《运筹优化》专题
-
EF5代码优先:检测它是否创建数据库,以便我可以运行ALTER语句
问题内容: 我是Entity Framework 5的新手。我们的团队正在使用工作流。 在开始我的主要问题之前, 让我先向您展示我已经尝试过的东西 ( 所有时间的最终评语)。 是我创建的类,该类继承自,其中包含重写方法,该类也继承自。我遇到的问题之一是实体框架无法处理字段唯一性。我已经在他们的站点上阅读了有关使用Fluent API配置/映射属性和类型 的文章,但是找不到用于将属性设置为唯一的任何
-
说说 JDK1.6 之后的synchronized 关键字底层做了哪些优化,可以详细介绍一下这些优 化吗?
本文向大家介绍说说 JDK1.6 之后的synchronized 关键字底层做了哪些优化,可以详细介绍一下这些优 化吗?相关面试题,主要包含被问及说说 JDK1.6 之后的synchronized 关键字底层做了哪些优化,可以详细介绍一下这些优 化吗?时的应答技巧和注意事项,需要的朋友参考一下 JDK1.6 对锁的实现引入了大量的优化,如偏向锁、轻量级锁、自旋锁、适应性自旋锁、锁消除、锁粗化等技术
-
Java:二维数组是以列优先还是行优先的顺序存储的?
问题内容: 在Java中,多维数组是以列优先还是行优先的顺序存储的? 问题答案: Java没有多维数组。它具有数组的数组。例如 …是(当然是)的数组。 因此,Java既不是列优先顺序也不是行优先顺序(但请参见下面的有关如何读取的注意事项),因为给定数组的条目存储在连续的内存块中,而这些条目所指向的从属数组是对象的引用。完全独立的,无关的内存块。这也意味着Java的数组数组固有地呈 锯齿状 :处的条
-
在Java中,当优先级相同时,使优先级队列遵循FIFO顺序
我正在研究一种算法,在该算法中,我希望在从该优先级队列中删除元素时,保持优先级队列中具有相同优先级的元素的FIFO顺序。 虽然,我已经看到了将自动递增的序列号作为辅助键的解决方案,并使用它来打破联系,但我需要类似的链接,但我面临的问题是,我想要比较的元素-TestItemChange(下面示例中的类)没有实现Compariable,我无法(也不想)修改它以使其实现。所以现在,在优先级队列中没有FI
-
深度优先搜索(DFS)与广度优先搜索(BFS)伪码和复杂性
我必须为一个算法开发伪代码,该算法计算给定顶点V和边E的图G=(V,E)中连通分量的数量。 我知道我可以使用深度优先搜索或广度优先搜索来计算连接组件的数量。 但是,我想用最高效的算法来解决这个问题,但是我不确定每个算法的复杂度。 下面是一个用伪代码形式写DFS的尝试。 下面尝试以伪代码形式编写 BFS。 我的讲师说BFS与DFS具有相同的复杂性。 然而,当我搜索深度优先搜索的复杂度时,它是O(V^
-
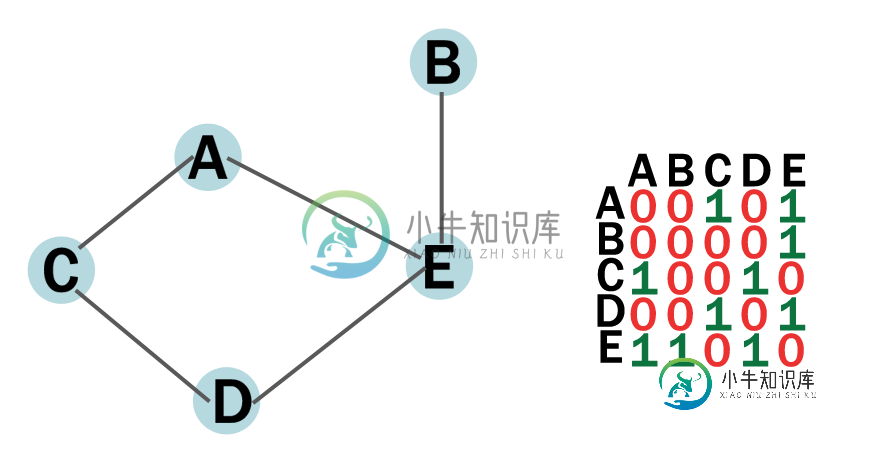 图中两节点之间的深度优先搜索和广度优先搜索
图中两节点之间的深度优先搜索和广度优先搜索我有一个无向连通图。我使用邻接矩阵实现了它,它是一个2维数组。 据我所知,DFS在兄弟节点之前访问子节点。BFS先于孩子探望兄弟姐妹。 这两个我是这样实现的: 如果让我执行一个从D到E的DFS,是D、C、a、E还是D、E。我以为DFS和BFS必须访问每个节点,在这种情况下B不能访问。我不知道我应该如何改变我目前的方法来满足这些要求。
-
我应该使用javac -O选项进行优化吗?
