在连通网中查找 最小生成树的常用方法有两个,分别称为 普里姆算法和克鲁斯卡尔算法。本节,我们给您讲解克鲁斯卡尔算法。 克鲁斯卡尔算法查找最小生成树的方法是:将连通网中所有的边按照权值大小做升序排序,从权值最小的边开始选择,只要此边不和已选择的边一起构成环路,就可以选择它组成最小生成树。对于 N 个顶点的连通网,挑选出 N-1 条符合条件的边,这些边组成的生成树就是最小生成树。 举个例子,图 1 是
-
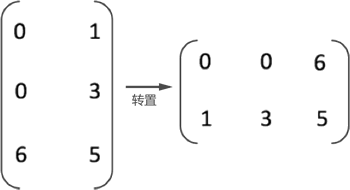 矩阵的转置算法
矩阵的转置算法矩阵(包括稀疏矩阵)的转置,即互换矩阵中所有元素的行标和列标,如图 1 所示: 图 1 矩阵转置示意图 但如果想通过程序实现矩阵的转置,互换行标和列标只是第一步。因为实现矩阵转置的前提是将矩阵存储起来, 数据结构中提供了 3 种存储矩阵的结构,分别是三元组 顺序表、行逻辑链接的顺序表和十字 链表。如果采用前两种结构,矩阵的转置过程会涉及三元组表也跟着改变的问题,如图 2 所示: 图 2 三元组表的
-
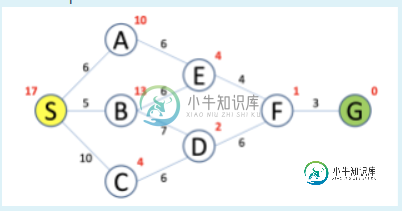 A*算法需要澄清
A*算法需要澄清我认为用A*算法应该是SAEFG,但答案是SBEFG。现在我的教授是一个无所事事的人。有人能解释为什么是SBEFG吗?