问题内容: 有一个有趣的选择: 通过内联静态,最终和私有方法来优化编译代码。请注意,您的班级可能会变大。 该选项似乎并不流行(隐藏?),我今天才在CodeCup 2014页面 上发现了它。 在官方文档中也没有提及。 在接受类似问题的答案中,我们可以看到: Java中的优化主要由JIT编译器在运行时完成。因此,没有必要试图指示它在编译时优化某种方式(无论如何它仅创建字节码)。JIT几乎肯定会在现场做
-
优化过程中会使用Java内联方法吗?
问题内容: 我想知道JVM / javac是否足够聪明 进入 或在释放情况下剥离对foo()的不必要调用(因为代码无法到达): 对于第一个示例,我的感觉是肯定的,而对于第二个示例,我的感觉“不确定”,但是有人可以给我一些指针/链接来确认这一点吗? 问题答案: 将提供字节码,该字节码是生成该字节码的原始Java程序的忠实表示(在某些可以优化的特定情况下除外: 常量折叠 和 消除死代码 )。但是,当J
-
编译器会优化重复的数学计算吗?
问题内容: Java编译器会优化简单的重复数学运算,例如: 我知道我可以将结果分配给if语句之前的变量,然后返回变量,但这有点麻烦。如果编译器自动识别出正在执行相同的计算,并将结果自己缓存到临时变量中,我宁愿遵守上述约定。 *编辑-我是个白痴。我试图简单/过多地提出我的问题。它不是简单的:if(x> y) 问题答案: 答案是肯定的。这称为“ 公共子表达式消除”,它是Java,C / C ++和其他
-
Android编程开发之性能优化技巧总结
本文向大家介绍Android编程开发之性能优化技巧总结,包括了Android编程开发之性能优化技巧总结的使用技巧和注意事项,需要的朋友参考一下 本文详细总结了Android编程开发之性能优化技巧。分享给大家供大家参考,具体如下: 1.http用gzip压缩,设置连接超时时间和响应超时时间 http请求按照业务需求,分为是否可以缓存和不可缓存,那么在无网络的环境中,仍然通过缓存的httprespon
-
 谈谈Tempdb对SQL Server性能优化有何影响
谈谈Tempdb对SQL Server性能优化有何影响本文向大家介绍谈谈Tempdb对SQL Server性能优化有何影响,包括了谈谈Tempdb对SQL Server性能优化有何影响的使用技巧和注意事项,需要的朋友参考一下 先给大家巩固tempdb的基础知识 简介: tempdb是SQLServer的系统数据库一直都是SQLServer的重要组成部分,用来存储临时对象。可以简单理解tempdb是SQLServer的速写板。应用程序与数据库都可以使用
-
MySQL性能优化:按日期时间字段排序
问题内容: 我有一个表,该表包含大约100.000个博客文章,并通过1:n关系链接到具有50个供稿的表。当我用select语句查询两个表时(按发布表的datetime字段排序),MySQL始终使用文件排序,导致查询时间非常慢(> 1秒)。这是表的架构(简化): 这是桌子: 这是执行时间超过1秒的查询。请注意,该字段具有索引,但MySQL并未使用它对发布表进行排序: 该查询命令的结果表明MySQL正
-
你知道的react性能优化有哪些方法?
本文向大家介绍你知道的react性能优化有哪些方法?相关面试题,主要包含被问及你知道的react性能优化有哪些方法?时的应答技巧和注意事项,需要的朋友参考一下 :Class Component :Function Component :Memoized Function :Memozied Value
-
Java:String concat vs StringBuilder-已优化,所以我该怎么办?
问题内容: 在这个答案中,它表示(暗示)无论如何都将String连接优化到StringBuilder操作中,因此,当我编写代码时,是否有任何理由在源代码中编写StringBuilder代码?请注意,我的用例与OP的问题不同,因为我正在串联/附加数十万行。 为了使自己更清楚:我很清楚每种代码的区别,只是我不知道是否值得实际编写StringBuilder代码,因为它的可读性较低,并且当它的较慢的表亲S
-
这是因为go编译器优化了代码吗?
问题内容: 输出始终为。 但是,绝对可以使循环多次遍历1s 。 我认为,在闭包是在FUNC。 请参见下面的代码。 在多行“ +1”之后,输出正好是预期的很大数目。 问题答案: 记忆模型 2014年5月31日版本 介绍 Go内存模型指定了一种条件,在这种条件下,可以保证在一个goroutine中读取变量可以观察到在不同goroutine中写入同一变量所产生的值。 忠告 修改由多个goroutine同